"markdown":"### Your browser version is not supported.

Crawl process using n8n cloud
scraping results only return 1 item from the list of items on the webpage
Scrape - Lazy Load Images

Batch Scrape Failure / Success
/map endpoint seems to have an arbitrary limit of ~300 urls
Crawl results of url/ vs url/index.html are different
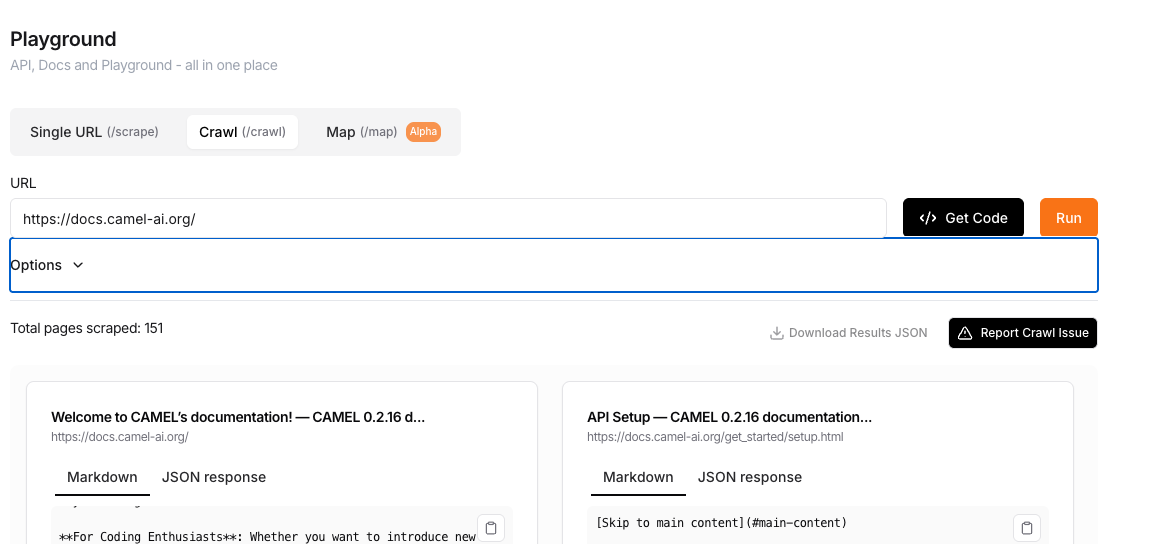
Help me to scrap whole data from specific url
Crawling 101 Doubts
Entire scrape failed due to a link
Erics most recent trend finder repo.
trend-finder@1.0.0 start nodemon src/index.ts...
What Software Does Everyone Use With FireCrawl ?
"Claude has rejected your request with error code 429. Here are the possible reasons: 1. You are sending requests too quickly; 2. You have hit your maximum monthly spend (hard limit); 3. The model is currently overloaded. Here is the error message from Claude: This request would exceed your organization’s rate limit of 40,000 input tokens per minute." For context, I have Claude Pro and Paid OPENAI accounts and use these API....
