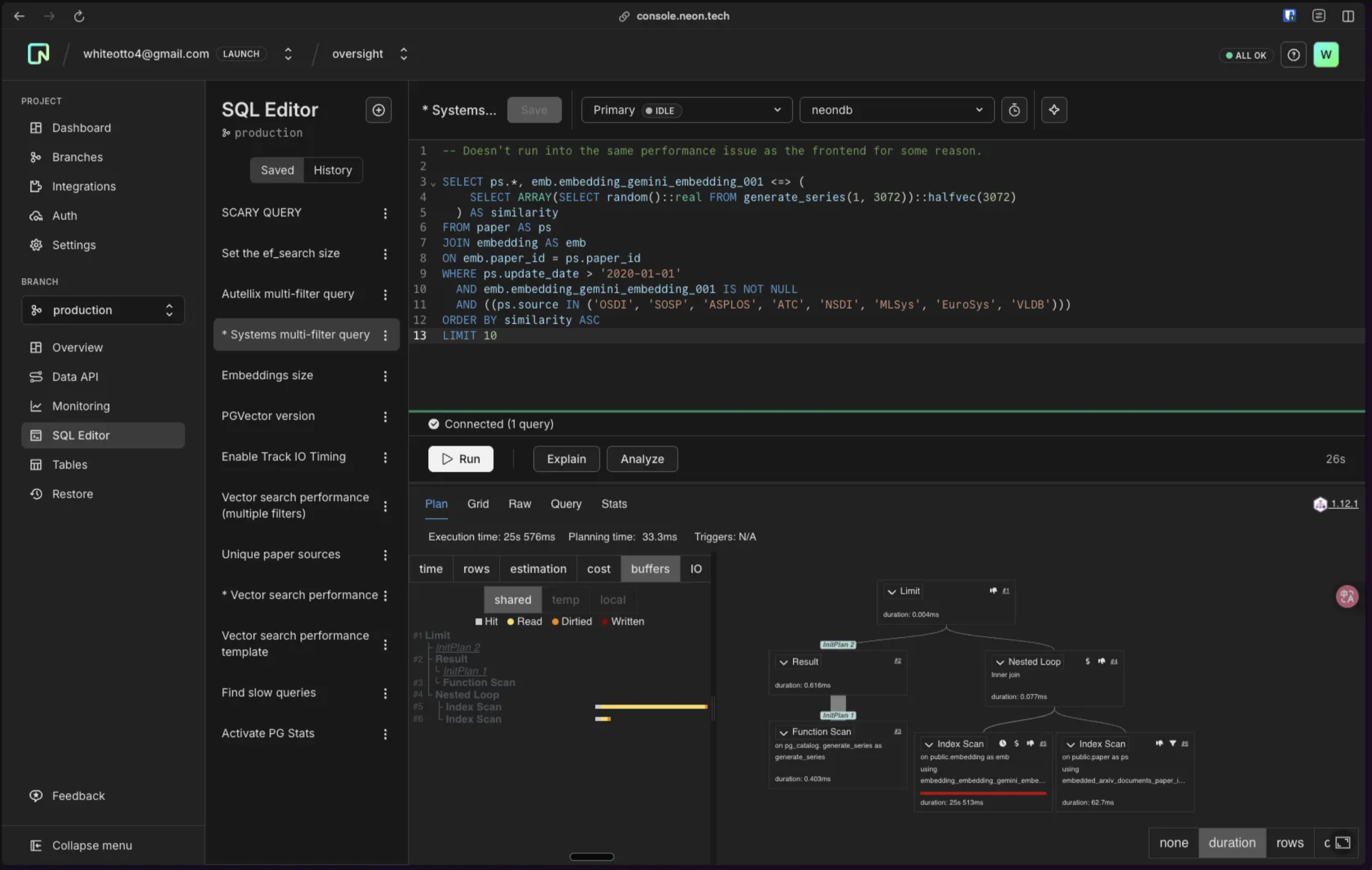
Extremely slow vector nearest neighbour query (~30sec-2min) on cold database
I have roughly ~1 million 3072 dimension halfvecs in an embedding table, with a HNSW index.
When I perform a similarity-based query on the table, if the database is cold (scaled to zero for long enough for any caches to clear out), the query can take between 30 seconds to 2 minutes. I have verified that the index is being hit through running the query in the EXPLAIN ANALYSE view in the NeonDB console. The initial cold query is extremely slow. The subsequent query runs are very fast, but all the metrics in the EXPLAIN ANALYSE view (except time on the index scan) remain extremely similar.
The database cold start itself is not the problem, as to wake the database, I run a simple query that gets the version of an extension, which takes less than a second.
I'm using the pgvector extension and postgres 17. I'm also on the NeonDB launch plan.
Any help would be much appreciated, been debugging this for ages now. See some screenshots and details below
Query:
When I perform a similarity-based query on the table, if the database is cold (scaled to zero for long enough for any caches to clear out), the query can take between 30 seconds to 2 minutes. I have verified that the index is being hit through running the query in the EXPLAIN ANALYSE view in the NeonDB console. The initial cold query is extremely slow. The subsequent query runs are very fast, but all the metrics in the EXPLAIN ANALYSE view (except time on the index scan) remain extremely similar.
The database cold start itself is not the problem, as to wake the database, I run a simple query that gets the version of an extension, which takes less than a second.
I'm using the pgvector extension and postgres 17. I'm also on the NeonDB launch plan.
Any help would be much appreciated, been debugging this for ages now. See some screenshots and details below
Query: