Unable to scrape and extract data. Starts to Parallelise then nothing happens
9 Replies
I messaged the AI on the website and it passed it to a human, but its Sunday in most of the world (Monday here in NZ) and I'd like to get this resolved today
nothing shows in Activity Logs, I'm at 0/5 active concurrent browsers
Can you try again? We fixed a bug this morning that was likely causing this.
Just kicked off a new extract process so will see how it goes
@micah.stairs I tried agian, nothing happened, cant even see the attempt in the extract overview, jus tthe previous failed attemps with empty files
Hmm, so if you want more reliable (and cheaper) extract-like functionality, you should check out our JSON scraping mode, which is supported by endpoints like /scrape and /crawl. You can also pair that with custom actions, which is a powerful combo! Would this work for your use case?
hey @VENGEΛNCE
this seems to be working fine
I spotted couple of issues in your setup
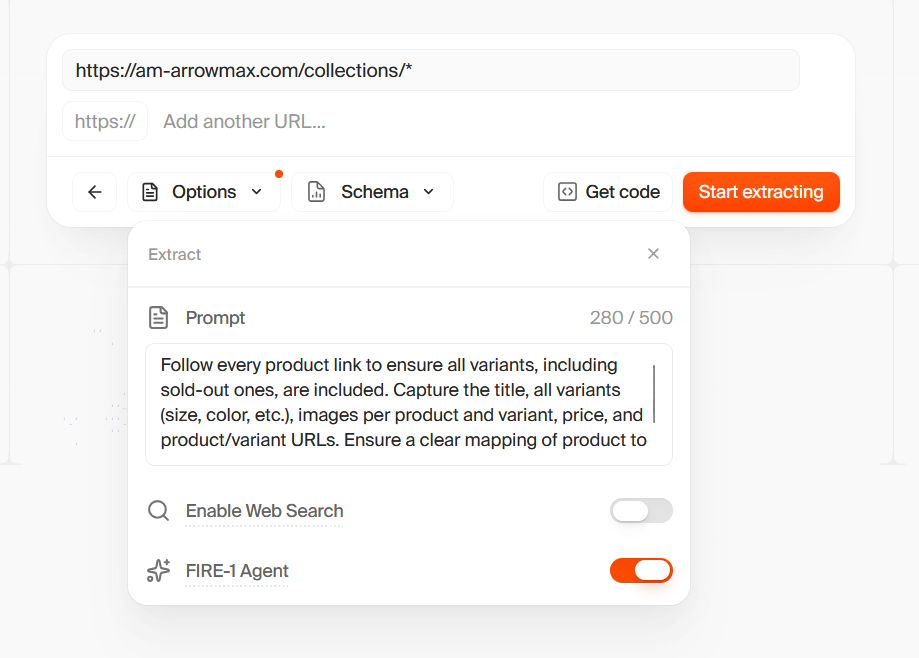
1. You have included
https:// when adding URL, please remove it
2. Your prompt doesnt seem right, ex: you have included variants twice
Make sure your prompt is simple and easy to parse for the parameters
attaching a screenshot for your reference
let me know if you have any further issues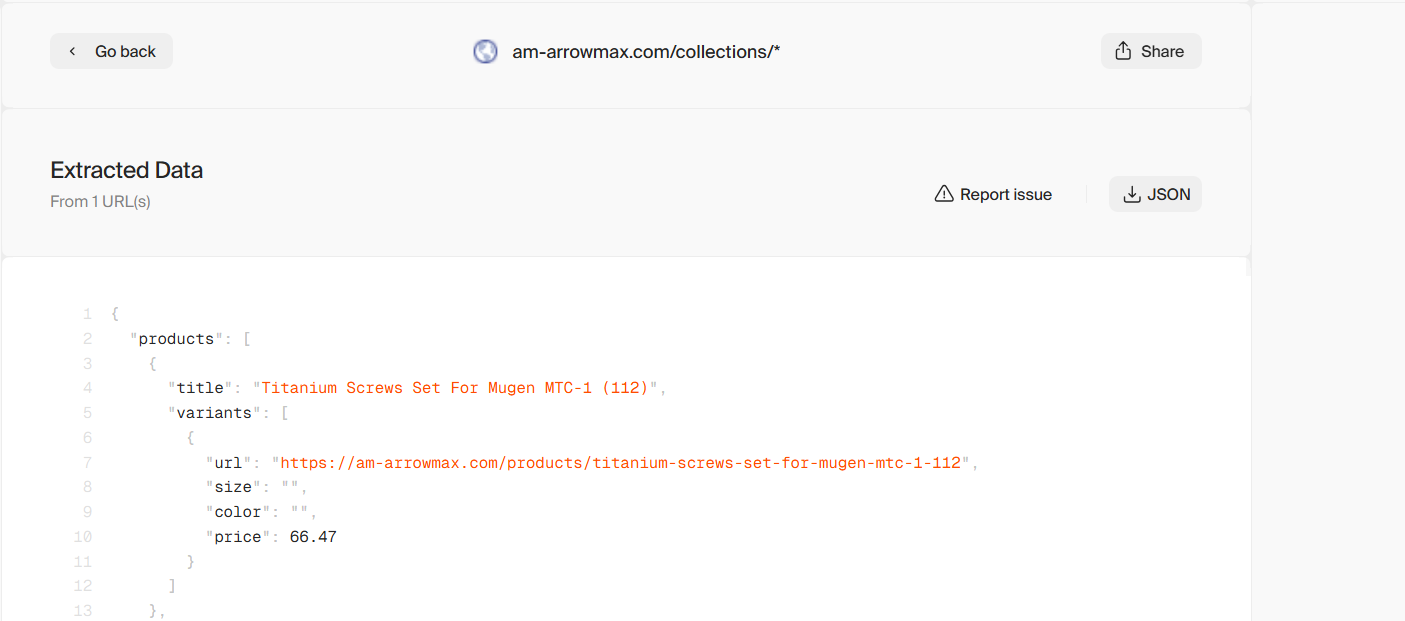
@micah.stairs
The team might consider adding/improving these
1. The URL for sharing is too long, can we shorten it?
2. Can we add the prompt/schema that was used for a run (under recent runs)
Those are good idea! I just passed along those feature requests to the team. I will send a message here if we end up implementing either of those.
sweet!
The prompt and schema is now included in the activity logs!
And the playground links should now be shorter!