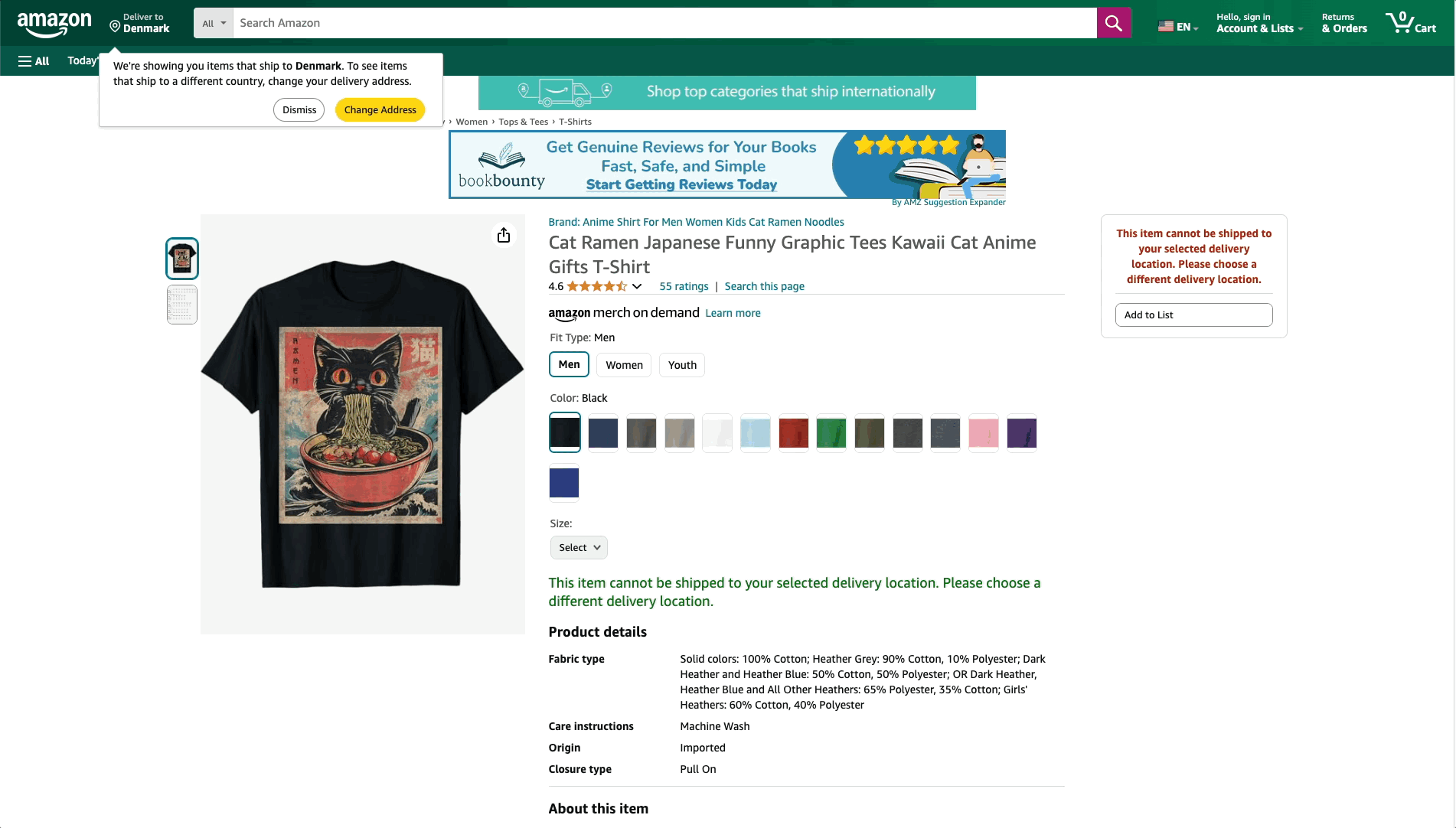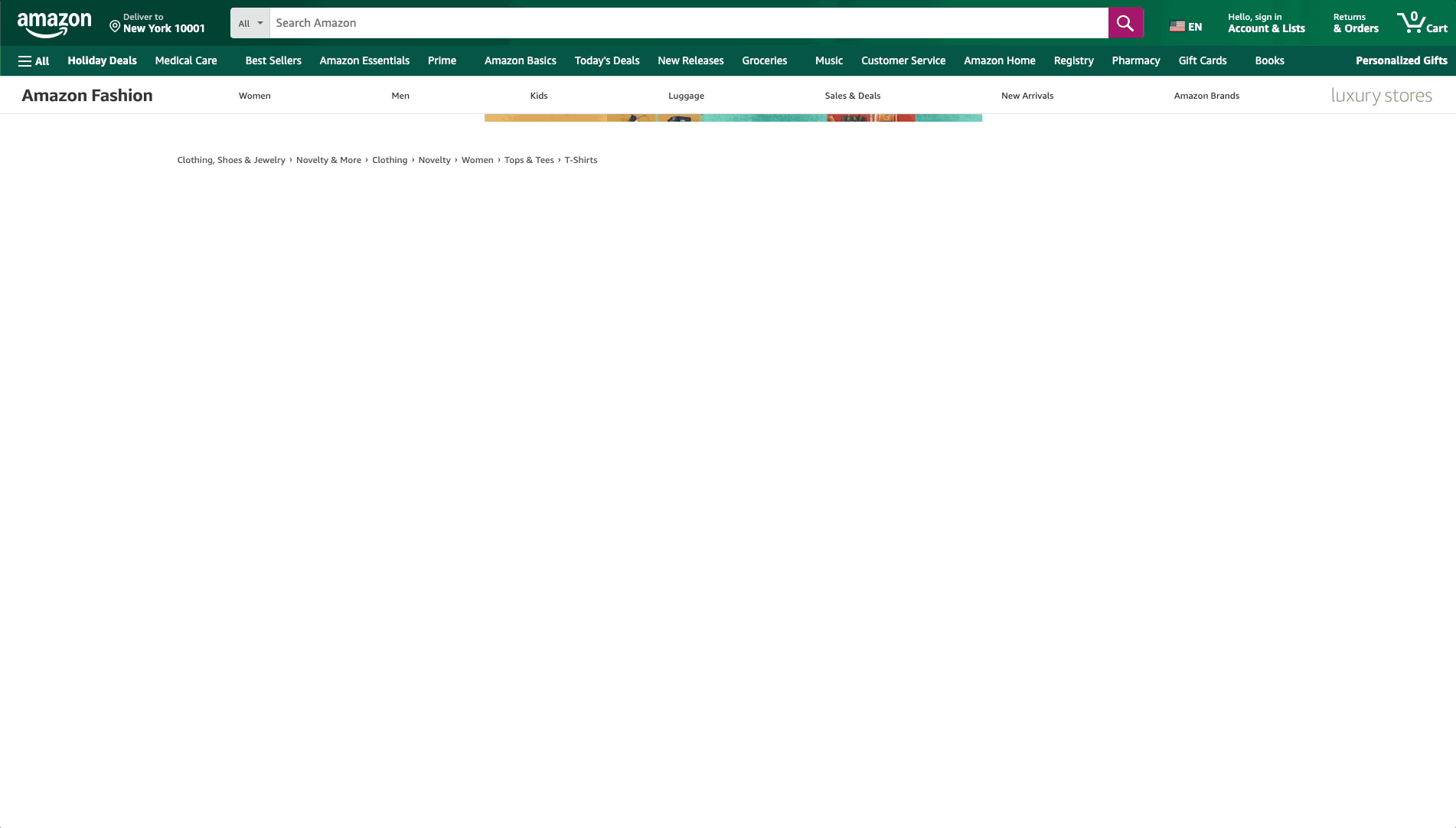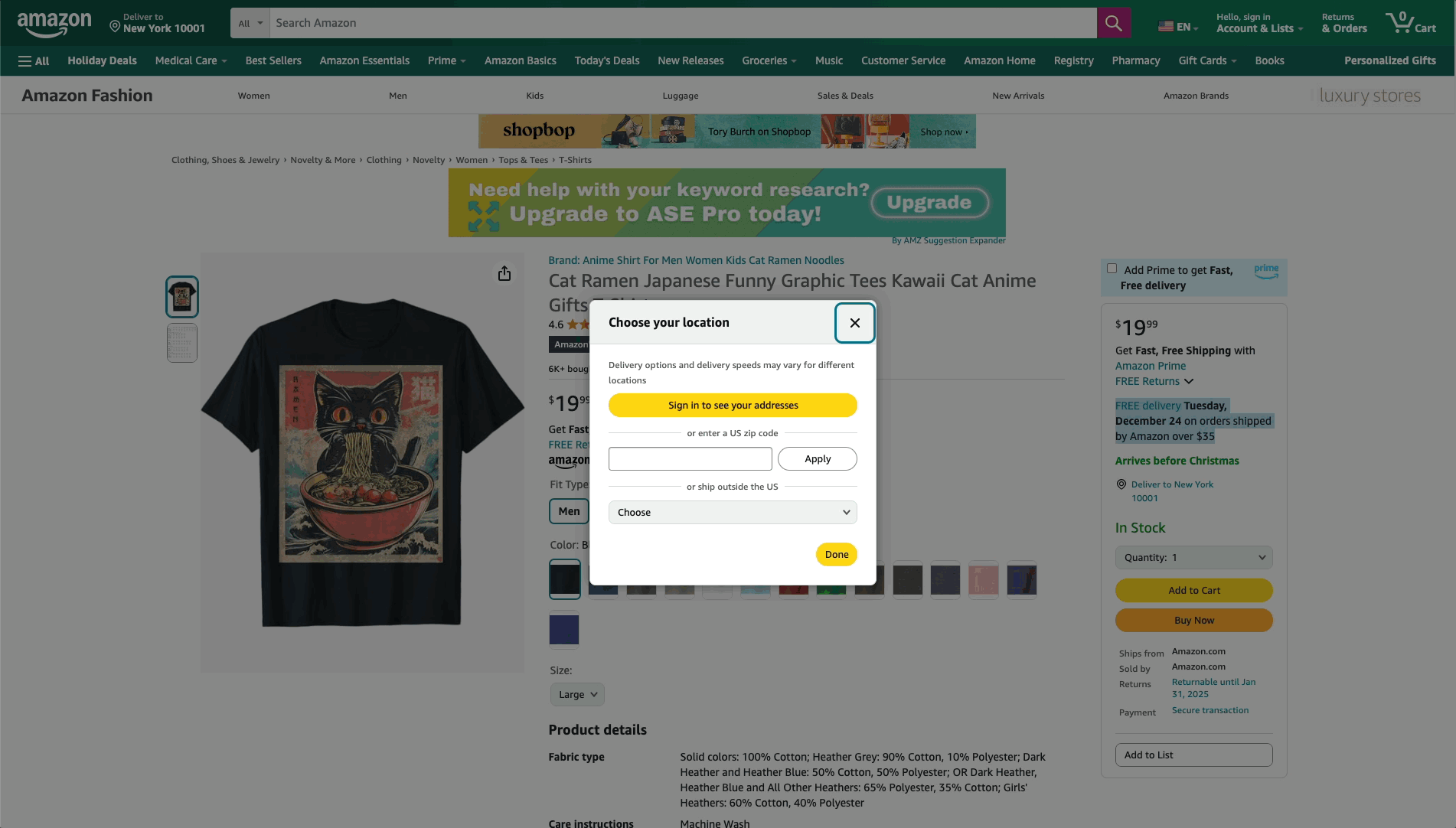