is there a limit for screenshots per scrape ?
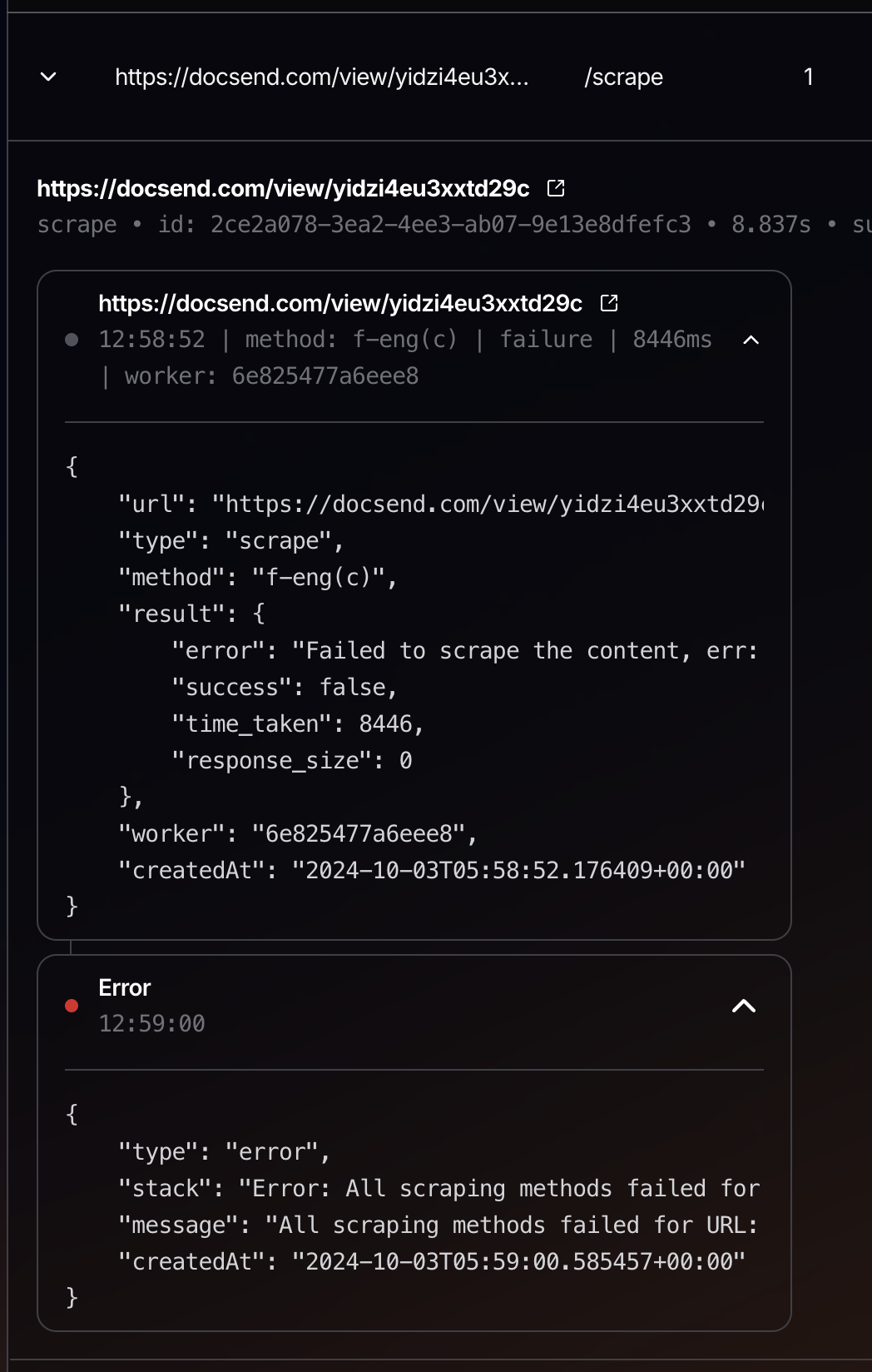
Error in scrapeController: Error: Job wait

My webhook url is too long to be set on the interface
Crawler stopped after encountering 404,
on_error hook...Trying to get a list of YC startups by tags (i.e. hardware startups).
