Something odd is going on. About 2-3
Something odd is going on. About 2-3 weeks ago we started seeing occasional
1006 disconnects from websocket clients. Any ideas why this behavior may have changed?
In an attempt to mitigate we added:
and are using interval to send the ping control frame on the client via:
Previously, without any pings, the client would remain connected for hours. Is this our client's internet connection? Could something have changed on CF platform? How can we mitigate this without having to rely on our reconnection logic? It seems like hibernate is bailing out of on us somehow.38 Replies
My understanding is: although the runtime itself does not disconnect on quiet connections, other parts of the Cloudflare stack might do so. To avoid that, you'd want to either send protocol-level pings, or, if you aren't able to do that (ex. your client is a browser) then you'd use websocket-auto-response (as you're doing), since that will not incur a charge or wake your DO from hibernation.
Thanks buddy. Our client is a browser and we are sending a
wsClient.send('ping') every 25 seconds with setWebSocketAutoResponse() responding on the server.
Any ideas what else can we do to prevent the 1006 disconnects? What is odd for us is that this behavior was not observed for almost a year and only just started about a month ago.
It feels like something tightened or changed on the CF platform. What is challenging here is that the connection in question represents state of a user inside a buddylist, so unexpected disconnects cause the UI state to toggle from online/offline ( and also triggers some on-login logic to the server ).
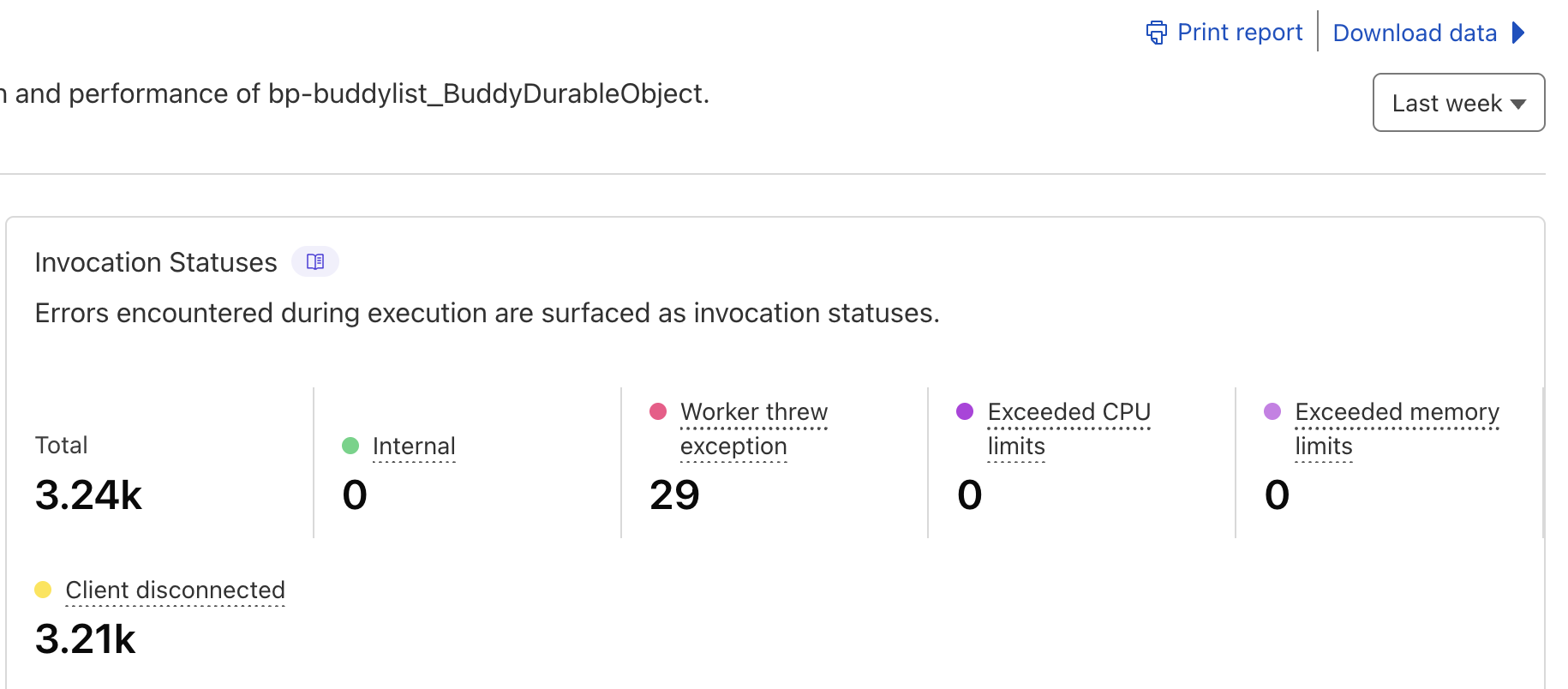
It would be great if we could eliminate the 1006 disconnect by default errors. It's understandable that in normal course of business we see some 1006 happen; however it seems to be the default behavior now happening semi-regularly.
