Firecrawl
Join builders, developers, users and turn any website into LLM-ready data, enabling developers to power their AI applications with clean, structured information crawled from the web.
JoinFirecrawl
Join builders, developers, users and turn any website into LLM-ready data, enabling developers to power their AI applications with clean, structured information crawled from the web.
JoinCrawlling job got stuck and never returned
Images in PDF
Check if a specific subpage exists using Firecrawl?
scrape via api
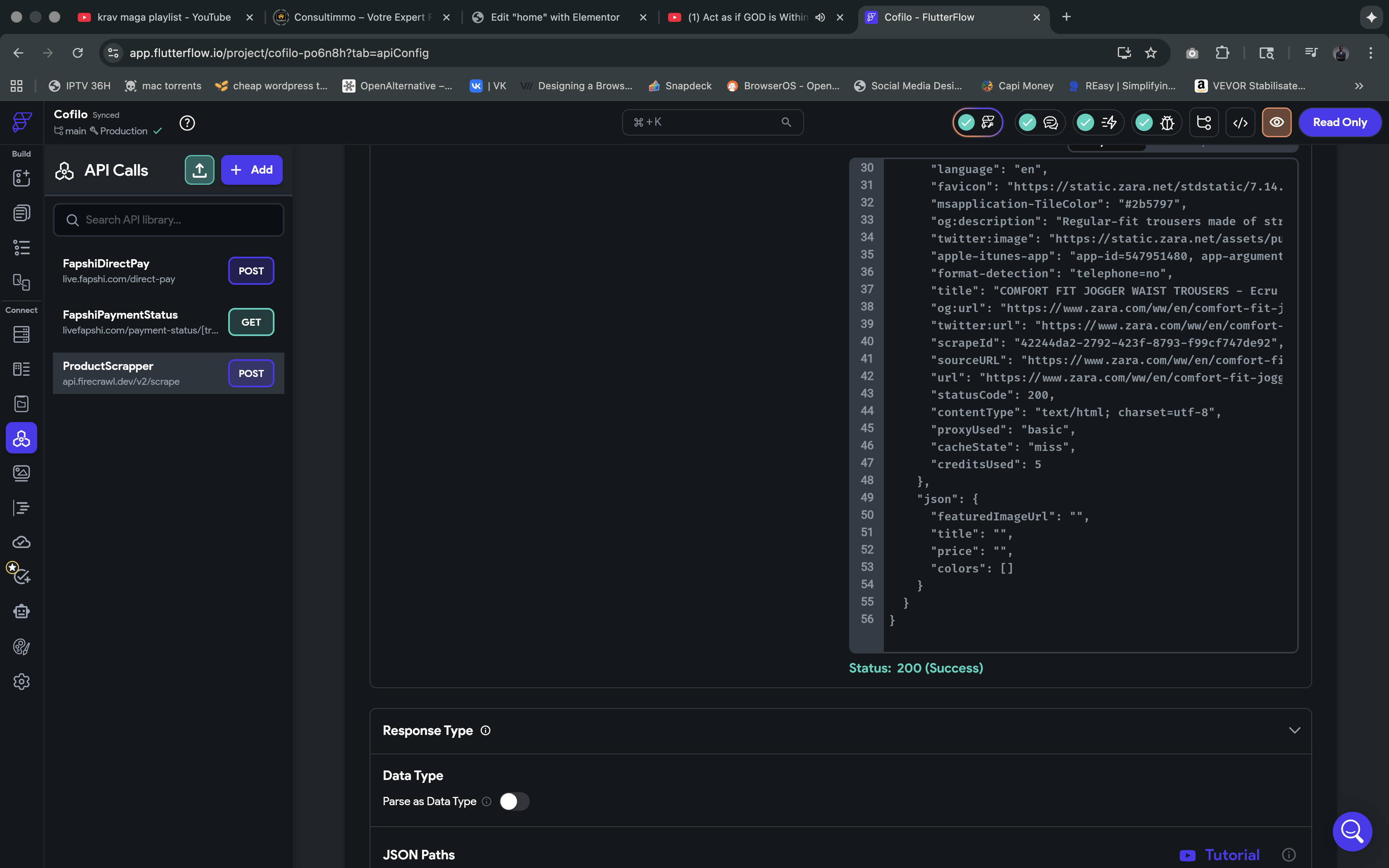
Crawlling pdf page does not retrieve entire content
How can I retrieve the crawl result of previous job?