Batch Scrape Delay
Crawl gets blocked on sites like MSNBC
cookies after scraping web with Firecrawl
scrape's markdown contents different on API vs Playground
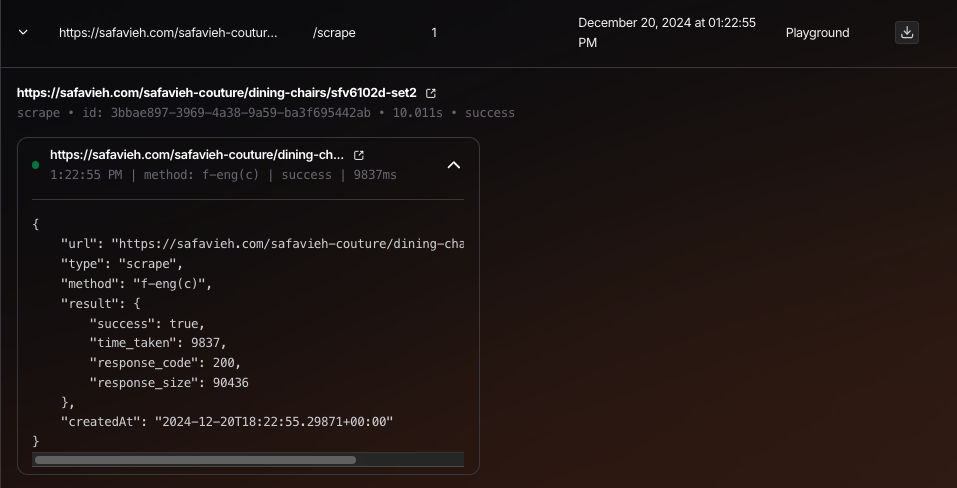
crawler in playground not extracting the content of all the sub pages
WaitFor doesn't seem to work