These 1006 errors are a bit frustrating. It's happening for both of our hibernation based durable objects. I'm starting to strongly suspect something changed on the CF platform early August. If that is the case; then I would assume others might be seeing the same issue.@gekkepop. did you ever resolve this? ( from 4 weeks ago ) https://www.answeroverflow.com/m/1403807099619901590
Invalid WebSocket close code: 1006. - Cloudflare Developers
Somehow my websocket closes after 1 minute of inactivity, I don't really understand why, since I am letting the durable object hibernate and this should NOT close the websocket. Any ideas what I am doing wrong?
More of my error:
message: "Invalid WebSocket close code: 1006.", exception: { stack: " at WebSocketHibernationSe...
Unknown User•2mo ago
Message Not Public
Sign In & Join Server To View
I don't believe we have seen this issue happening locally; however we are running an older version of wrangler
3.99.0. Are you seeing this happening locally?Unknown User•2mo ago
Message Not Public
Sign In & Join Server To View
@Peps or @Milan - Sorry to ping you. Are you at all able to get insight to an increase of
1006 websocket disconnects on the CF side in the past month? We are seeing consistent 1006 disconnects in production for all users across all services. Issue started at the beginning of August. Thank you!I flagged this internally earlier today, will let you know if I hear back. We don't track metrics like rate of 1006 client disconnects as those are highly dependent on terminal client application code/networks.
