Every crawl returns null data
I have been facing this for past 5 days and hasn't been resolved yet, hence putting here:
I just crawled a site and waited after getting completed status for long time over 1-2 min and still the data isn't right. Now instead of sending just null in data, it is sending a list of nulls. Now this even breaks my checks, over if I received an empty list or a null value in data field.
The job_id is
56834938-0b41-458c-9012-9c7bcd7f7cbf...Scraping Timeouts
Hey right now almost every scraping request fails through a timeout (requests that worked before). Any outage/incidents rn?
Credits spending clarification
Hi! I have scraped around 50 pages using single_scrap and
llm_extraction_with_markdown and already spent half of the limit for Hobby tier, 1600 credits. How could I estimate how many credits will I spend per scrape using different options?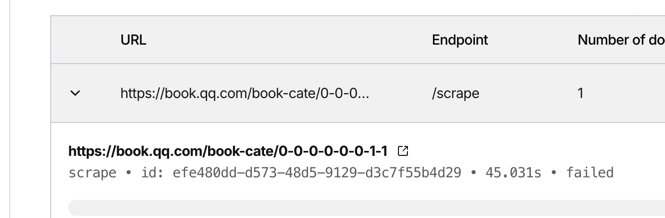
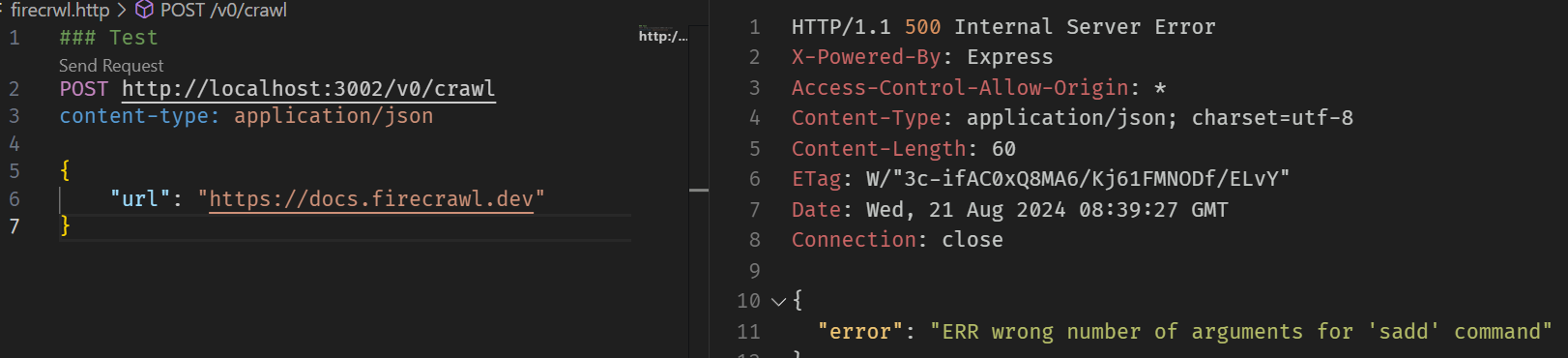
redis command error
{
"error": "ERR wrong number of arguments for 'sadd' command"
}
{
"error": "ERR wrong number of arguments for 'sadd' command"
}
Scrape requests fail by timeout
Hello!
All the requests for websites scraping fails by timeout.
Domains are available, most pages of them were scraped 1 hr ago successfully.
I tried to scrape our own domain (that doesn't have any protection) and that one fails too....
408 / 502 ERRORs when scraping particular URLs via code/manually
Hello guys, I have developed a simple script that iterates through sitemap and scrapes each URL individually via the scrape endpoint.
However, some particular URLs just return 408 / 502 errors, when scrape endpoint is called, dunno why - but its not the issue in the code it seems, because even when I try to scrape them manually from the Firecrawl dashboard - nothing happens.
These URLs are in case of this particular client:...
I am running this simple code to scrape a website
from firecrawl import FirecrawlApp
api_key = os.environ["FIRECRAWL_API_KEY"]
app = FirecrawlApp(api_key=api_key)
url = "https://atharvacoe.ac.in/"...
Not able to scrape OpenAI API Docs: https://platform.openai.com/docs/api-reference/introduction
Hi, anyone is able to scrape this page? I can't figure out why it can scrape this page?
Getting wrong jobId
I'm sending a scrapping request and obtain a jobId for the request. I see in the dashboard that the scrapping was done correctly, but when i obtain the callback, I get an incorrect jobId.
I had saved in my database the jobId to match the pending request, and the one I get in the response doesn't match anything on my database (and I never get a callback for the original jobId I got when doing the request).
If I check the status manually on the first one I got, I get the content result, if I manually check the second one, I get nothing.
Please help! I have all my requests pending as I have the integration done by assuming I will get a matching job Id in the callback (and I did till yesterday's release)...
apiKey for Docker self-host
Hey guys, when trying to run the dockerised version and pointing the apiUrl to it, it is still prompting to add an apiKey. I cannot find what to use here or if it's even configured on the docker side. Omitting it doesn't work. WHat do I do?
Overloaded Error
The application seems to be down or under attack
Cannot login in application dashboard
API return following:
```...
Incorrect response structure
I have been using firecrawl to crawl websites.