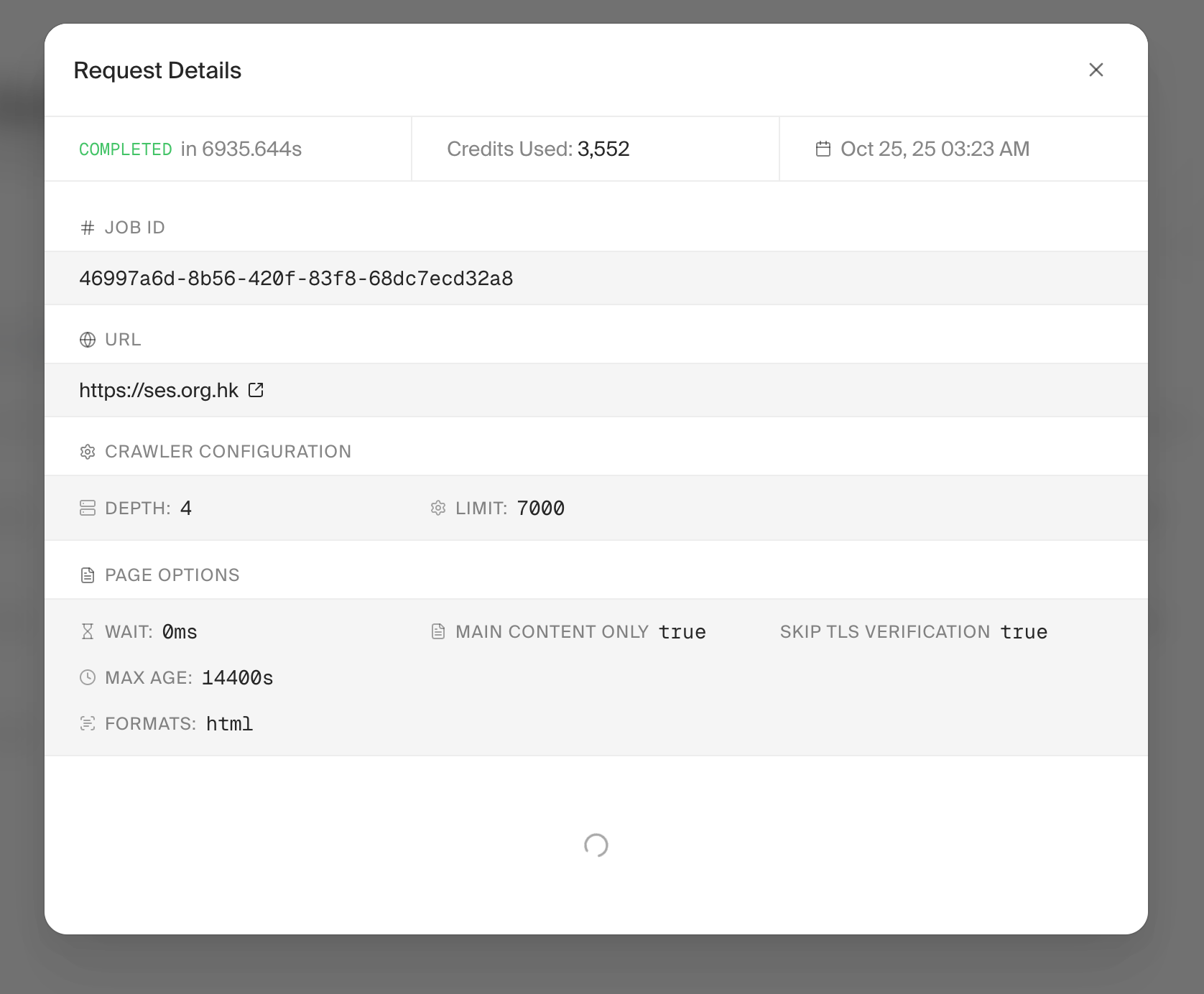
Can I do this?