Thank you @Milan. I appreciate this and am grateful you have flagged the issue. It would be amazing if we can figure out a solution. I will continue to investigate on our end.
Any chance you have graphs, btw?
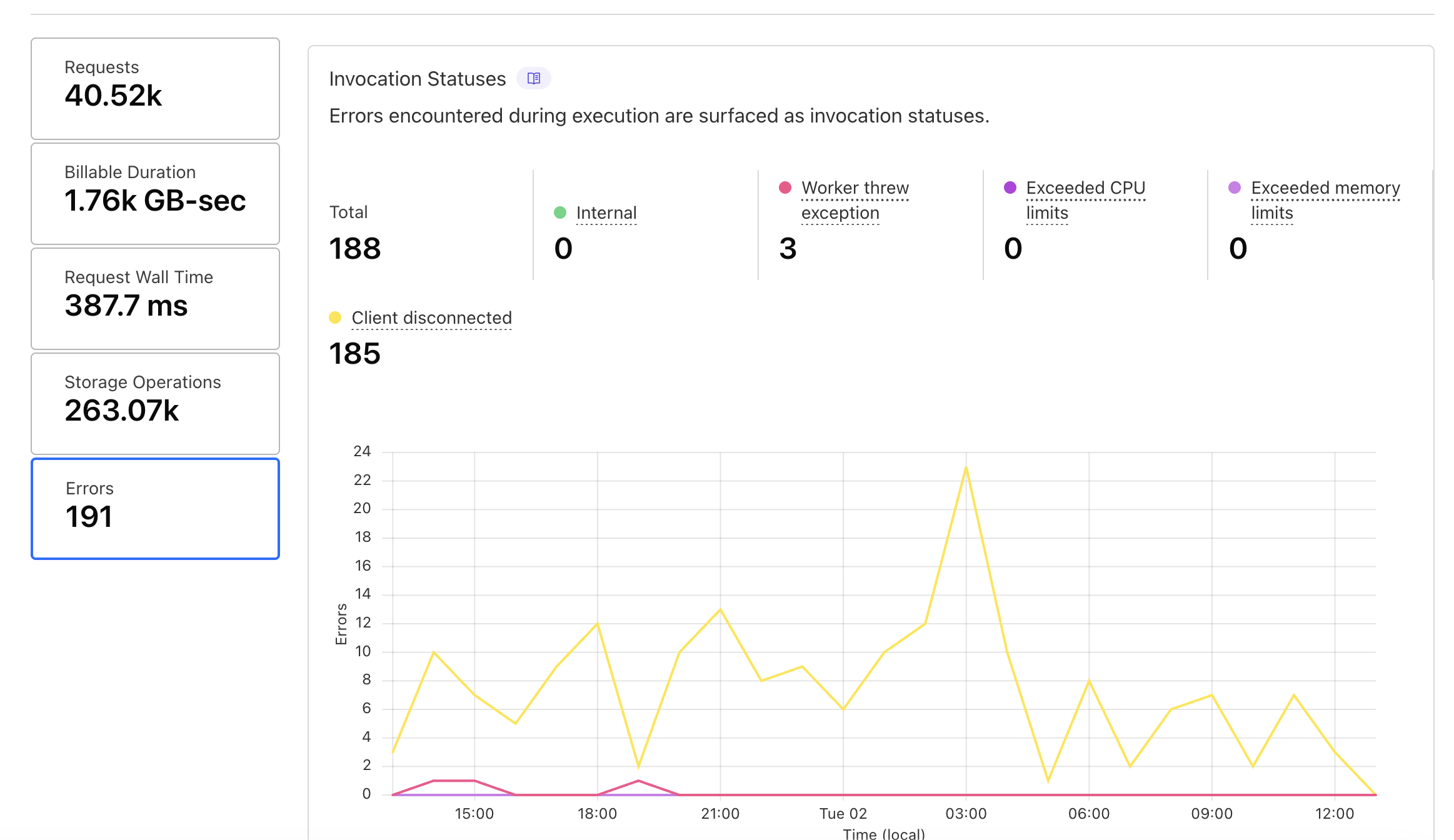
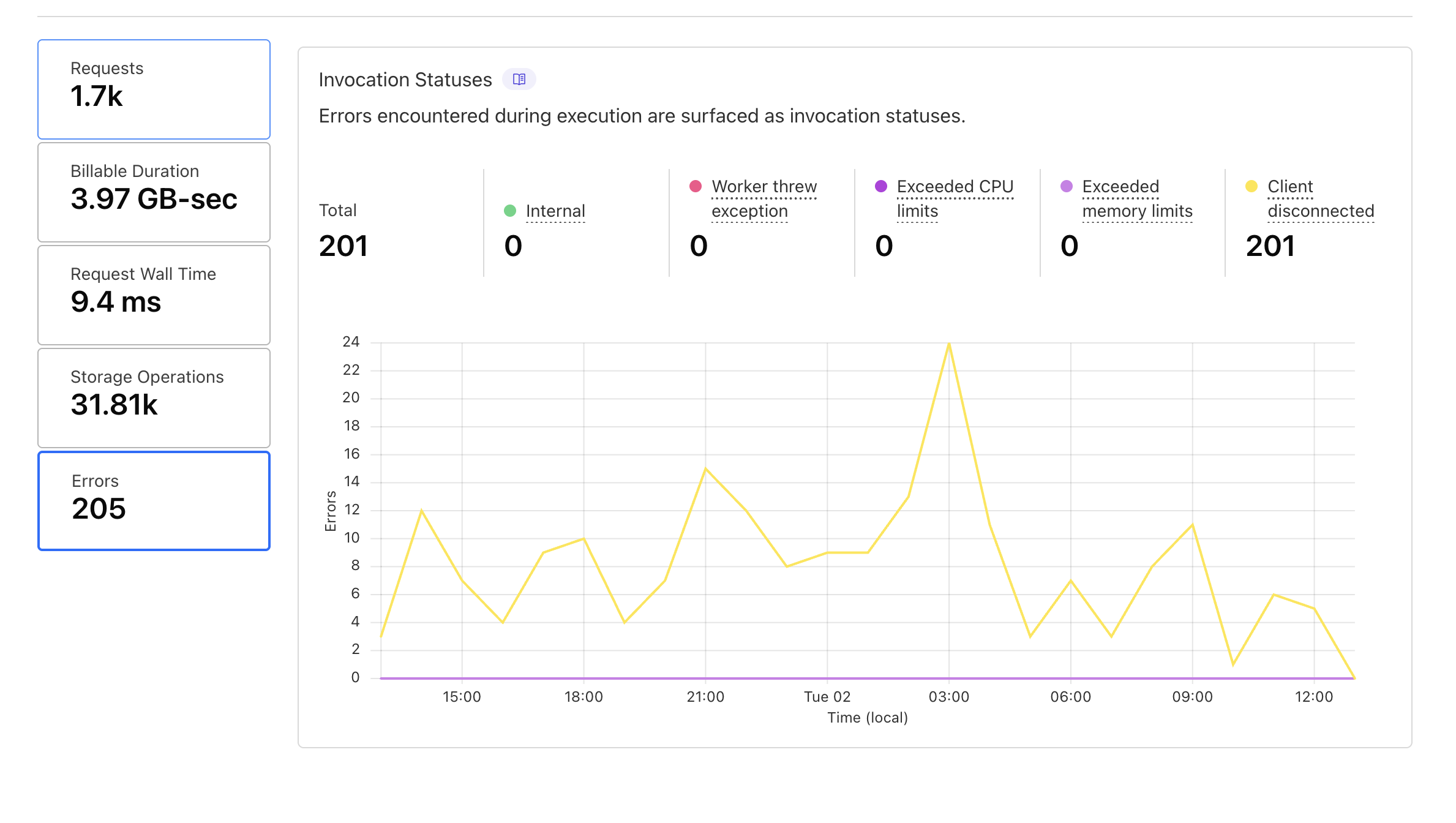
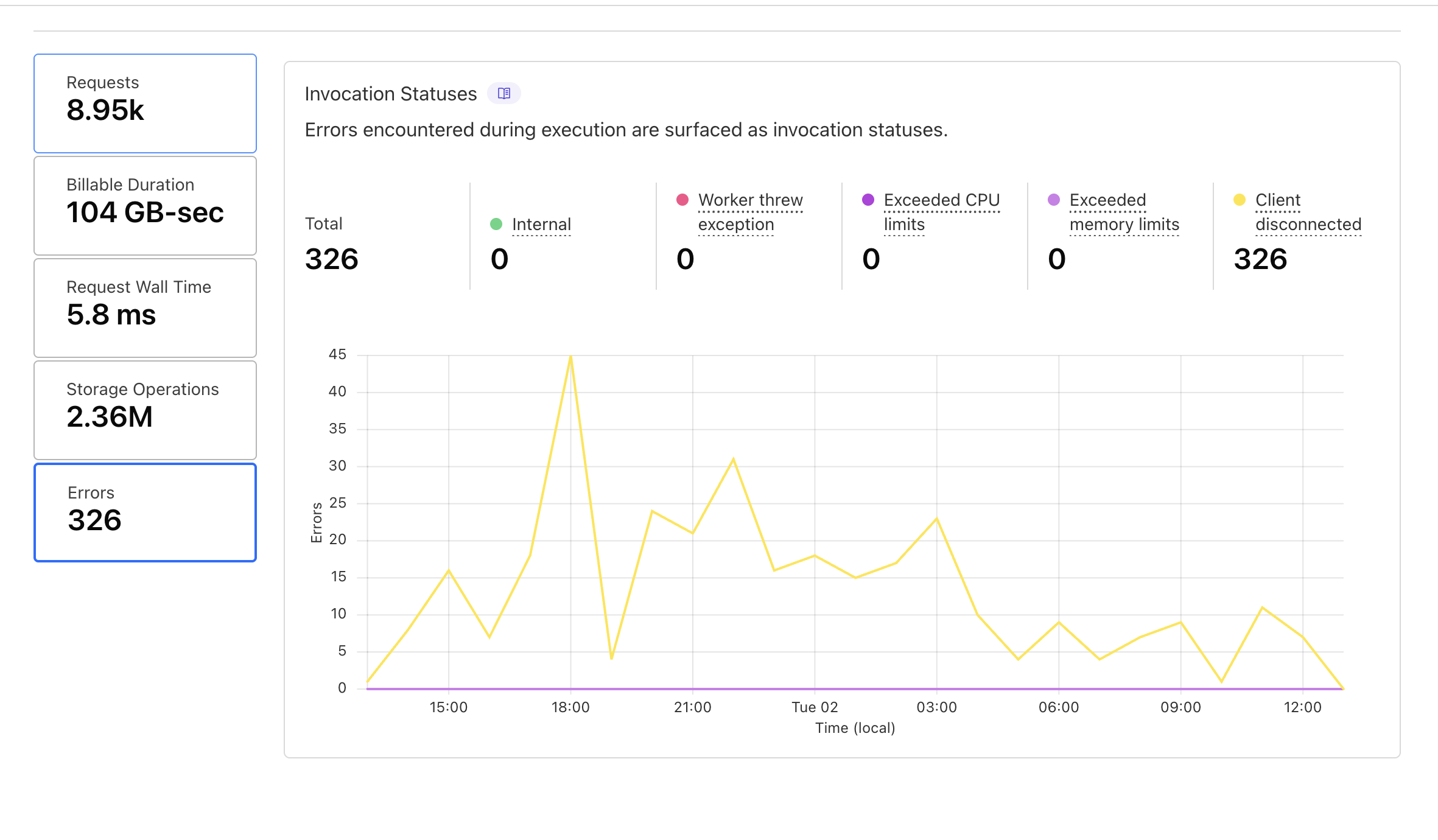
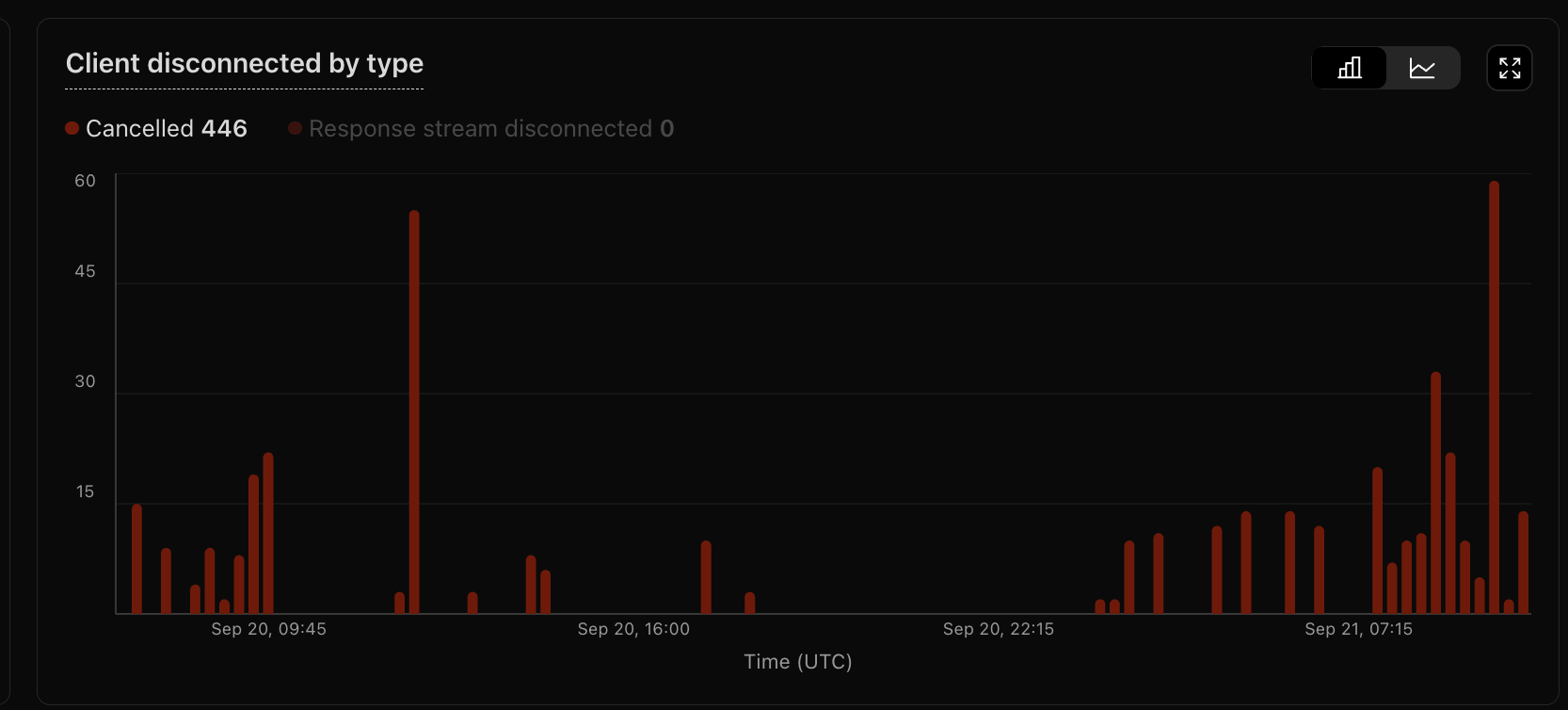
Yes @Milan ^^ these show the client disconnects over the past (24) hours across three of the affected services.
Please let me know any additional information I can provide.
Are you able to zoom out to a month? Would help to get a sense for how much more often you're seeing disconnects now vs. a month back. Would also help to know if this is truly across all clients or just a subset of clients with more spotty network
I think the CF Dashboard UI here only allows to go back 1 week.
From observation it seems like the issue is affecting all clients, some more frequently than others. I first observed this happening on my home internet connection, which should be relatively stable.
We were able to initially detect the issue since our apps UI started to frequently toggle the online / offline status of our users ( it's a buddylist ). From that observation I further investigated the server and client logs and saw the new
1006 errors happening, which was not happening previous to August 1st~.
I'm confident the issue only started last month. I've been deeply looking into any potential client or server changes that may have caused this, coming up short. Those code paths were relatively untouched and it's happening across three separate WS code paths.
Prior to August 1st we saw more or less 0 errors in the dashboard. I frequently check the dashboards for any potential issues / billing durations.
We can move to DMs if you want to, but what plan are you on?
Like, free plan?
We are on the Workers Paid plan, incurring some additional charges each month. Currently billing is low, we are a startup currently growing.
Yeah sure no worries, sorry I should have also specified I'm not asking bc I'm deciding what level of support to give, I'm asking because the runtime might work differently across diff plans (not necessarily because of priority, could just be bugs due to implementing DO free tier, etc)
But just to be clear, paid plan is not enterprise, right?
No, we are not on the business plan or enterprise plan. I am planning to upgrade to business plan by end of year.
