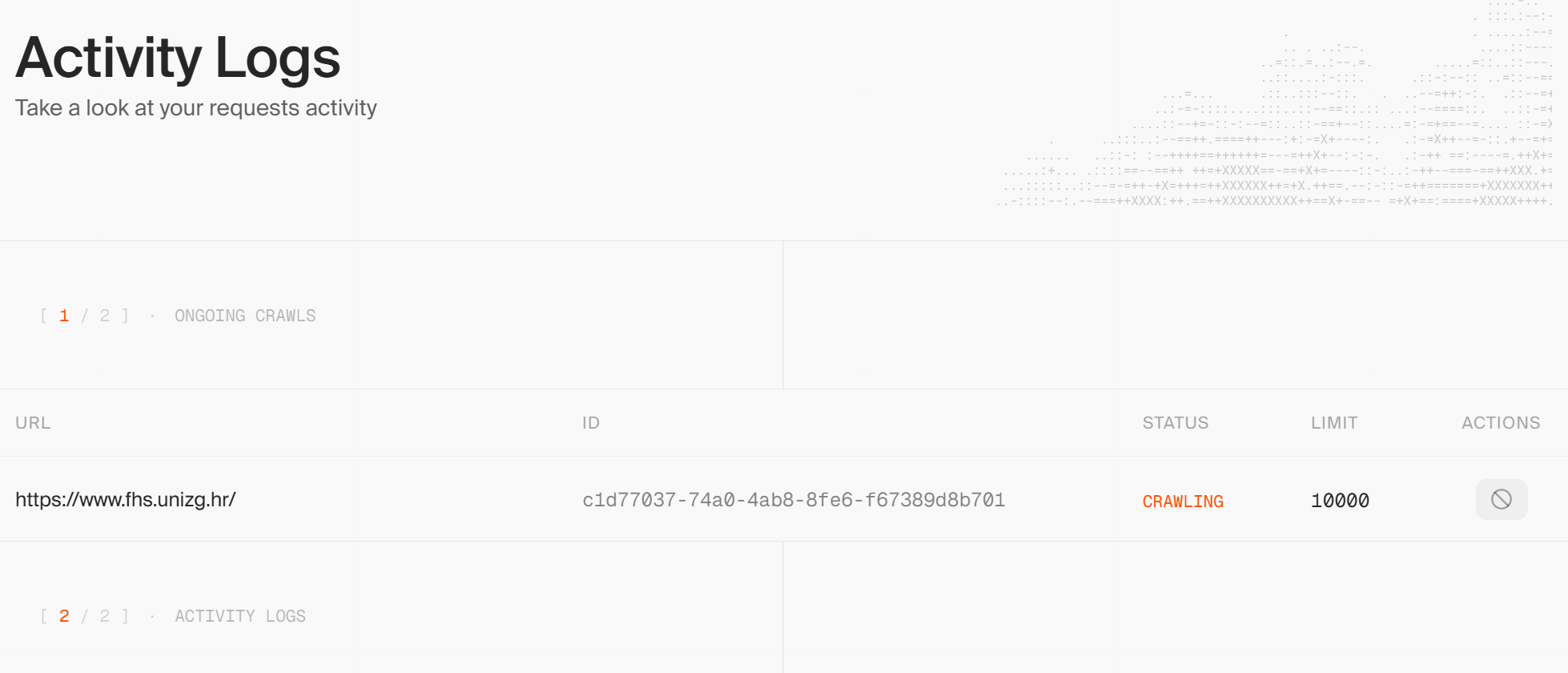
Crawl job not stopping and also the token usage has not been changed for quite some time
The code:
import requests
import time
import os
import re
from dotenv import load_dotenv
load_dotenv()
FIRE_CRAWL_API_KEY = os.getenv("FIRE_CRAWL_API_KEY")
JOB_STATUS_URL = "https://api.firecrawl.dev/v2/crawl/status/"
OUTPUT_DIR = "crawleddata"
"url": "https://www.fhs.unizg.hr/",
"sitemap": "include",
"crawlEntireDomain": True,
"excludePaths": [
"./en/.",
".*news.",
".news.*"
],
"scrapeOptions": {
"onlyMainContent": True,
"maxAge": 172800000,
"parsers": [
"pdf"
],
"formats": [
"markdown"
]
}
}
headers = {
"Authorization": f"Bearer {FIRE_CRAWL_API_KEY}",
"Content-Type": "application/json"
}
response = requests.post(CRAWL_URL, json=payload, headers=headers)
import requests
import time
import os
import re
from dotenv import load_dotenv
load_dotenv()
FIRE_CRAWL_API_KEY = os.getenv("FIRE_CRAWL_API_KEY")
CONFIGURATION
CRAWL_URL = "https://api.firecrawl.dev/v2/crawl"JOB_STATUS_URL = "https://api.firecrawl.dev/v2/crawl/status/"
OUTPUT_DIR = "crawleddata"
Crawl job parameters
payload = {"url": "https://www.fhs.unizg.hr/",
"sitemap": "include",
"crawlEntireDomain": True,
"excludePaths": [
"./en/.",
".*news.",
".news.*"
],
"scrapeOptions": {
"onlyMainContent": True,
"maxAge": 172800000,
"parsers": [
"pdf"
],
"formats": [
"markdown"
]
}
}
headers = {
"Authorization": f"Bearer {FIRE_CRAWL_API_KEY}",
"Content-Type": "application/json"
}
START THE CRAWL JOB
print("Starting crawl job...")response = requests.post(CRAWL_URL, json=payload, headers=headers)