Need custom solution - who can help for $?
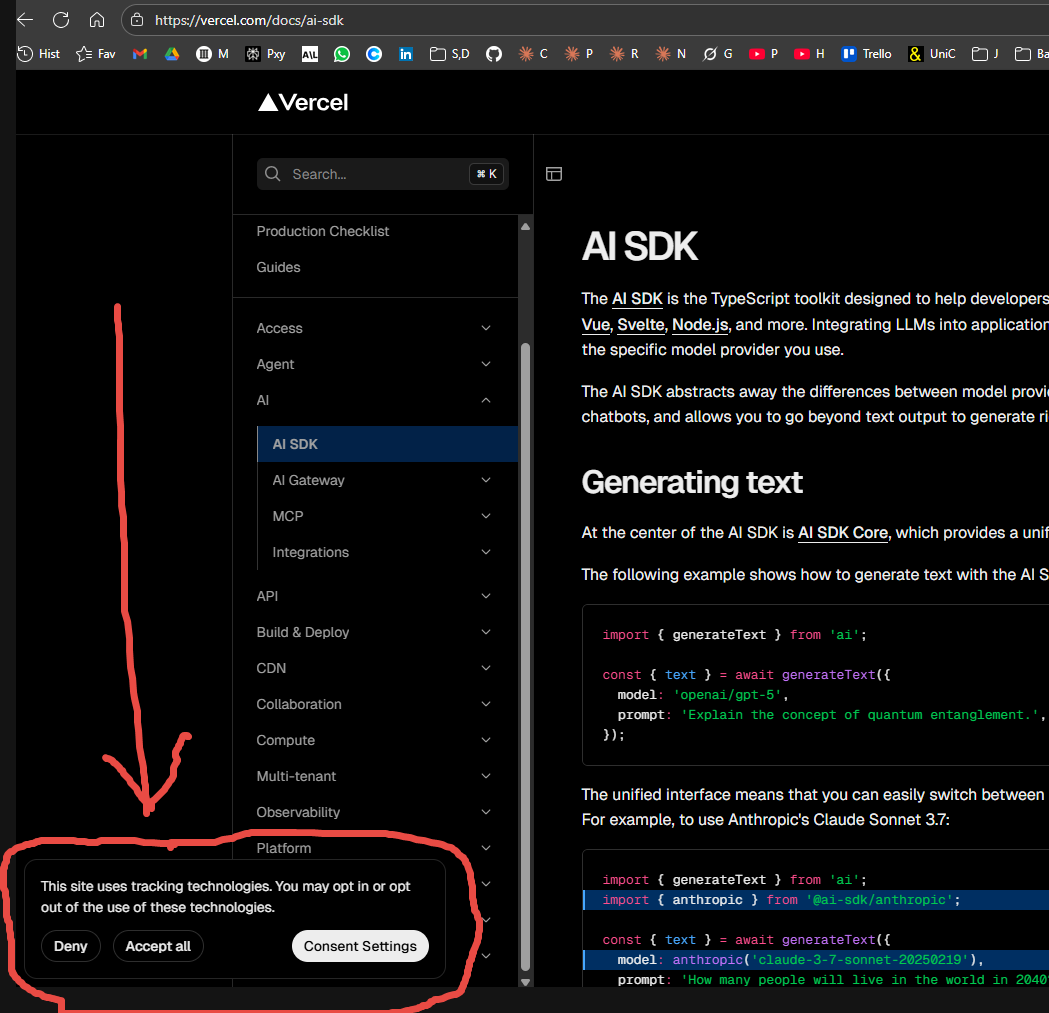
🤔 There's a Cookie popup in my scrape
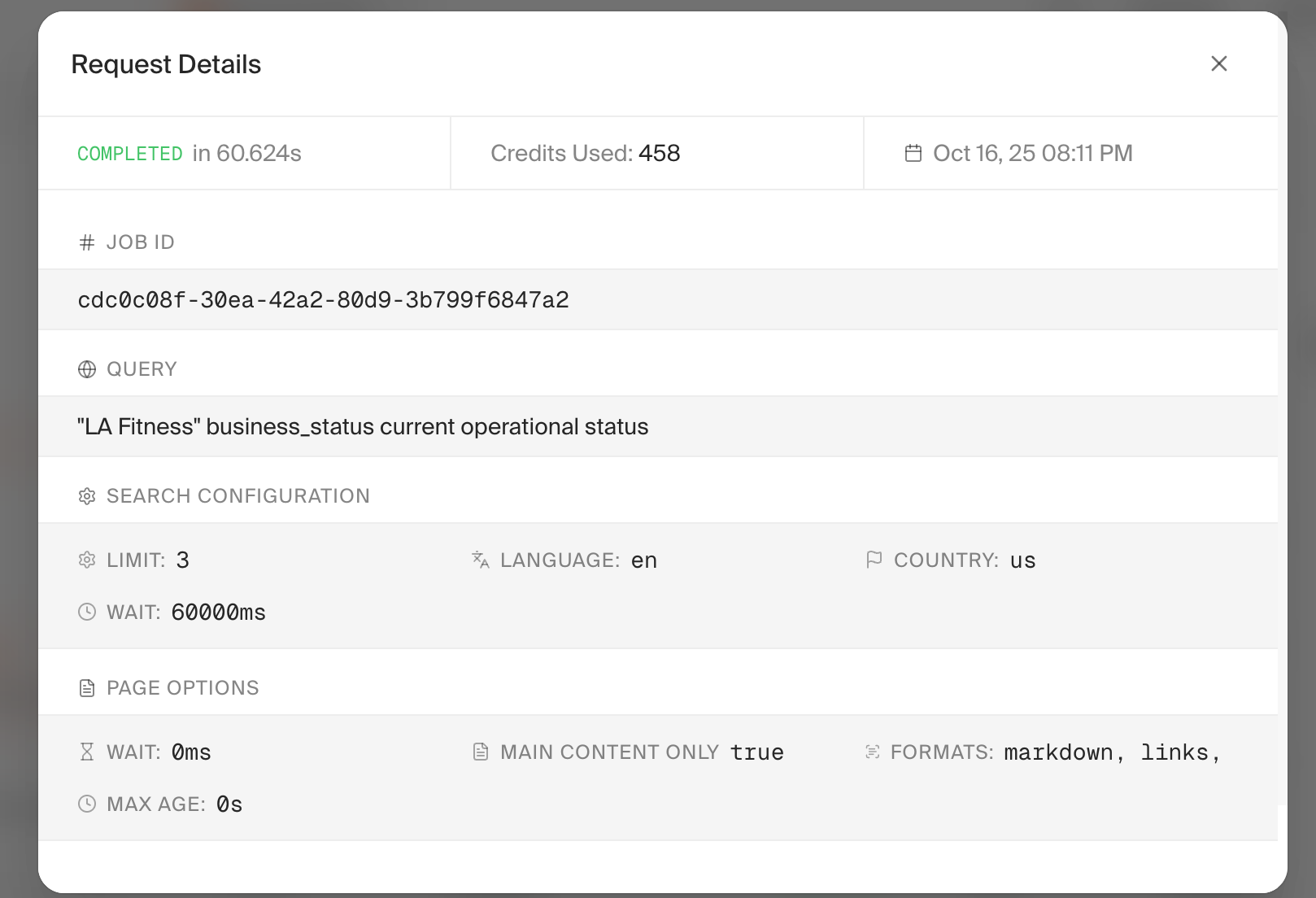
Unexpected Results from Extract
Crawl job not stopping and also the token usage has not been changed for quite some time