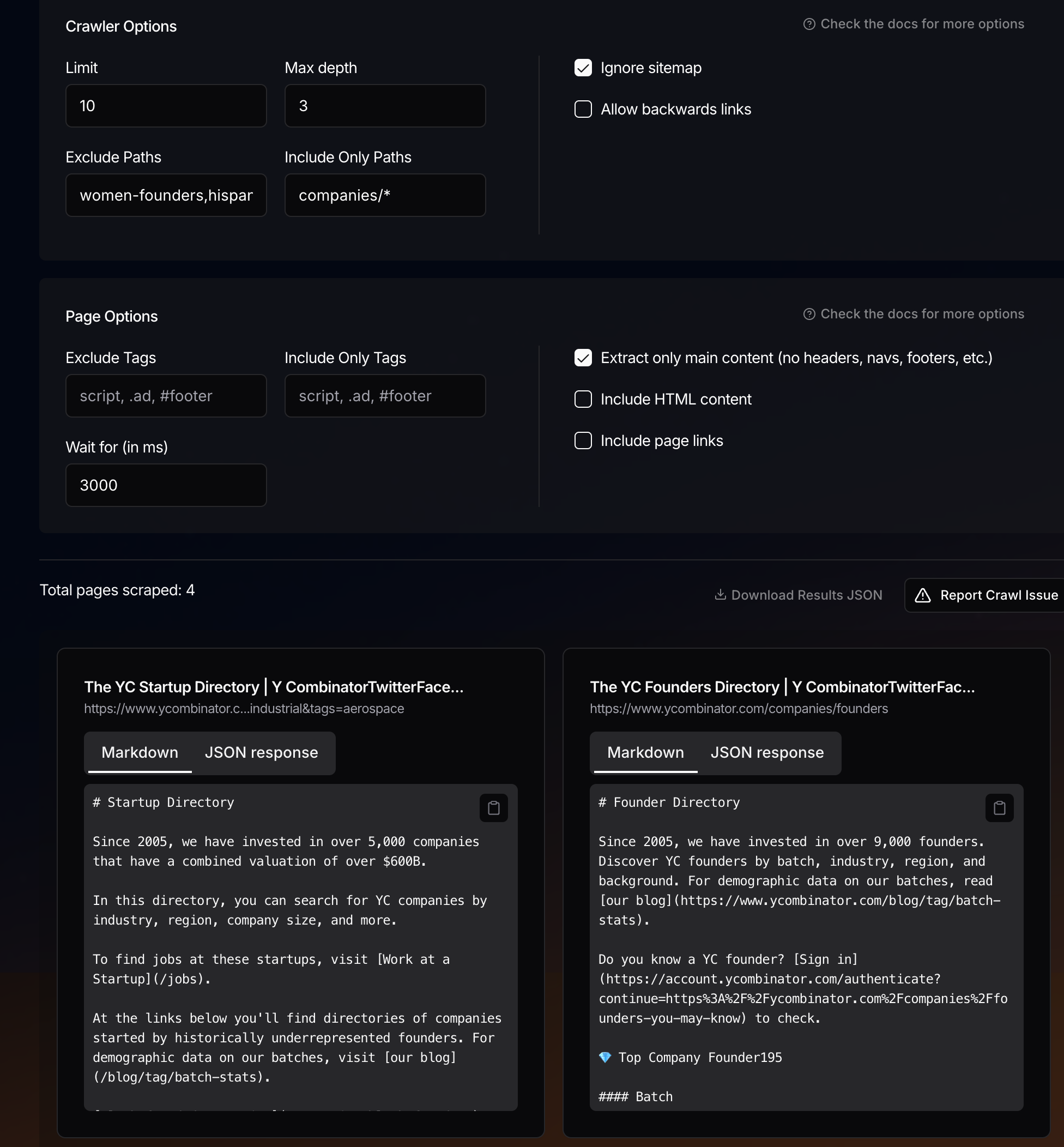
Issues and Inconsistencies During FireCrawl Testing
Map does not seem to return all the urls
Discrepancy in links returned by /map
Crawl "Include Only Paths" not working?
The catalog page / main crawl URL: https://www.ssense.com/en-us/men/sale/clothing. Ex. Product Page 1: https://www.ssense.com/en-us/men/product/essentials/black-patch-hoodie/14616841 Ex. Product Page 2: https://www.ssense.com/en-us/men/product/auralee/brown-pleated-trousers/14085441 ...
Crawl Status pagination not working
39e8951e-f0a9-434d-b869-c2b6fbc99437
it has crawled 490 pages but the next link is not giving any data...Make API Error

HTML -> Markdown (Missing Info)
`format: ["links"]` doesn't respect `excludeTags`
format:["links"] does not appear to respect excludeTags.
for example:
```ts...INTERNAL SERVER ERROR
Playground works on the site i'm trying to scrape, but API SDK returns the captcha
Does Markdown include image alt text?
Is there telemetry and can it be disabled?
LLM Extract Does Not Do Whole Page?
Does the extract functionality allow to pick different models?