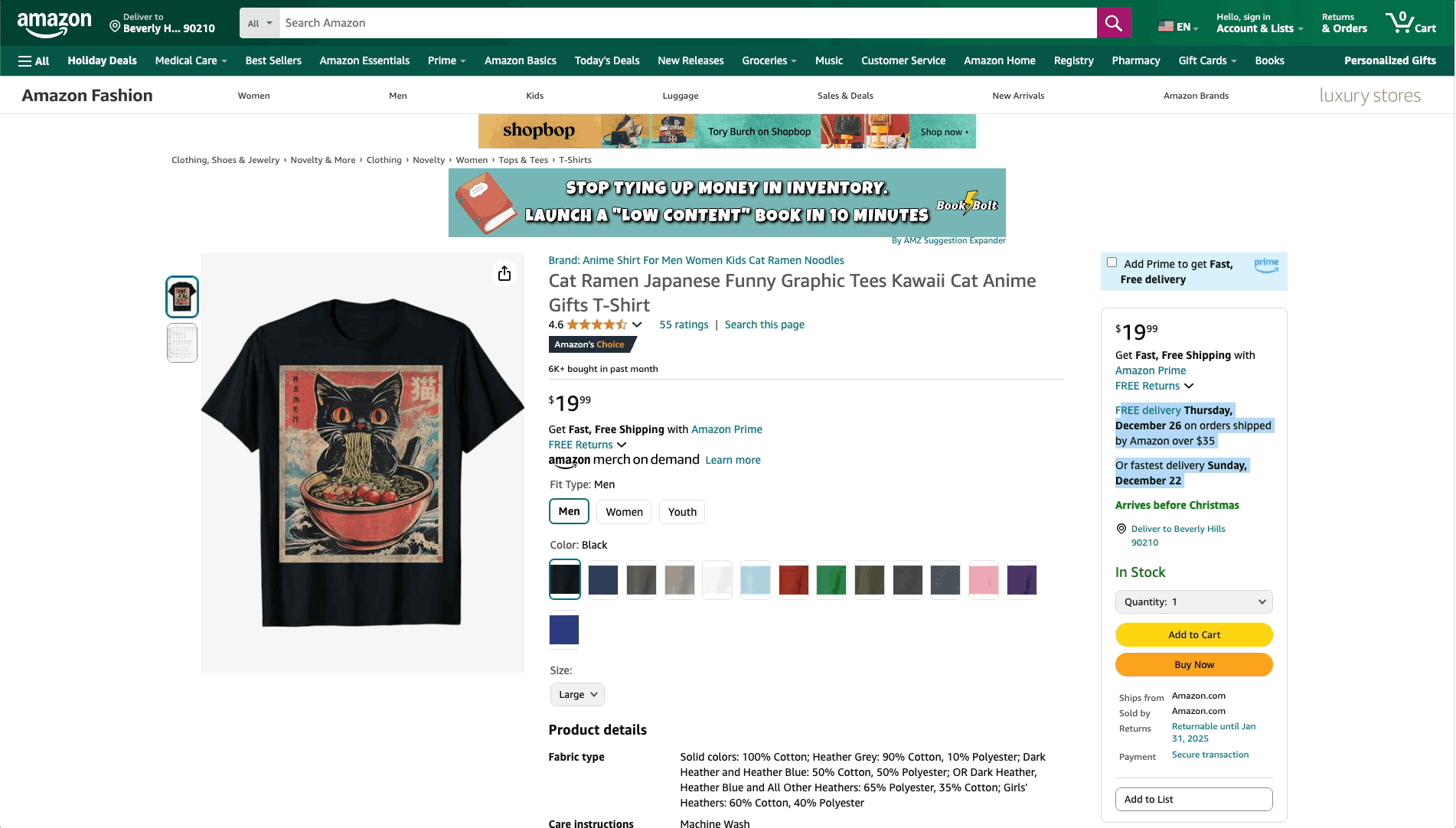
How to fetch estimated delivery dates of products on Amazon.com for different zip codes?