The /map api is not working for https://razorpay.com/docs/payments/
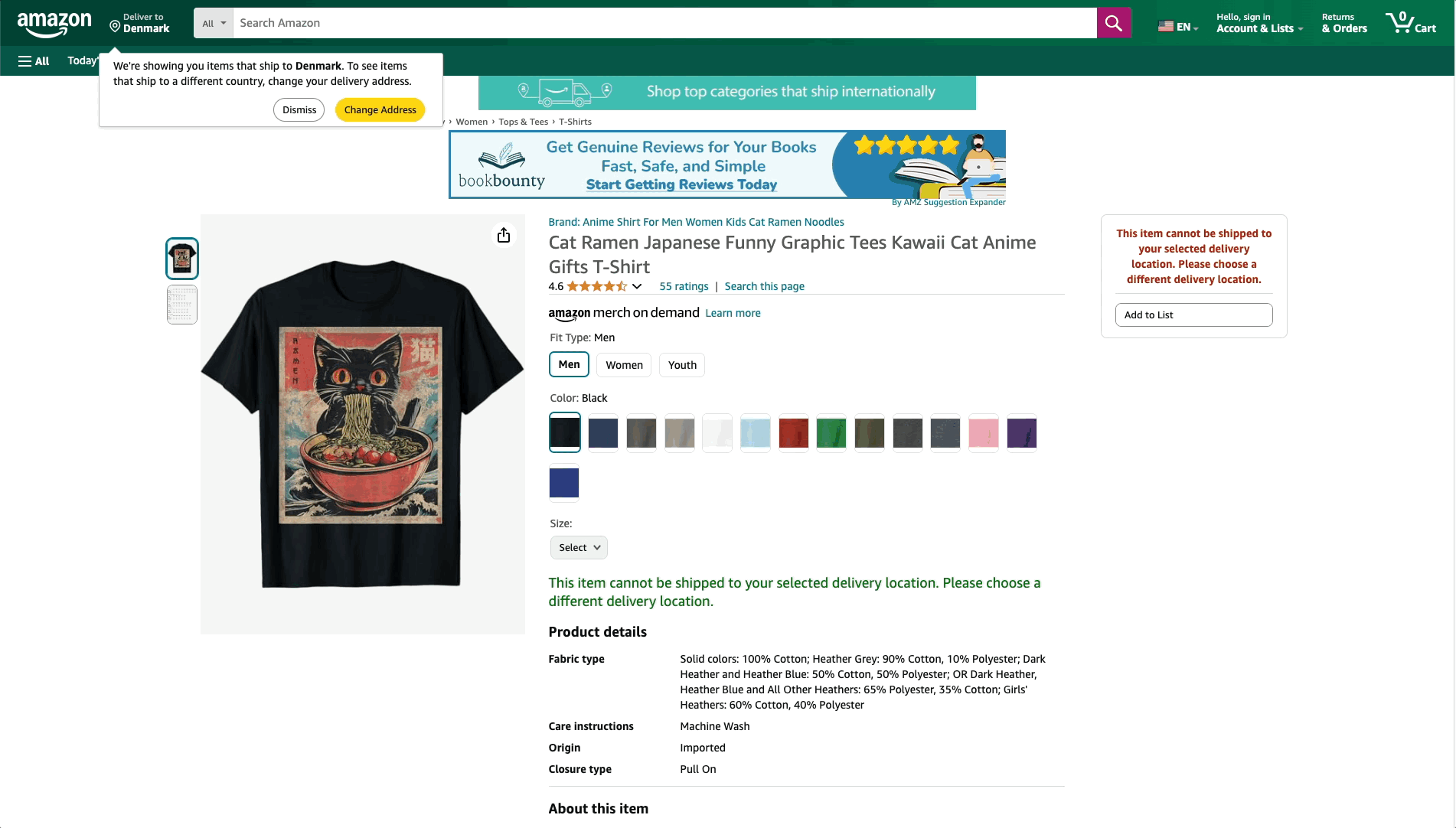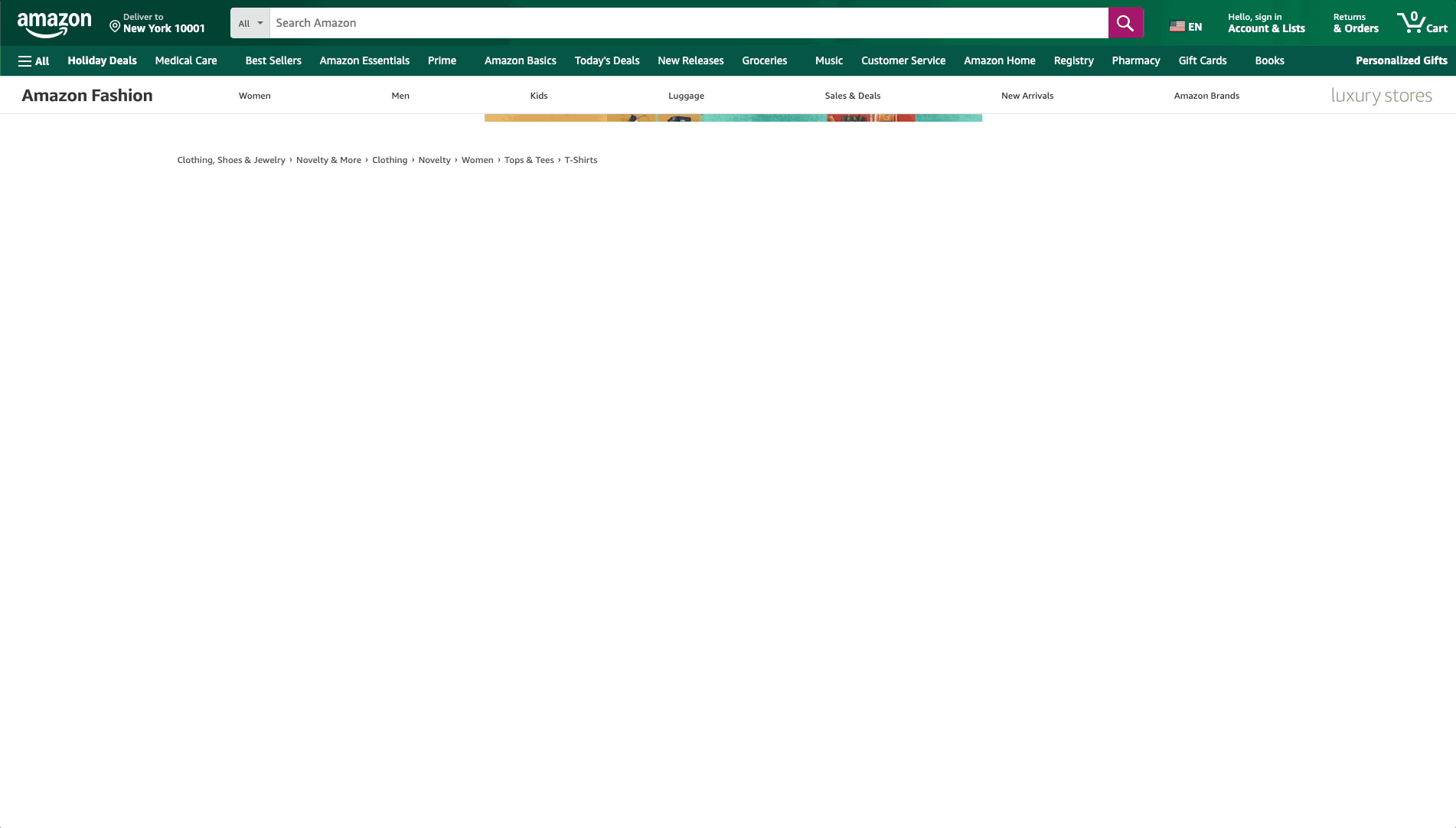