ERROR: 408 on Scrape
Request failed with status code 408
at FirecrawlApp.scrapeUrl (webpack-internal:///(rsc)/./node_modules/@mendable/firecrawl-js/dist/index.js:78:13)
Any ideas on what this error code means?...Bulk Crawling
Hello,
In my app, users enter a URL and select additional links from a list returned by the /map endpoint that they would like to crawl alongside the main URL they provided. Currently, I'm sending a request to the /crawl endpoint with the main URL being the one the user provided, and the includePaths:[] containing the paths the user selected from the /map endpoint.
However, it seems that all the links from the main URL are being crawled, in addition to the selected paths. How can I modify my request so that only the main URL and its selected includePaths are crawled, excluding any other links?...
Reduced /map endpoint results
Till yesterday, /map endpoint was returning 5000 links but now it’s only 99 links.
Did it get reduced or a bug ?...
base64 images
When crawling some pages, it picks up on base64 images, making it not fun to put that into vector stores 😄 any suggestions?
Does map_url support external links?
I tried using
allowExternalLinks in map_url, but none of the external links appear. Am i missing something? Or is this not supported yet?http 👉 https
Let's say I'm sending a url starting with
http://, the url redirects to https://. Will sublings starting with https:// be crawled?408 errors on both API and Dashboard
Hey guys, are y'all experiencing issues? I cannot scrape anything pages currently. Thank you!
I want the main content and all the css + js links in the html. How do I do it?
I attempt to set:
'formats': ['html', 'rawHtml'],
'onlyMainContent': True
and hope that the rawHtml will be the html + (css + js) files. But it is not true. It is the original html without noise content filtering.
...
Why firecrawl doesn't support crawling linkedin page data?
it does not support social media data right?
`next` pagination using js-sdk
Using version
1.2.2, does the js-sdk have a built-in method to follow the next url?
I call asyncCrawlUrl() and then checkCrawlStatus() every 5 seconds until the job status is complete. However, I'm not sure how to get the next page of results from the next property.
More detailed examples of how to use asyncCrawlUrl, checkCrawlStatus, and the next url would be appreciated!...Just upgraded to Standard now I'm getting an `Unauthorized` error.
What's different between free and standard?
Limit speed each request
Hi,
I dont know how the crawl works but it's possible to slow the crawl and dont get detected ?
I check the doc : limit is the total page crawl
poll_interval is the status of the crawl ...
Cannout get around of cloudfare with the nodejs API call
This is my code
const params = {
pageOptions: {
includeHtml: true,...
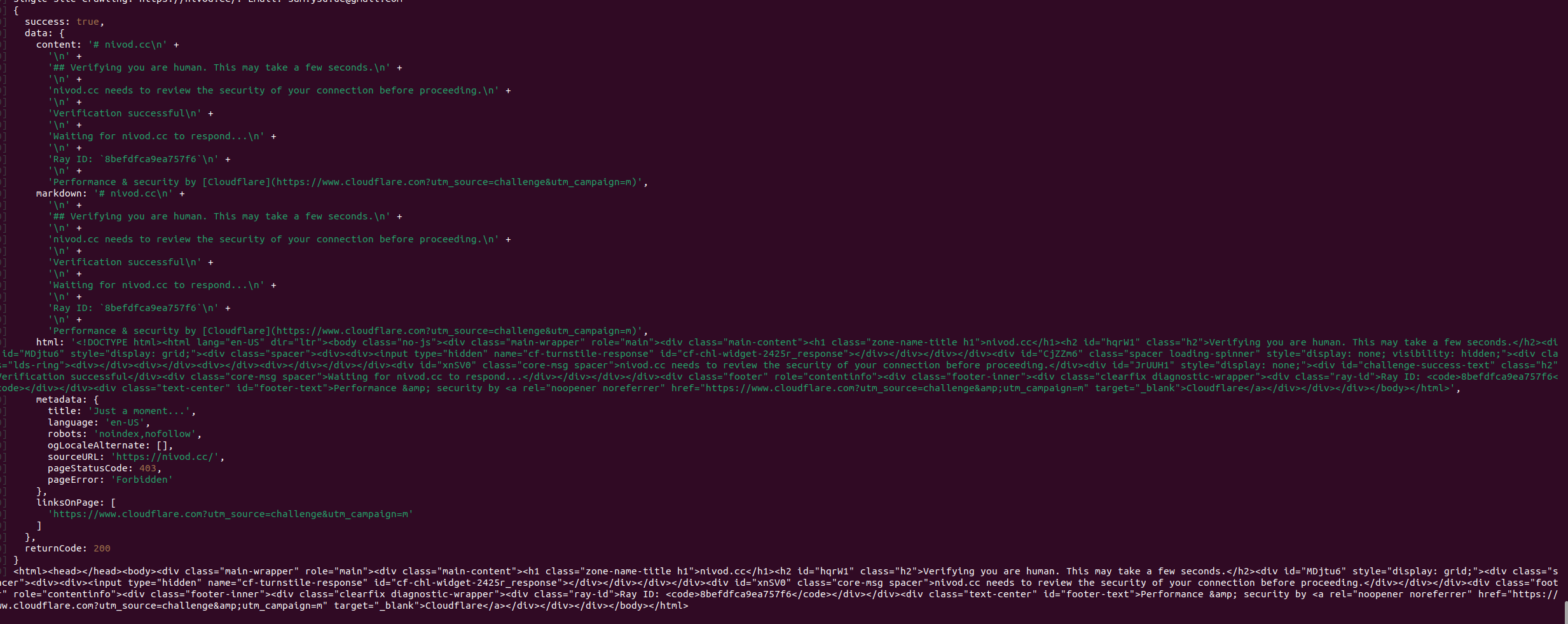
Unexpected error happens with the scrape of https://nivod.cc/ using curl
this is the response
{"success":false,"error":"An unexpected error occurred. Please contact hello@firecrawl.com for help. Your exception ID is 9b0fd50d-7f45-4dbb-9af5-5d81b39ca5f8"}y...