Has anyone successfully scraped and aggregated US realtor emails with FireCrawl?
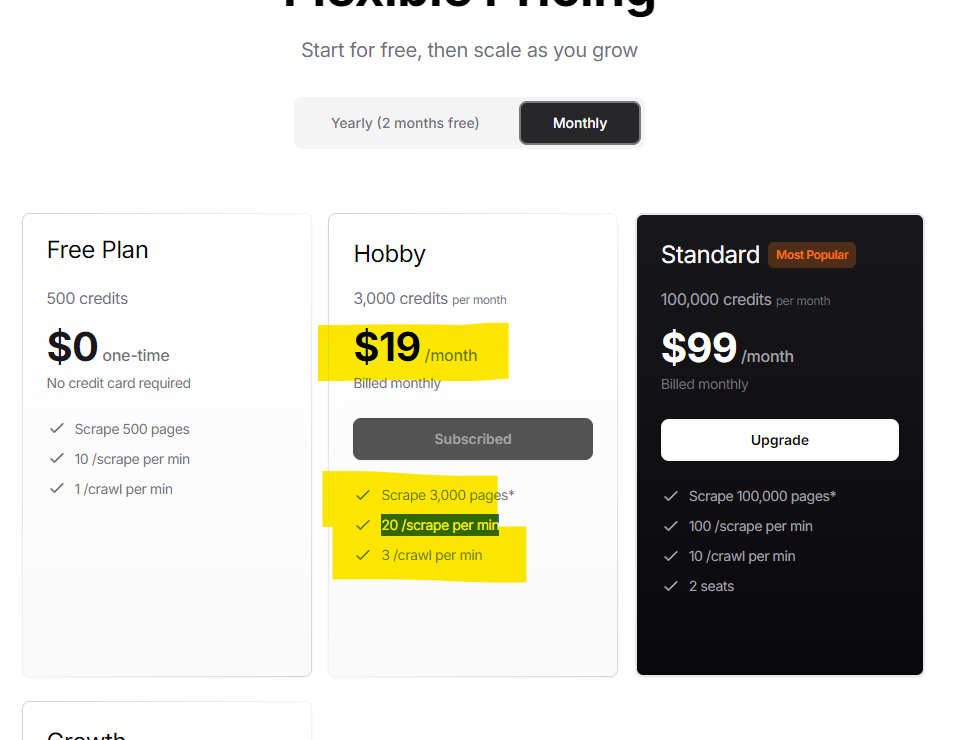
'Failed to load event' and 2 parallel crawls
How do I set the amount of pages I want to be crawled? In example only 10 pages on this run?
