Help Needed with Scraping Website Behind Anti-Bot Protection!
I've been trying to scrape this website: https://de.pandora.net/de/charms-armbander/charms/charms-mit-anhanger/bicolor-fahrrad-mit-drehenden-radern-charm-anhanger/763354C01.html
The script works perfectly on my local playground setup, but when I move it to a self-hosted environment, it fails to scrape.
I’ve also added a proxy server to bypass any unauthorized access issues, but I still can't get it to work. Here's the error message I'm encountering:...
Incomplete scraping
I'm trying to capture links from a page's table of contents. I can use pyppeteer with chromium and it returns the entire page contents, but when I use the scrape and crawl, it doesn't. I've tried both the firecrawl API and the self-hosted, neither one provides a complete response.
it doesn't seem like playwright is even being used, but the logging doesn't work very well once everything is running, so I'm having a hard time troubleshooting. I know my playwright service is up, but it doesn't even seem to be used. I have the waitFor page option enabled in my scrape query, but it still doesn't seem to use playwright.
https://docs.venafi.com/Docs/currentSDK/TopNav/Content/SDK/WebSDK/r-SDK-CertificatesModuleProgramming-Interfaces.php?tocpath=Web%20SDK%20REST%7CCertificate%20endpoints%20for%20TLS%7CCertificates%20API%7C_____0...
Error: Supabase Client Not Configured in Self-Hosted Firecrawl
I'm currently self-hosting Firecrawl and running into an issue with configuring the Supabase client. I'm using the example code from the documentation:
import uuid
from firecrawl.firecrawl import FirecrawlApp
...
(YC W24) Inconsistent crawl results between prod and local
I'm trying to test out crawling https://fanfiction.net with a script locally before I switch to the Firecrawl API, however I'm getting different results.
Locally I am just running Firecrawl with the docker setup:
docker compose up from the SELF_HOST.md instructions and default .env variables with no DB.
I am initiating the crawl sequence with the following command and a 200 response is returned with the jobId:...Scraping openai . com
Can't seem to scrape any data from openai urls for example: https://platform.openai.com/docs/models
any work arounds?...
SSL url3 lib
I'm using the following example to test the API but I get the shown error. Any ideas?
https://docs.firecrawl.dev/api-reference/endpoint/crawl...

Firecrawl doesn't seem to crawl everything
I'm trying to run Firecrawl on pytorch's documentation, and I merely get ~15 results with these URLs:
```
https://pytorch.org/docs/stable
https://pytorch.org/docs/stable/distributed.pipelining.html
https://pytorch.org/docs/stable/dynamo/index.html...
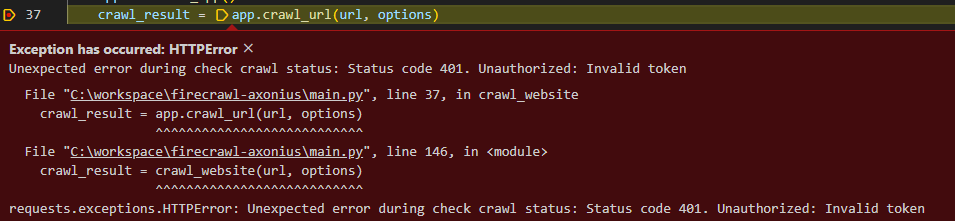
Unauthorized - even after adding the valid token
Has anyone else experienced this, I am getting a 401 error even after adding a valid token. The same token was working a while ago.
is FireEngine live?
Just saw the blog post about the new system. Is this live today or has it already been deployed?
api updates
hi, we are developing a system with your api and we want auto update our requests to the api when the documentation is updated, is it possible?