I asked around some more and it sounds like we don't think there were any changes to the runtime, but that doesn't mean there weren't changes to other parts of the CF stack. I think what we'd need to do here is get a repro for a CF engineer to mess around with
I can try to put something together some time this week, not sure when I'll have time but will try to make it work. Do you have any data on how long before the DO thinks the client disconnected? Are we talking 1 minute, 1 hour? Longer?
That makes sense. Thank you @Milan. I will continue to investigate here, gather more intel. If we can't find a solution I will make a minimal reproduction. Let's see if anyone else reports the same issue. As a stop-gap I've added logic to app to better handle
1006 connection errors that immediately reconnect.that doesn't mean there weren't changes to other parts of the CF stackWe're asking other teams too just to see if we can short cut all the repro stuff, I'll update here if I hear anything conclusive. As always, thanks for the report 🙏 , it feels like you stumbled onto a real problem here.
The overall time feels over 1 minute, looking at the logs it seems closer to 30 minute intervals that disconnects happen.
Sorry for the ping but @Larry or @1984 Ford Laser have either of you experienced this? I ask because after talking with some other internal teams we still haven't identified any change on our end that might have caused this. Would be helpful to hear if this is more wide-spread, given it's happening to 3 of @Marak's DO deployments I imagine it's likely others might notice it as well.
I am not sure we would notice. We already reconnect and we don’t have any logging that tracks how often. Reconnecting is on the happy path for us.
I think adjusting our application code to make reconnection a happier path is wise. It's slightly challenging since we have the concept of "online" and "offline" status that propagates through the system, but not insurmountable. A small timing buffer should work. Reconnections are expected in the normal course of business. What caught us off guard was the sudden spike in abnormal
1006 client disconnects.
If you check the durable object dashboard UI you can track the client disconnect errors FYI.Nah haven't seen anything like this but I dont use websockets super extensively at the moment. If you can figure reconnecting into the workflow that would work well
Sorry for the super late response, but I solved my problem by basically sending a keep alive message every 30 sec, this stopped the websocket from closing after 60 sec.
We've been seeing this too. For us, we observe it locally with
wrangler dev but not in deployed workers. We have this architecture: [client] -> [api gateway worker] -> [entrypoint of another worker] -> [hibernating websocket durable object]. It doesn't happen if we skip the api gateway worker.using an application level ping ( like sending a custom ping message with a specific handler ) or using
setWebSocketAutoResponse?
We had some suspicions the issue could be related to api gateway routing. We aren't using an api gateway worker directly, but we are using the routing options for worker, which may be a gateway behind the scenes. Thanks for the info. I will attempt updating the client to speak directly with the worker route and see if that makes any difference.This sounds like a promising lead. I can imagine how the API gateway would get in the way. The whole proxy through a worker to get a websocket is under-the-covers magic. It makes sense that Cloudflare wouldn't have engineered for as much nor tested as thoroughly with a gateway in the mix. Milan, what do you think?
This also explains why we have data from some folks that say it hasn't happened to them. Their connections might be more canonical.
After a day of testing it didn't seem to make a difference. I'm running out of ideas. It seems we have to live with the abnormal amount of client disconnections for the time being.
I'm sad this thread has died. I believe we need either more evidence that nothing has changed to have caused what @Marak experienced or reassurance that Cloudflare is still investigating. The evidence that was posted by a practitioner could have been enough of a different context from @Marak 's to not be definitive.
I will circle back around to this before end of year. We are still seeing the spike in client disconnects, I have hardened our code paths around reconnections to mitigate the issue.
We've had to prioritize other development tasks for the moment. I will update this thread when I have new information or we see any change in behavior.
I'm hoping the issue just goes away, or perhaps other improvements in our backend magically alleviates the issue ( doubtful but hopeful ).
I'm experiencing something odd too, with cloudflare queues - which presumably is built on top of the durable objects.
Queues is built on DOs but I don't believe it uses WebSockets. I could be wrong.