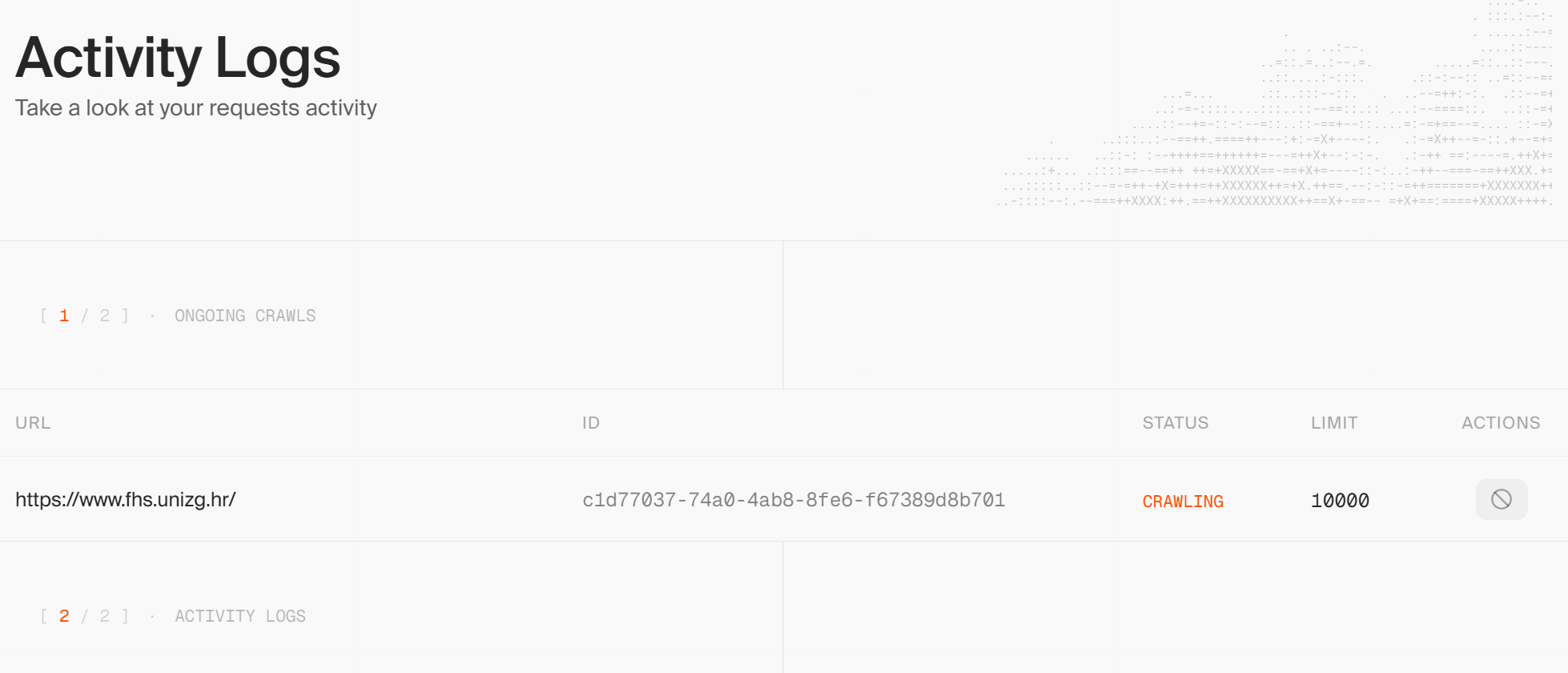
Extract isn't returning data
500 errors from Firecrawl Scrape API
Only One Result Returned When Scraping – Help Needed pls
Data Governance Queries
Hi there Team , I am a developer just wanted to contribute to codebase , I have analysed whole code
🔥 Challenge: Website requires 2FA to disconnect sessions + 3 session limit - is this solvable?
App keeps crashing, serverless function has timed out

Crawl does not work for a specific website, but scrape does