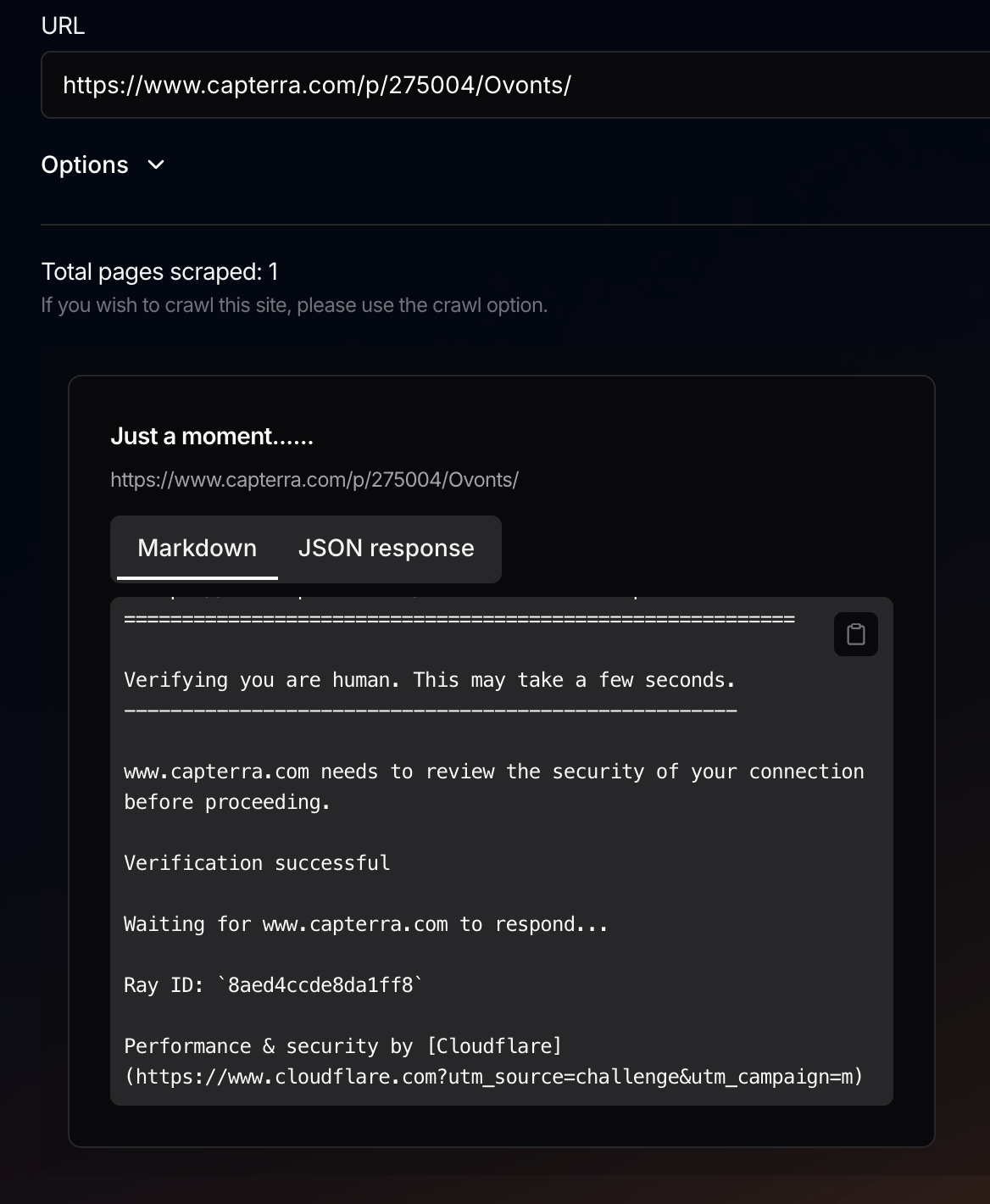
Cloudflare blocking scrape
I'm running into an issue with the /scrape endpoint. It's been running into Cloudflare verification. Can Firecrawl get passed this?
Can I Retrieve Data from an SPA Website?
I am trying to retrieve information from a website built with SPA. However, my attempts have resulted in empty responses. Does your current service support data extraction from SPA websites? If so, could you provide guidance on how to achieve this?
