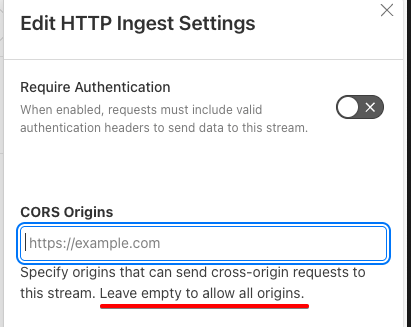
Not sure if this is disconnect in what
Not sure if this is disconnect in what the interface says and what the intended behaviour is, but when viewing streams, the UI says: "Specify origins that can send cross-origin requests to this stream. Leave empty to allow all origins."
But if I leave that blank, I get console errors indicating CORS errors.
Is there no way to have wildcards for CORS headers?
But if I leave that blank, I get console errors indicating CORS errors.
Is there no way to have wildcards for CORS headers?