Now this has happened very frequently that when I crawl a site of over 100 pages inside it the response structure gets corrupted for some reason. and becomes like:
```...
Concurrency
Is there a way to increase concurrency for crawls? I'm on the highest plan - is this enabled by default?
Alternatively, would it be better to run a query to return URLs and then have the scraper run in parallel?...
Scraping process taking longer than expected for execution
Hi team,
Is someone else also experiencing slowness in the scrape jobs?
I'm seeing the scrape process is not able to scrape 200 odd pages in 15 minutes of time span.
Is this related to firecrawl servers or can it be related to the size of the webpages which I'm trying to scrape?...
Crawl stops at 20 of 2000+ pages
Trying to crawl www.acecqa.gov.au and im seeing a count of 20, but no more. It stops there. Ive tried via API and got 72??? Not sure whats going on. I have adjusted for depth, max pages, and time to load to 5000. Any ideas?
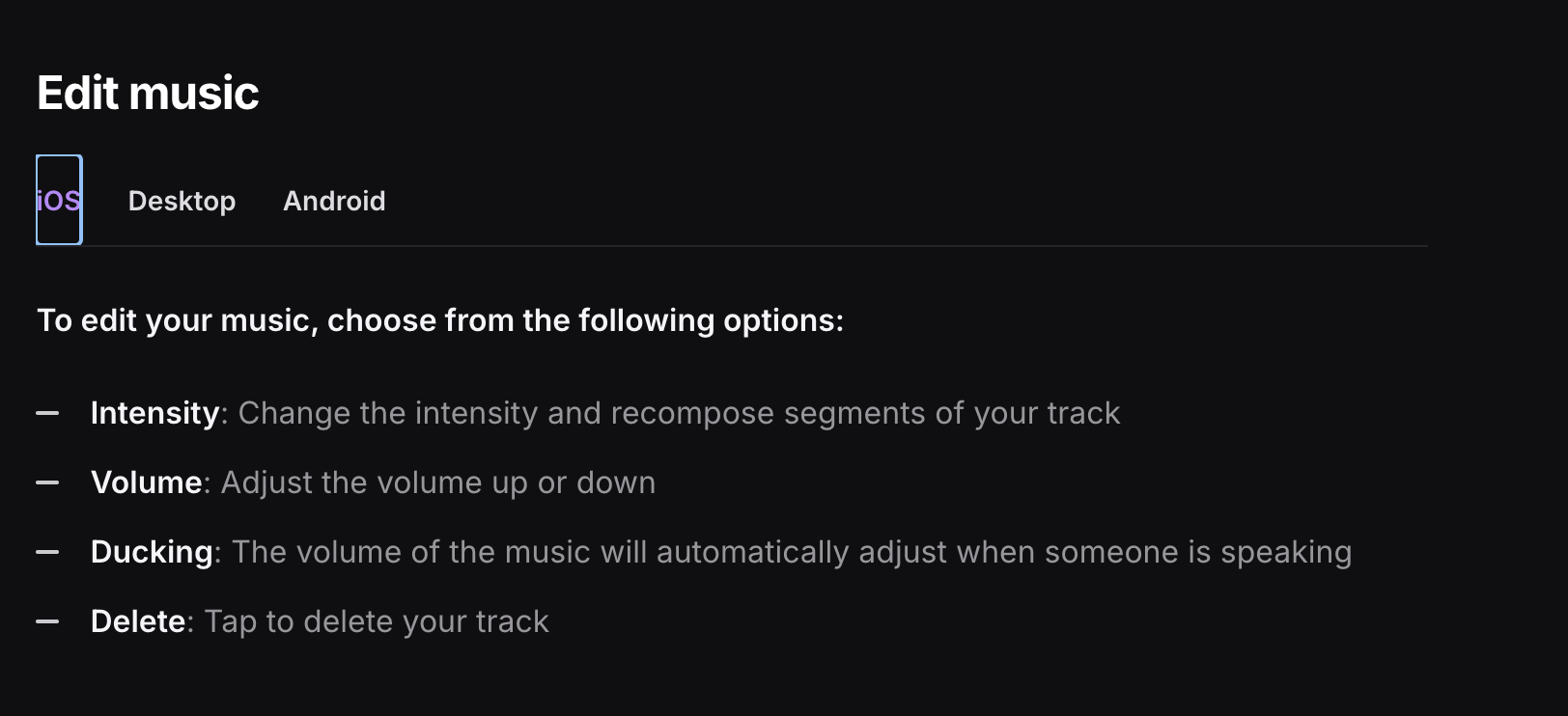
How to get "tabbar dynamic content"
Hi,
How would I go about scraping content behind a tabbar like this? E.g. when clicking Desktop there's other info. Right now, the only scraped in iOS....
Help Needed with Scraping Website Behind Anti-Bot Protection!
I've been trying to scrape this website: https://de.pandora.net/de/charms-armbander/charms/charms-mit-anhanger/bicolor-fahrrad-mit-drehenden-radern-charm-anhanger/763354C01.html
The script works perfectly on my local playground setup, but when I move it to a self-hosted environment, it fails to scrape.
I’ve also added a proxy server to bypass any unauthorized access issues, but I still can't get it to work. Here's the error message I'm encountering:...