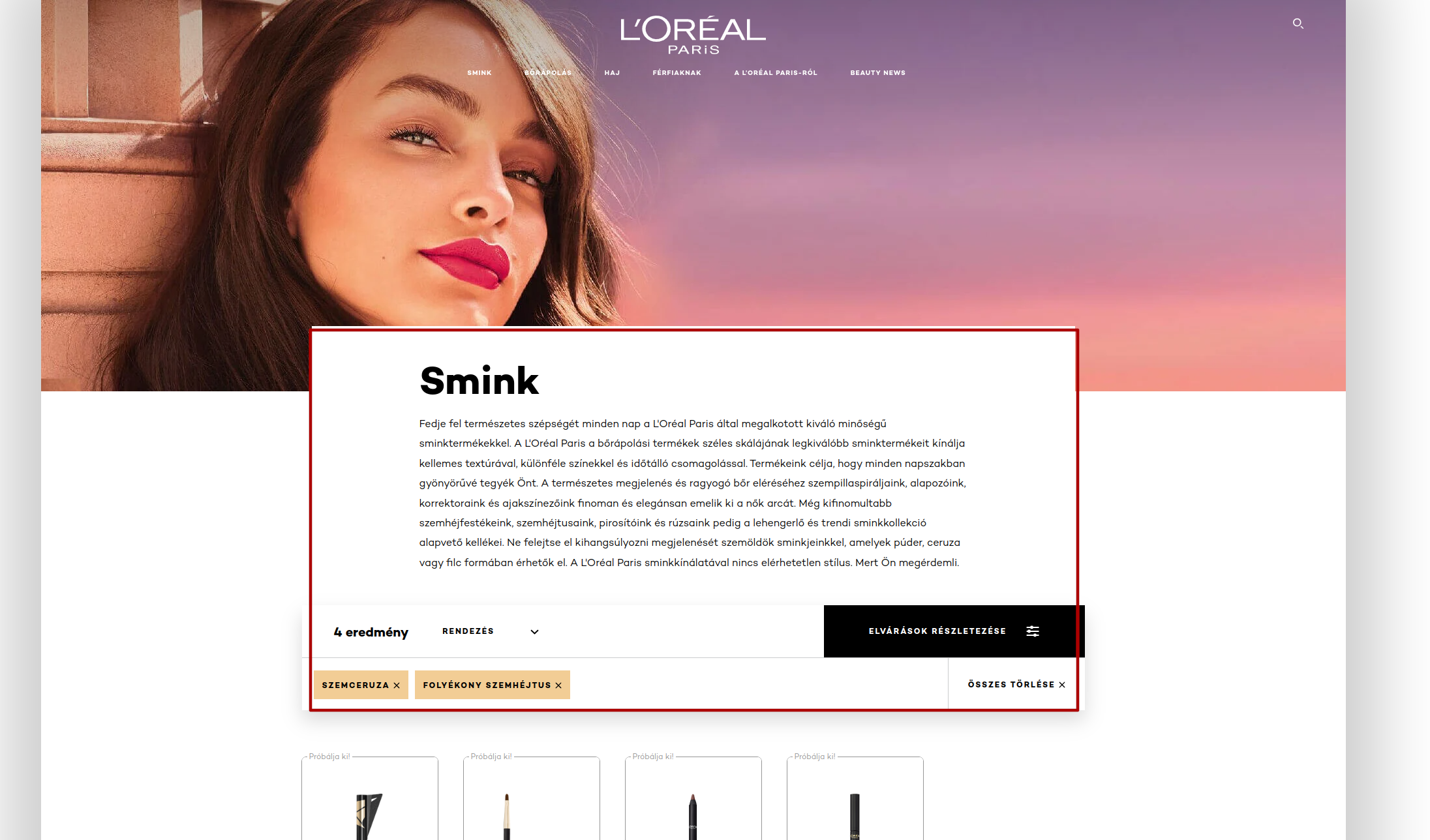
https://www.lorealparis.hu/smink?texture=folyekony-szemhejtus&product-type=szemhejtus
the most important text of this page is missing in the scrape
Scraping websites built with GoDaddy
Hi, I am using Firecrawl and I have some issues with scraping websites built with GoDaddy, can some team member contact me so I can send more examples of failed attempts?
