scrape - json mode
I am trying to migrate from the cloud version to the self hosted version. The scrape - json format mode was working fine in the cloud based firecrawl api call. However, when I tried the self hosted version, its showing this error
The self hosted version is working fine for normal scraping, also I have provided the openai key through the env
10 Replies
am using scrape - json mode
Hi @Nalaso your script is incorrect, here's a fixed simple curl version of it you can try to test.
this will work, also, please note: you'll need to use a real url.
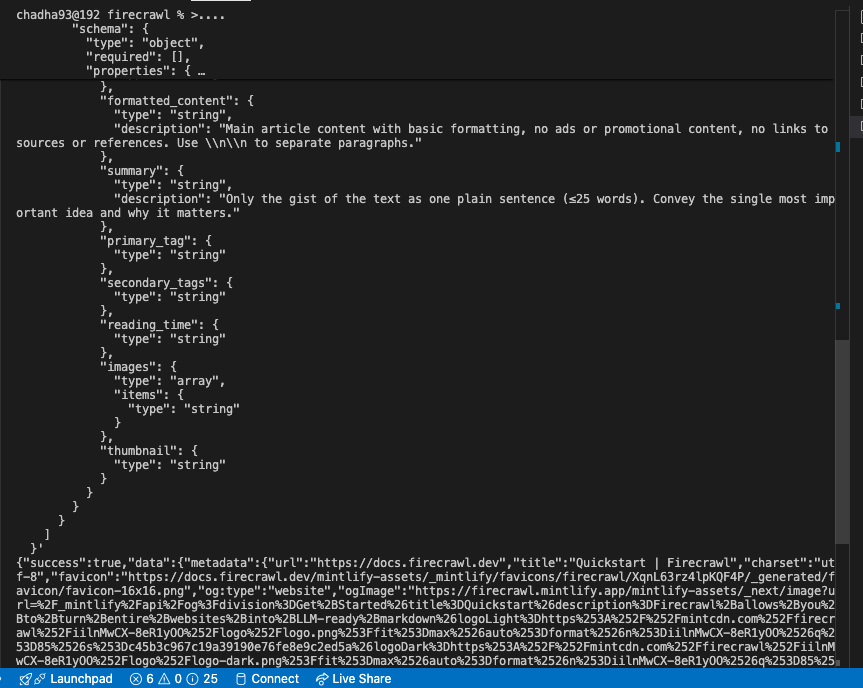
@Gaurav Chadha From your screenshot i could only see data.metadata. Can you confirm if data.json is present in the response?
can you try with some techcrunch article url?
@Nalaso in v2, when using structured extraction with formats, the response structure typically looks like this:
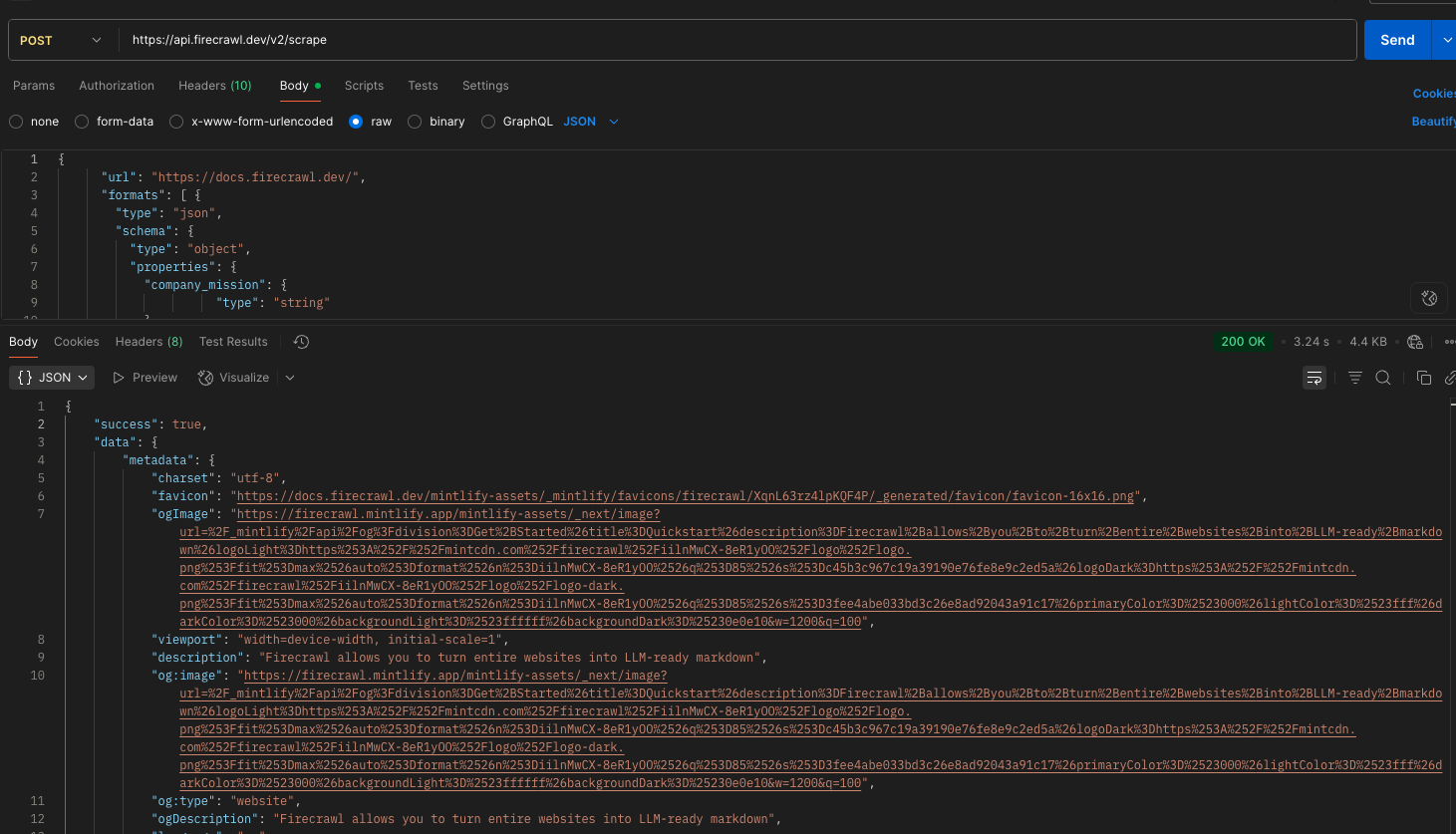
@Gaurav Chadha Thanks for the quick reply
Am referring to this one - https://docs.firecrawl.dev/features/llm-extract
Also its data.json not data.data
I think if llm extraction fails then response is returned success: true and without data.json
right, I see now, let me check and verify
@Nalaso in the
.env can you add these two below OPEN_API_KEY
OPENAI_BASE_URL=https://api.openai.com/v1
MODEL_NAME=gpt-4o-mini
and then restart the container? The above issue is due to missing baseurl and model@Gaurav Chadha Thank you so much
This worked