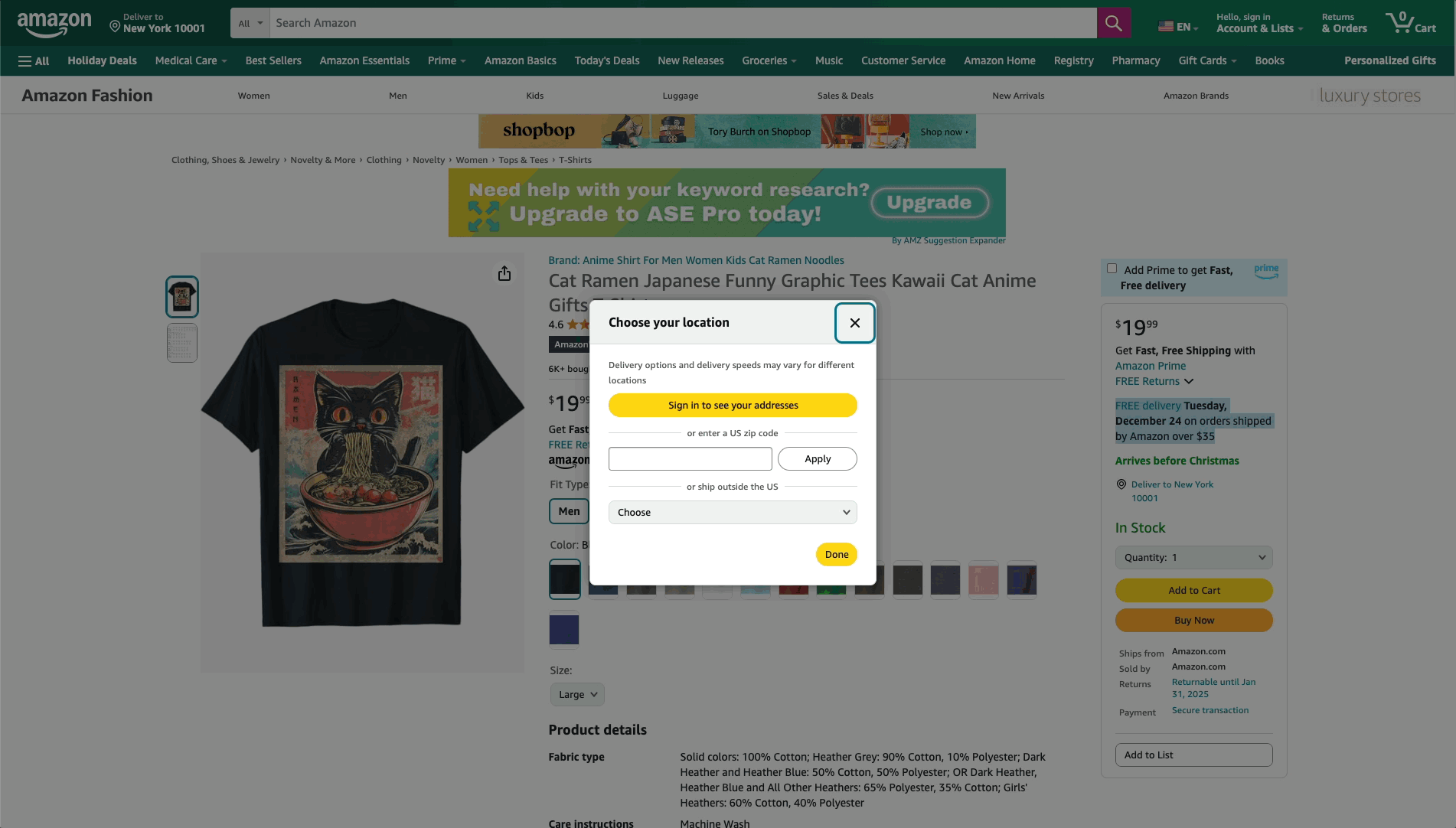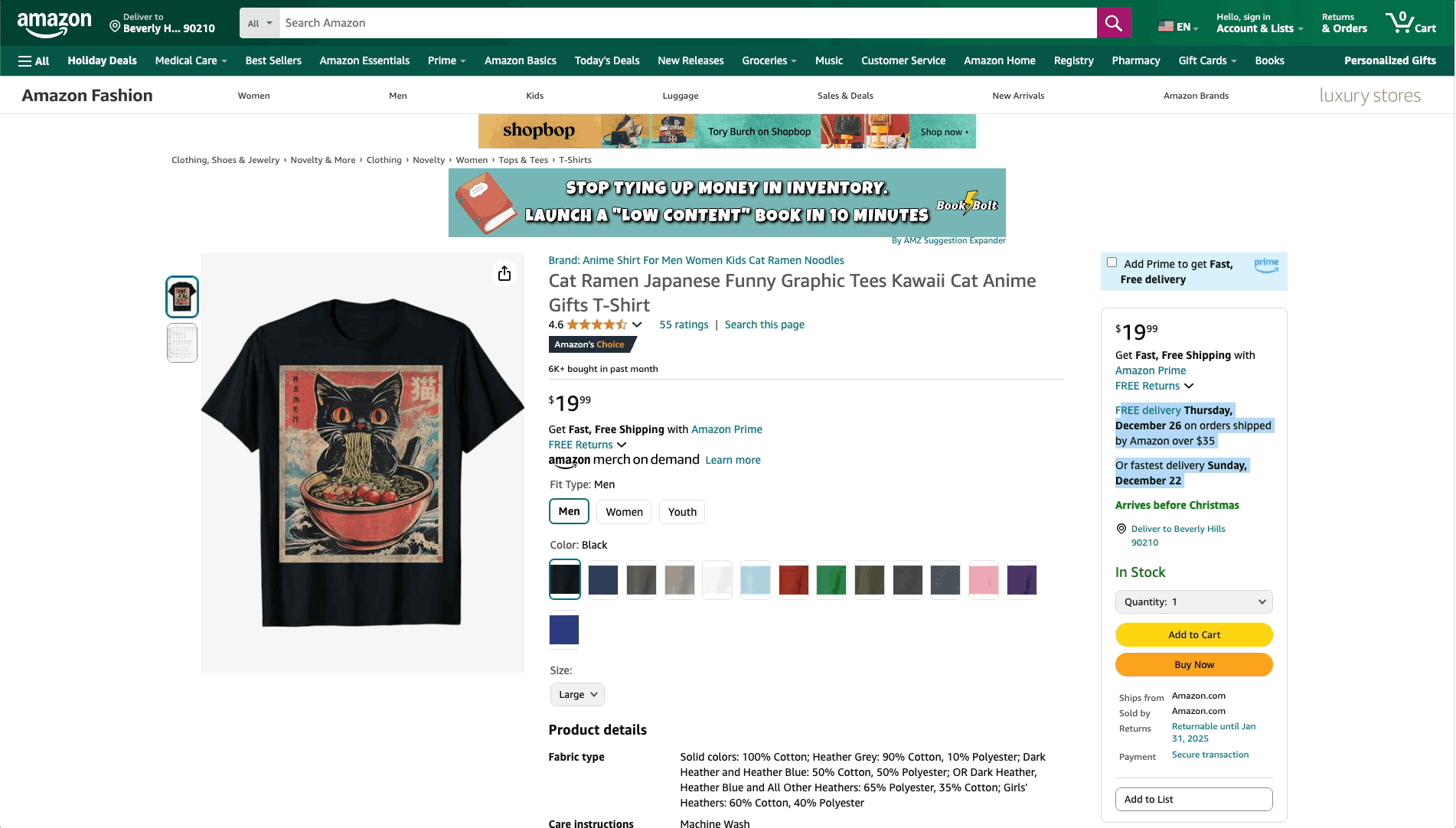
How to fetch estimated delivery dates of products on Amazon.com for different zip codes?