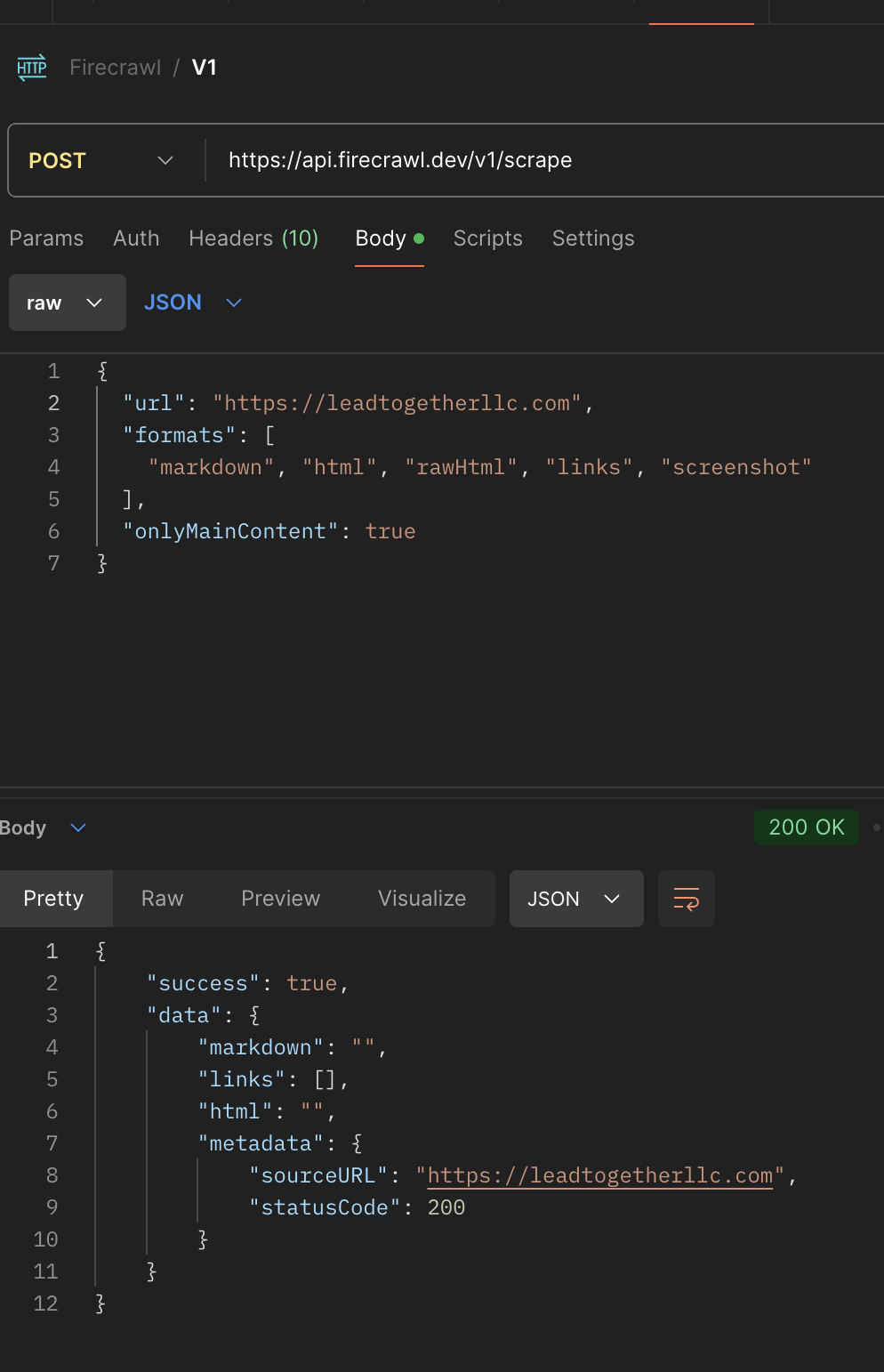
https://leadtogetherllc.com/
Using v0, v1 and your Playground (v1), both /scrape and /crawl endpoints don't work....
stuck with python sdk, works on and off with curl
I just selfhosted a firecrawl instance yesterday, it works immediately with a curl request to /v1/crawl, which is a surprise! and then....
1. with curl
i built
playwright-ts and it doesn't work at first because i didn't really think when I quoted PLAYWRIGHT_MICROSERVICE_URL=http://localhost:3000/scrape from the SELF_HOST.md into my envfile, which is obviously incorrect. after I fixed it i works with example request
```...'limit' not respected?
Hi there -
I'm having trouble getting the
limit option respected; this was true in v0 and now in v1.
I have just built the docker image from the main repo and running local. Different permutations of limit and maxDepth return different results, but not in a way I understand. ...