How to handle login-required sites with FireCrawl
How to handle login-required sites with FireCrawl (without manual login, by providing username and password)
Can I use firecrawl for this?
I'm trying to get all the reviews from a company in the capterra website.
Is just 1 url.
But you get 20 reviews and then you have to click "Show more reviews" to load other 20. ...
Website with dynamically generated content using Javascript
The website is using a table that is generated by Javascript and when I scrape the website, it only grabs the default set of rows that is generated. When I update the table, the URL doesn't change so the scrapeURL function only picks up the first subset.
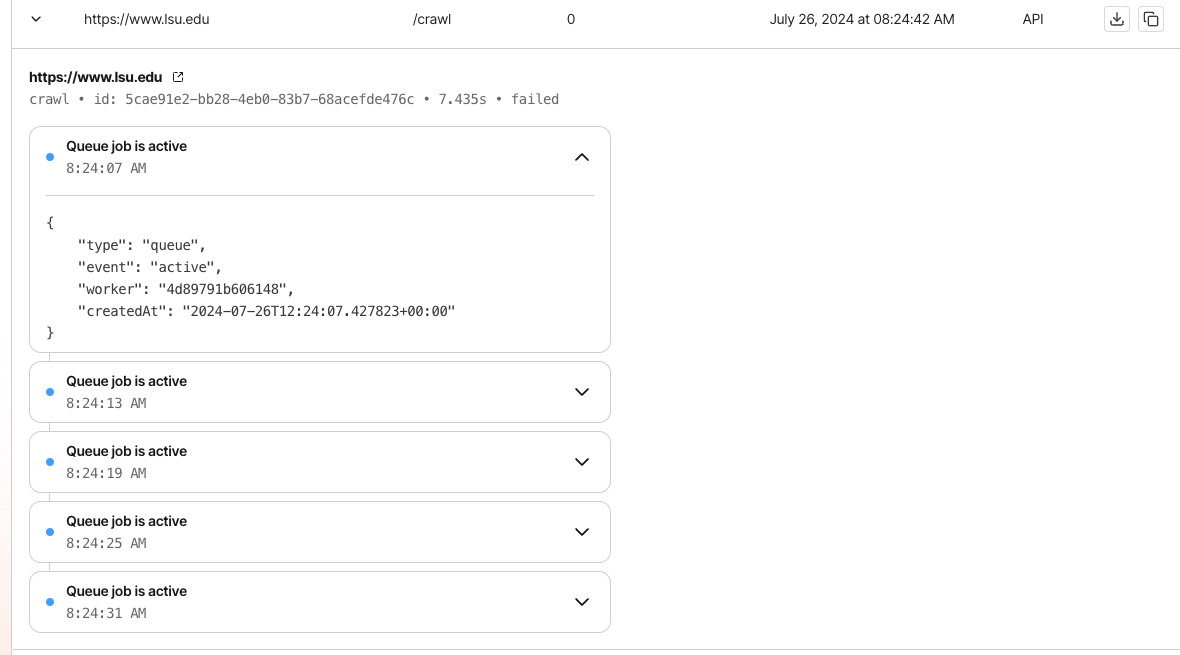
Crawl Job Failed but Activity Log shows active queue jobs
Hi All,
I just discovered that the dashboard is giving some new useful information about crawl jobs but I have a question:
My crawl job came back as failed but when I look in the activity log I see that there are multiple "Queue jobs active"...
Unexpected error during scrape URL: Status code 429. Rate limit exceeded.
Does anyone else also faces the issue of rate limit exhaustion when trying to scrape from a list of URLs?
Despite being on a standard plan which gives 50 scrapes/minute, I'm facing this issue after scraping of just 5 URLs.
Any thoughts what could be the issue here?...
crawl job ID not valid
Guys, another issue.
I now see that I'm unable to check crawl statu for all my jobs.
I have around 10 crawl jobs in my database, with crawl id's stored, but whichever id I use to check crawl status, I got the same error: "Unexpected error occurred while trying to check crawl status. Status code: 404"
...
Python use on local host
I got everything setupped and when i send curl -X GET http://localhost:3002/test i get a Hello, world! response.
Its only when im trying the crawl endpoint:
curl -X POST http://localhost:3002/v0/crawl \
-H 'Content-Type: application/json' \
-d '{...
