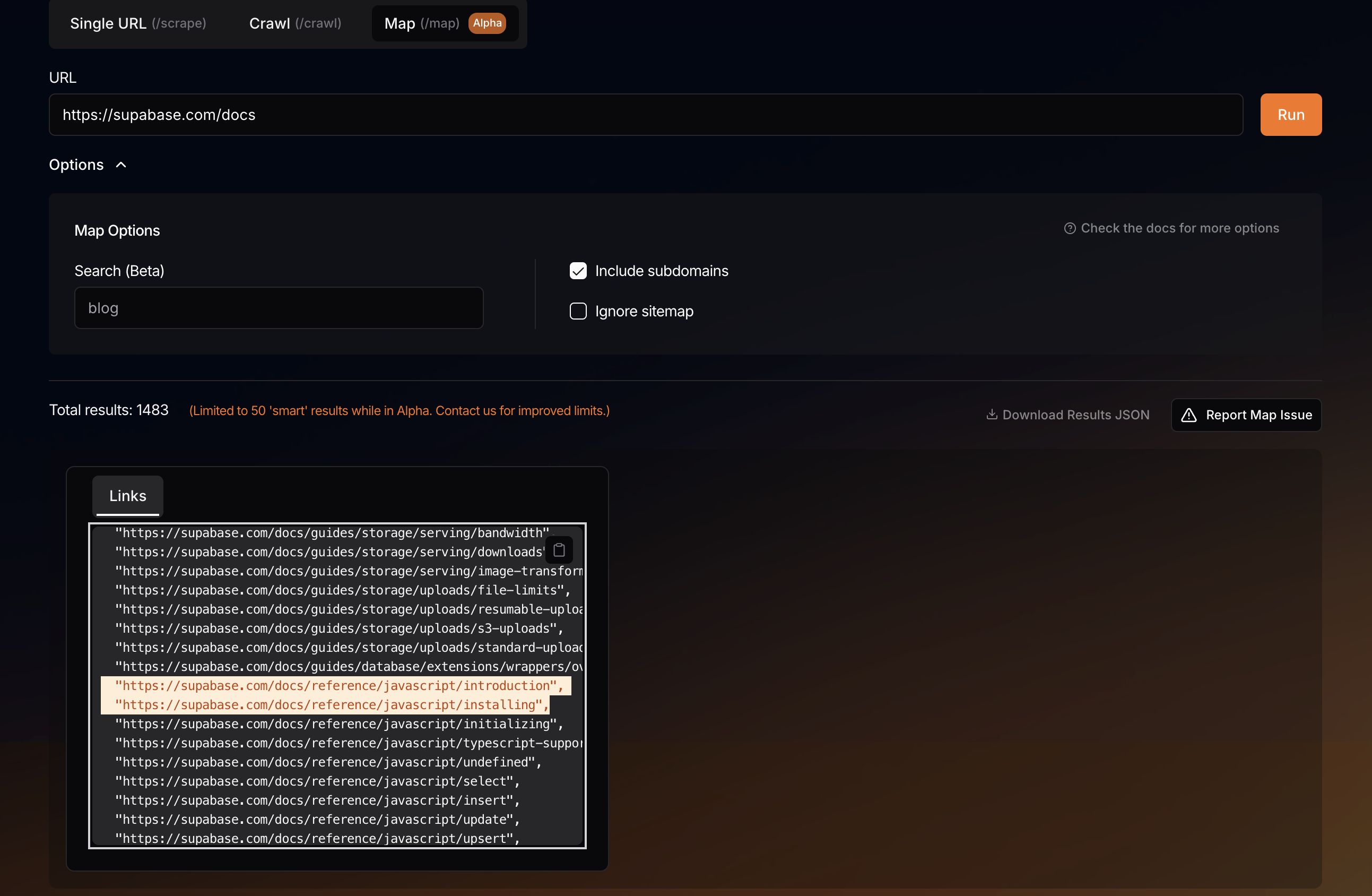
ideal input for `search` param in /map endpoint
search param should look like ?
for eg. if i want a company's global offices information i would ideally go to the page where locations , offices information is there, soo in the search query i passed location keyword as the param value.
I got the website where the locations are present however i got additional > 50 websites which were not required at all.
so i am hoping to narrow down the filtered list .. ...Why am i not able to use map_url?
Is it possible to get a JSON response from CRAWL via API??
taking a screenshot of a single element.
Unstable behavior of Crawl Jobs for V1
Empty 200-code responses on crawl, but completed on page scrape?
How to see why a crawl path was chosen?
help with scraping inside data
Can I use FireSearch from python sdk?
Unable to crawl
Supabase error
Scraping reddit
Social Media Crawling Update
Issue with Crawl process for V0
Need some clarity on the credits usage for /map endpoint
Best way to get started.
Issue with Crawling Multiple Pages - Only One Page is Crawled
Issue with Null Data Returned After Multiple Attempts (more than 10 Attempts with Python SDK / cURL)
Firecrawler IP for a whitelist