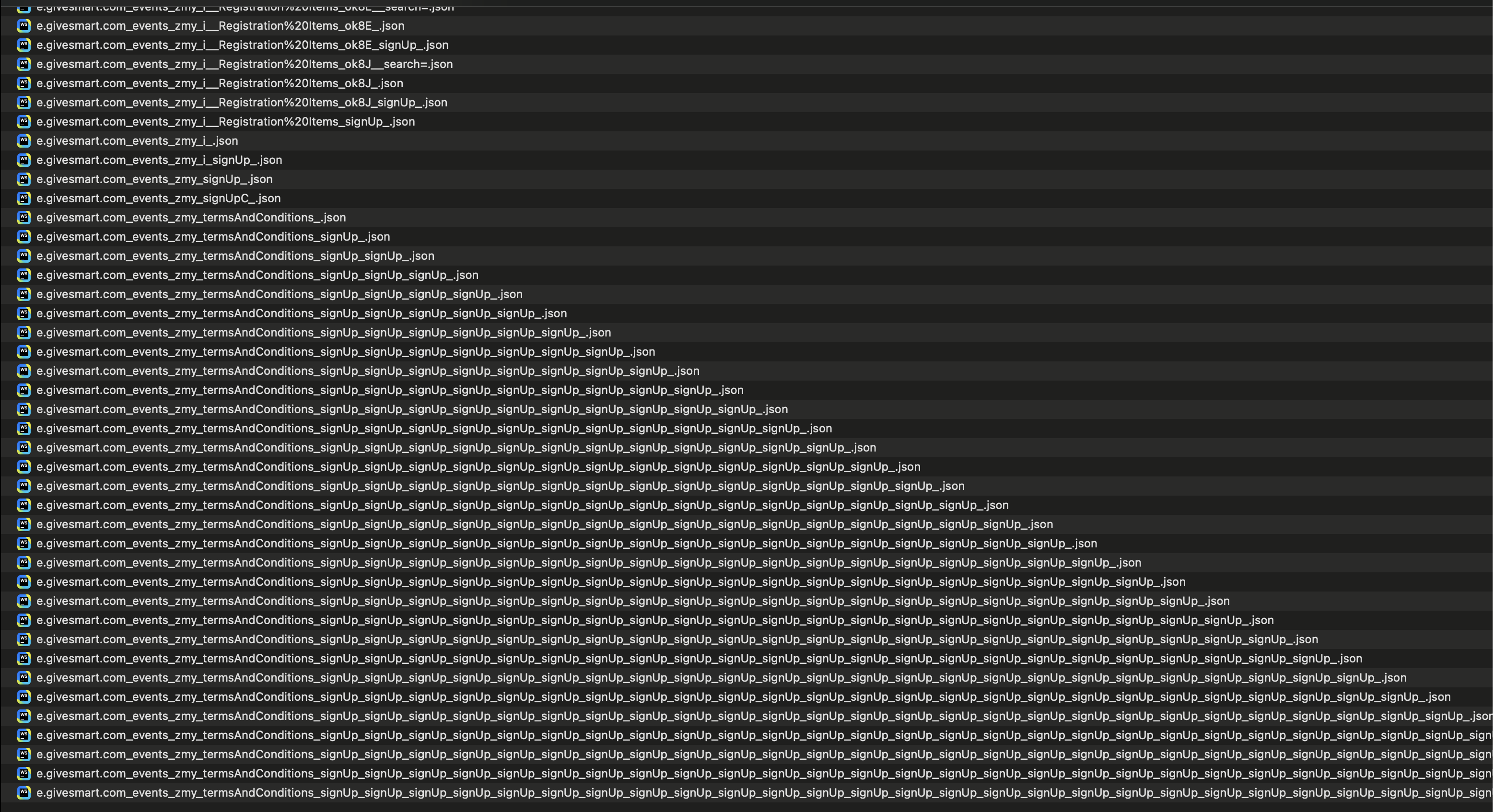
I am running crawls on pages and am not getting results (crawls are stuck)
bugapi
When I encounter a "Coming Soon" page (https://e.givesmart.com/events/imz/) the crawl works (and correctly does not give me any data back)
but when I encounter a page I actually want to crawl and scrape (https://e.givesmart.com/events/hr0/) it just sits and does not scrape any data.
Heres 4 jobs that are crawling that are not giving me any data back and seem to be stuck:
1. 019b1d84-6bc9-77aa-8083-f07dbb081bbc
2. 019b1d8d-bfd0-71fe-a885-9a2091b0674b
3. 019b1d8e-4988-7790-9cc3-664909a4ff85
4. 019b1d8f-bc07-77bb-b240-6e9120233ee5
Any idea what is going on here? Maybe something to do with my JSON schema?
When I try and run just /scrape with the same schema I don't get back any structured data, just the metadata (for example: 019b1d94-8a69-748c-960c-f13ca230d09a)
but when I encounter a page I actually want to crawl and scrape (https://e.givesmart.com/events/hr0/) it just sits and does not scrape any data.
Heres 4 jobs that are crawling that are not giving me any data back and seem to be stuck:
1. 019b1d84-6bc9-77aa-8083-f07dbb081bbc
2. 019b1d8d-bfd0-71fe-a885-9a2091b0674b
3. 019b1d8e-4988-7790-9cc3-664909a4ff85
4. 019b1d8f-bc07-77bb-b240-6e9120233ee5
Any idea what is going on here? Maybe something to do with my JSON schema?
When I try and run just /scrape with the same schema I don't get back any structured data, just the metadata (for example: 019b1d94-8a69-748c-960c-f13ca230d09a)