Instant "Request timed out"
408 "Request timed out" response.
If I intentionally mangle the post body, then it does return response about the malformed body, or invalid parameters.
I've tried from multiple connections (via vpn and without). ...Iterating over batch result pages (python)
Why the worker is not stable
Unable to crawl more than the base page of https://www.trustpilot.com/review/huel.com
issues with /map

No markdown content is returned for https://api.sharefile.com
Webhook is intermittent
Local Environment Max Retries Error
Missing all child pages when crawling
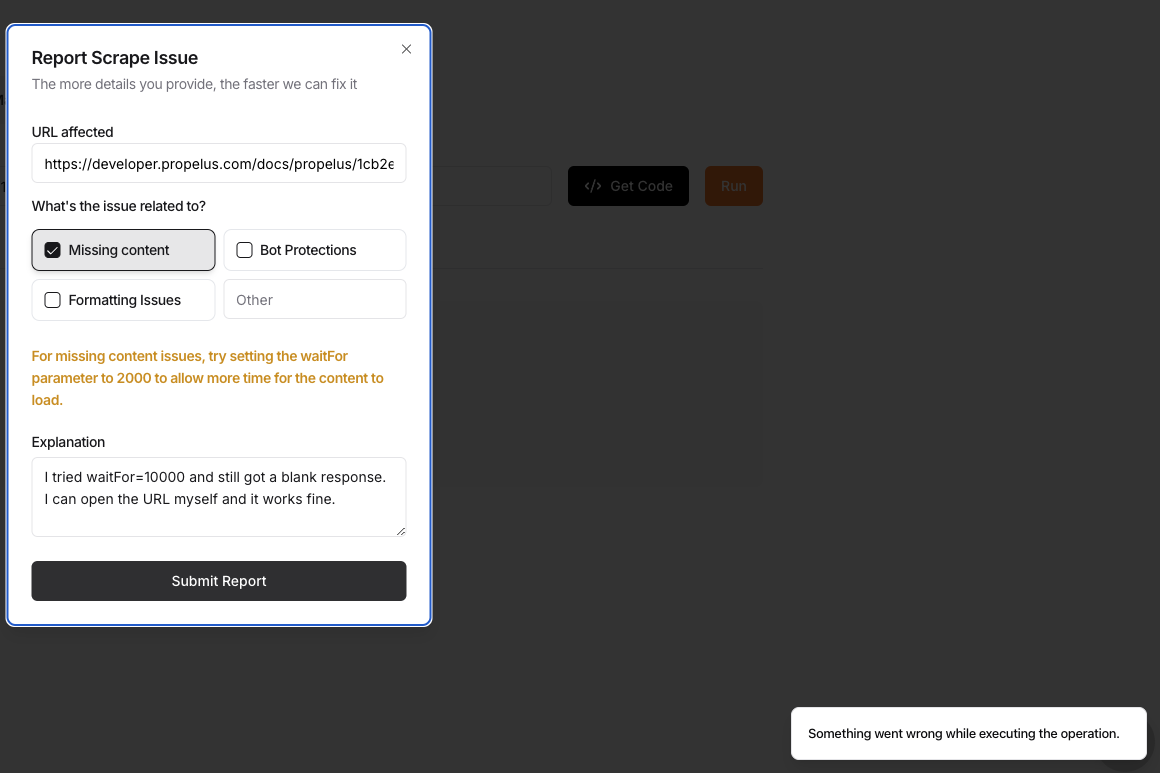

Unable to crawl https://developers.tryprive.com/
I have 3,000 credits. Why I can't crawl more website?