Support
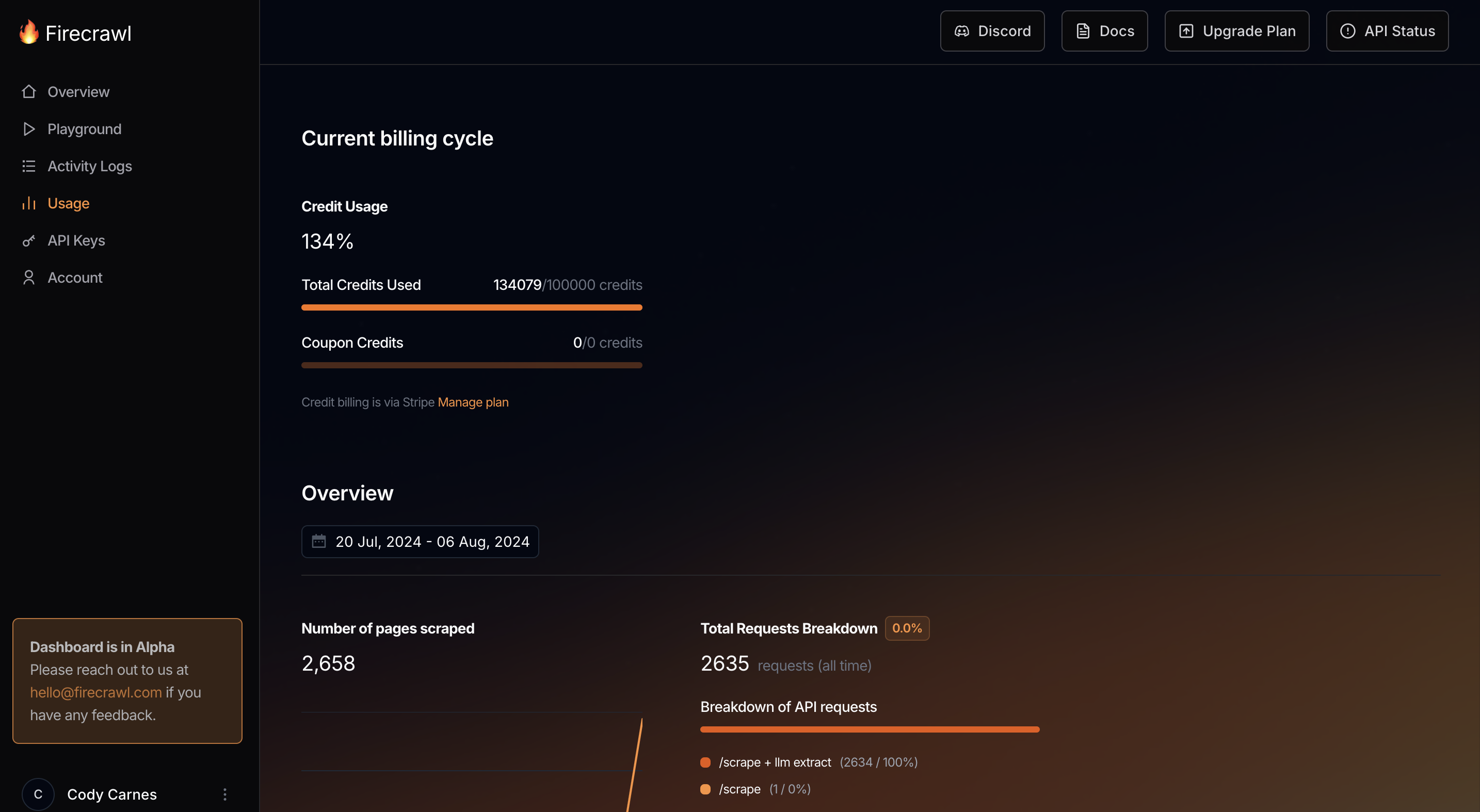
Shit, i thought this meant 100,000 scrapes = 100,000 front page websites scraped 🤦♂️ 🤦♂️ 🤦♂️
I'm using an http api integration to Clay. Any solution to this?
Was just planning on uploading a video tutorial on firecrawl on my linkedin https://www.linkedin.com/in/codycarnes, but if it cant scrape one page only, big waste of creds on my end imo...
Extraction of data from PDF files
Hi team @Adobe.Flash @rafaelmiller ,
Do we have the data extraction feature from PDF files (.pdf) using the FireCrawl Service in place at the moment?...
Crawl job failed or was stopped. Status: Stuck
Is anyone seeing this now?
File "C:\Python312\Lib\site-packages\firecrawl\firecrawl.py", line 288, in _monitor_job_status
raise Exception(f'Crawl job failed or was stopped. Status: {status_data["status"]}')
Exception: Crawl job failed or was stopped. Status: stuck...Can i llm_extract from already scraped markdown seperately?
Is there a a way to seperately use the llm_extract method?
Use Azure Openai for llm extraction
Hi I am using a local instance of firecrawl and tried the extraction function using an Openai model and it worked. I tried to use azure openai by setting up the base url and api key of my azure openai function but I am getting an error(Internal Server Error: Failed to scrape URL. Invalid status code: undefined). How do I resolve this? I want to use the azure instance as my employer pays for it.
Scraping yelp.com
Hey, just wondering how proficient is Firecrawl at scraping yelp.com?
I’m developing a product that relies on scraping businesses profile details from ‘yep.com/biz/{x}’ pages.
Firecrawl works when I test it on a few pages, but I’m worried about it getting blocked by Captcha when deployed at scale.
I’m not so worried about being IP blocked, as it seems that Firecrawl handles this....