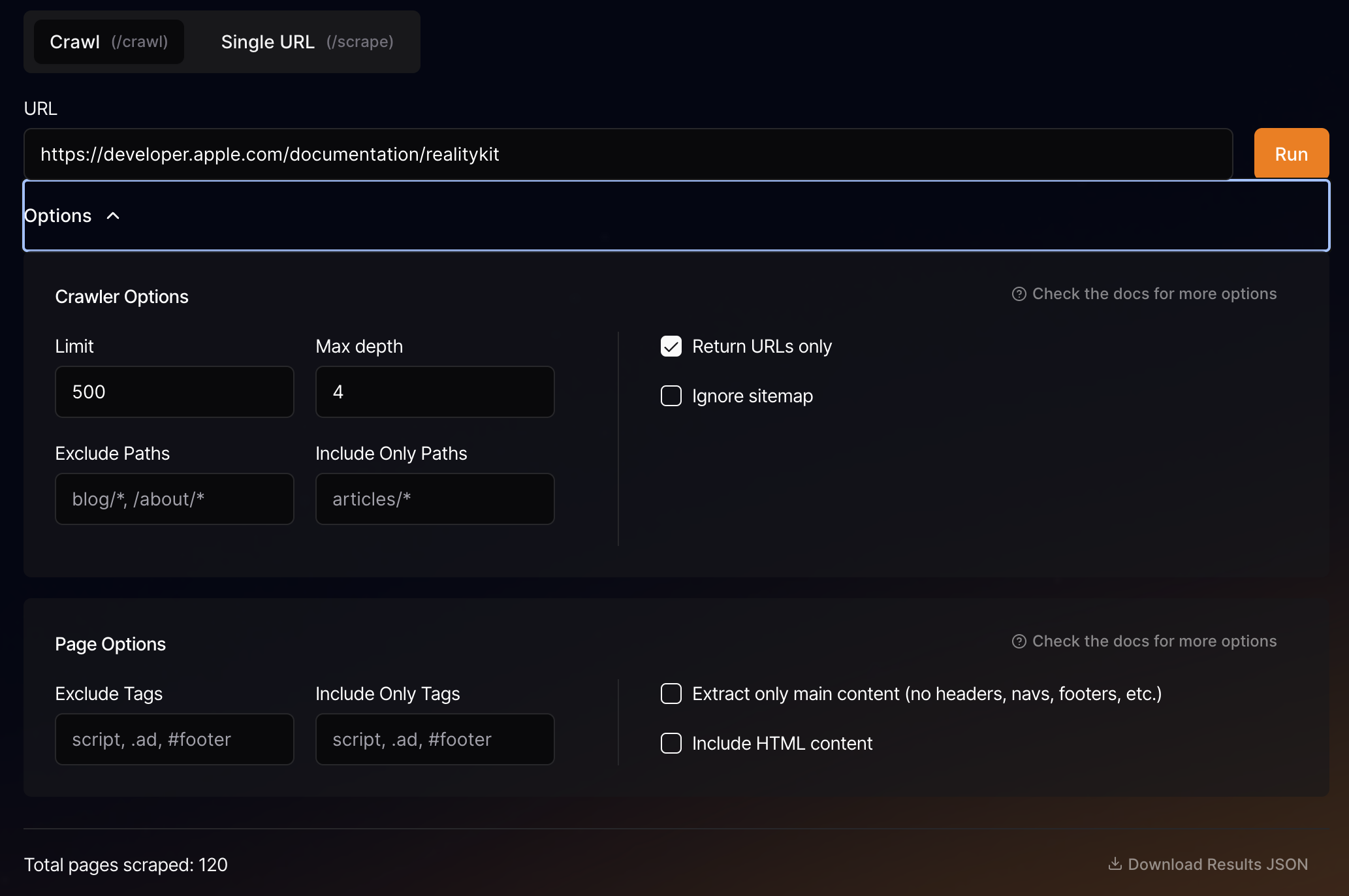
Crawl and scrape https://developer.apple.com/documentation/realitykit
I've been trying to crawl and scrape that link and to include 3 levels deep. But it only works for one level. Any ideas?
Here are my settings:...
Here are my settings:...
Searched for the function public.get_key_and_price_id_2 with parameter api_key or with a single unna
I am trying to deploy FireCrawl and Supabase locally. When requesting the interface with:
curl --location 'http://localhost:3002/v0/scrape' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJzdXBhYmFzZS1kZW1vIiwicm9sZSI6InNlcnZpY2Vfcm9sZSIsImV4cCI6MTk4MzgxMjk5Nn0.EGIM96RAZx35lJzdJsyH-qQwv8Hdp7fsn3W0YpN81IU' \
--data '{...
Ideas for increasing speed? Fast mode?
What are some ways to increase crawl speed? How does fast mode work?
The pageStatusCode is 200, but no content is returned
When i using Firecrawl docker i am unable to scrap website but same not the issue with the cloud version of it and i am getting this error please help on the same.
Error i am getting is: Error: Error: All scraping methods failed for URL: https://rajbeer.fun - Failed to fetch URL: https://rajbeer.fun...
Unauthorized: Invalid token
Hi, I'm working with the python SDK and when I try to crawl the Supabase docs (https://supabase.com/docs) it crawls for 20 minutes or so and then I get this error:
Unexpected error during check crawl status: Status code 401. Unauthorized: Invalid token
I'm sure the api key is working though, because I can crawl other sites with less pages....
linksOnPage
Was wondering for the crawl API , did the response format change i.e. before I remember it would showcase all the urls crawled from a page + markdown content in seperate JSON objects, but now it doesn't and instead I get linksOnPage.
def crawl_ir_url(url: str) -> List[Dict[str, Any]]:
print(f"Initiating the crawl on Firecrawl for URL: {url}")
crawl_json = app.crawl_url(url, params={...
Crawl is not respecting limit crawl option
I set a limit of 500 for my crawl but I find that it keeps crawling beyond 500 pages and I have to interrupt it on my end. My code is below. Am I doing something wrong?
app = FirecrawlApp(api_key=FIRECRAWL_API_KEY)
start_time = time.time()
crawl_url = "https://www.lsu.edu/majors"...
llm_extraction feature
Hello ! is there a way I can use a different model in the llm_extraction feature other than openai ? (trying to use groq)