Scraping site for logged-in users
can it scrape sites that require users to be logged in? Specifically, does Firecrawl support cookie-based sessions (or other session/auth replay methods)? If so, please describe how to provide cookies/session tokens, handle CSRF, and any limits or best practices (session rotation, rate limits, anti-bot handling). Thanks!
1 Reply
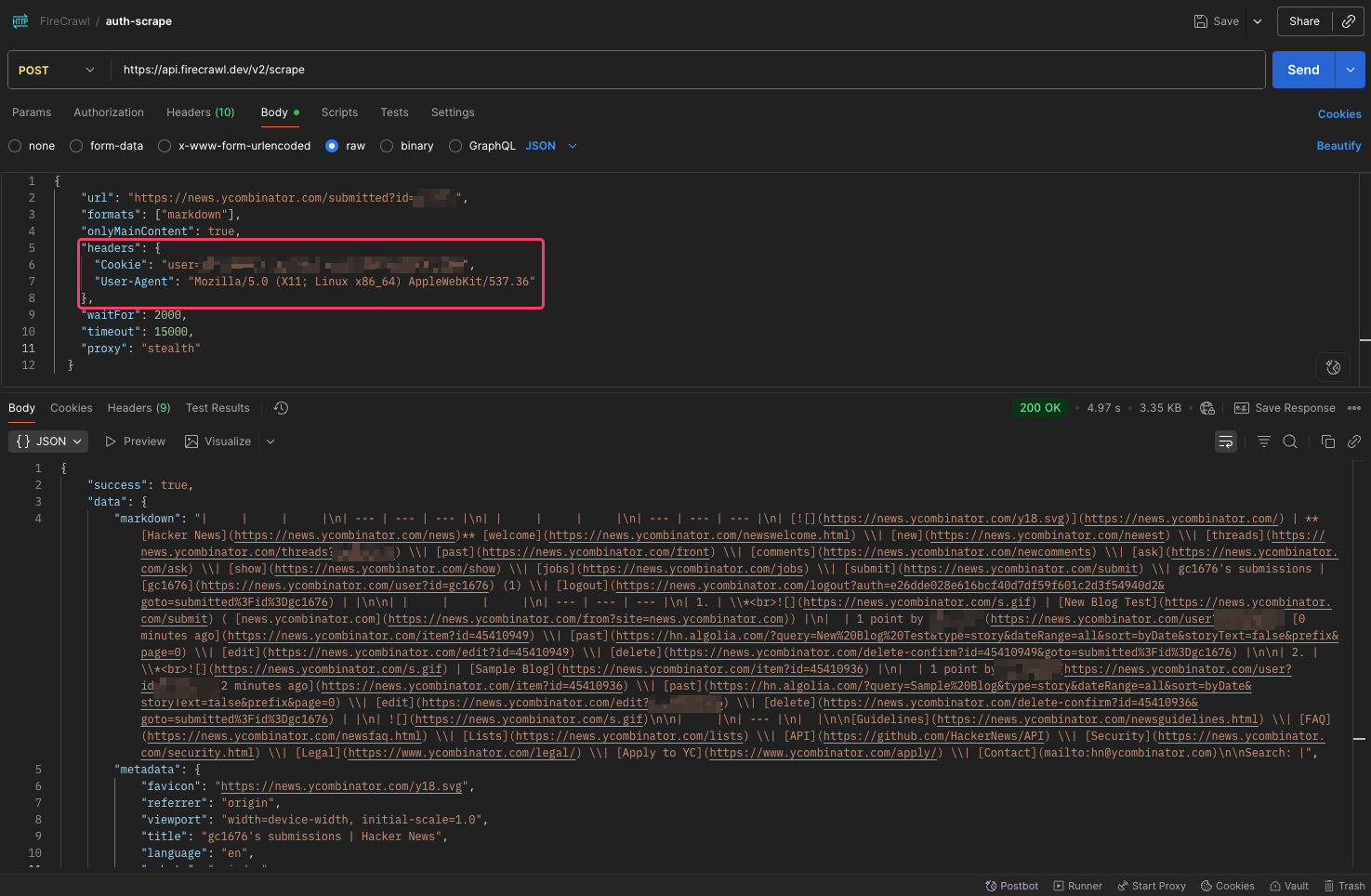
@Rakesh yeah, you can provide the Cookie within the headers, to achieve this, and use the and use the
stealth proxy avoid anti-bot and rate limiting firewalls.
curl --request POST "https://api.firecrawl.dev/v2/scrape" \
--header "Authorization: Bearer YOUR_FIRECRAWL_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"url": "https://news.ycombinator.com/submitted?id=YOUR_USERNAME",
"formats": ["markdown"],
"onlyMainContent": true,
"headers": {
"Cookie": "user=YOUR_HN_COOKIE",
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36"
},
"waitFor": 2000,
"timeout": 15000,
"proxy": "stealth"
}'