data: {
error: 'Insufficient credits. You may be requesting with a higher limit than the amount of credits you have left. If not, upgrade your plan at https://firecrawl.dev/pricing or contact us at help@firecrawl.com'
}
However, I do have enough credits....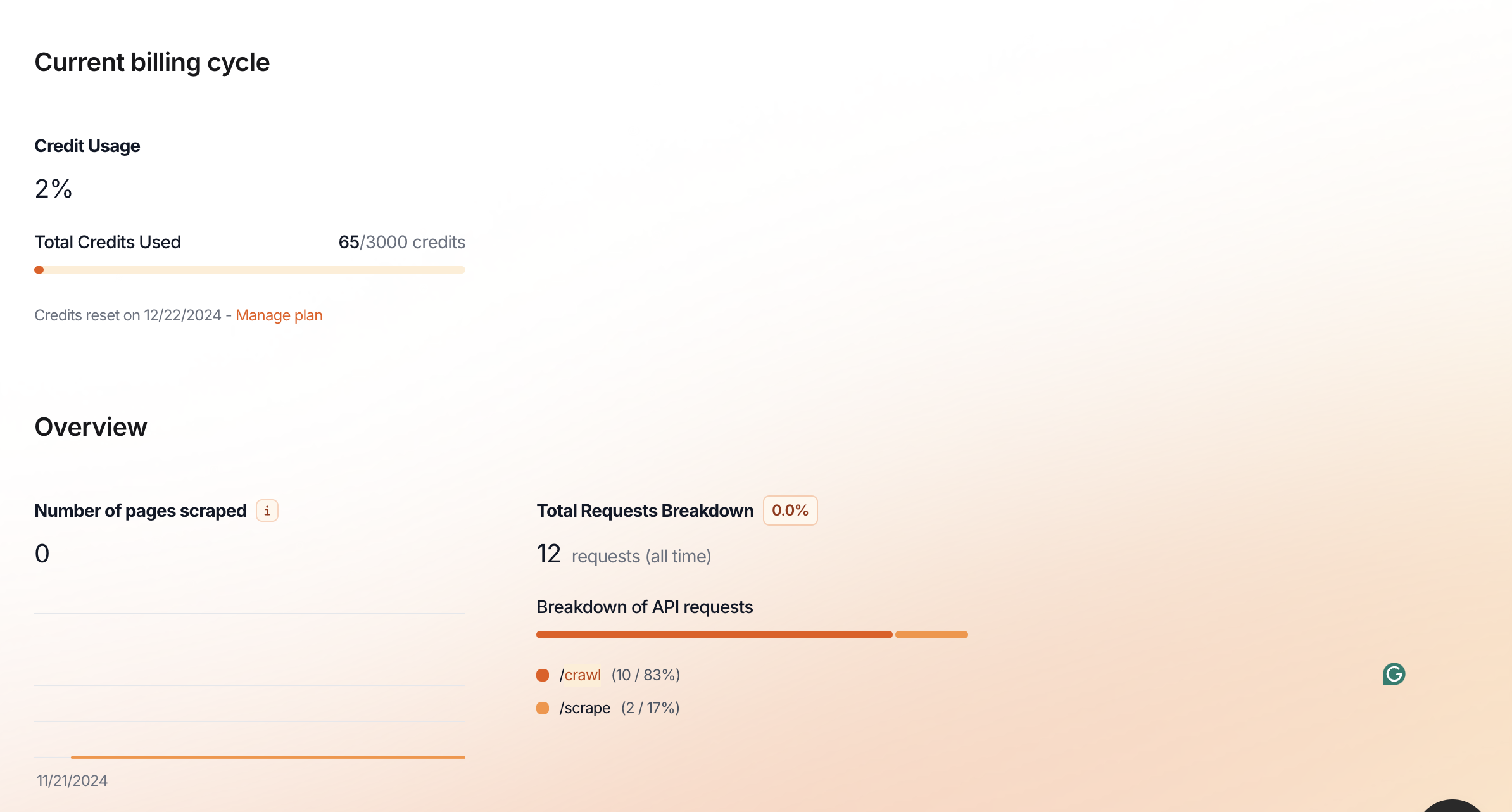
Not getting back the favicon icon as expected