llm_extraction feature
Hello ! is there a way I can use a different model in the llm_extraction feature other than openai ? (trying to use groq)
Is the url pattern, includes, excludes, using regular expression?
Hi new to firecrawl, anyone know if the url pattern, includes, excludes, using regular expression?
Excluding images in results
Is there any way to exclude images from markdown output?
I think it doesn't provide any valuable context, and it is kind of bloating the results. The highlighted text is the only contextual content in this example.
Or maybe some other tips to get cleaner results? 🙂 Thx in advance...
Help! Receiving 429 Too Many Requests Error Frequently
I've been encountering a persistent issue with my application, and I'm hoping someone here might be able to shed some light on it. My application is frequently receiving a "429 Too Many Requests" response from the server, and it's causing significant disruptions.
Can someone help with this?...
Playground Crawler Not Functioning
Hello FireCrawl Community,
I hope you are all doing well. I have been trying to use FireCrawl for a project, but I am encountering some issues and could use your expertise.
Problem 1: PlayGround No Response...
Looping
I'm stuck in some sort of weird loop when I log into firecrawl. I just subscribed and wanted to do a simple crawl of website. It will not run websites and I can't edit/view old runs in my activity log.
Any ideas?
Cheers...
Zapier Plug-In
How can I pre-set a limit when crawling a webpage from a provided URL in a Zapier workflow? My goal is to import the crawled data to a Notion page, but the scraped information is too long.
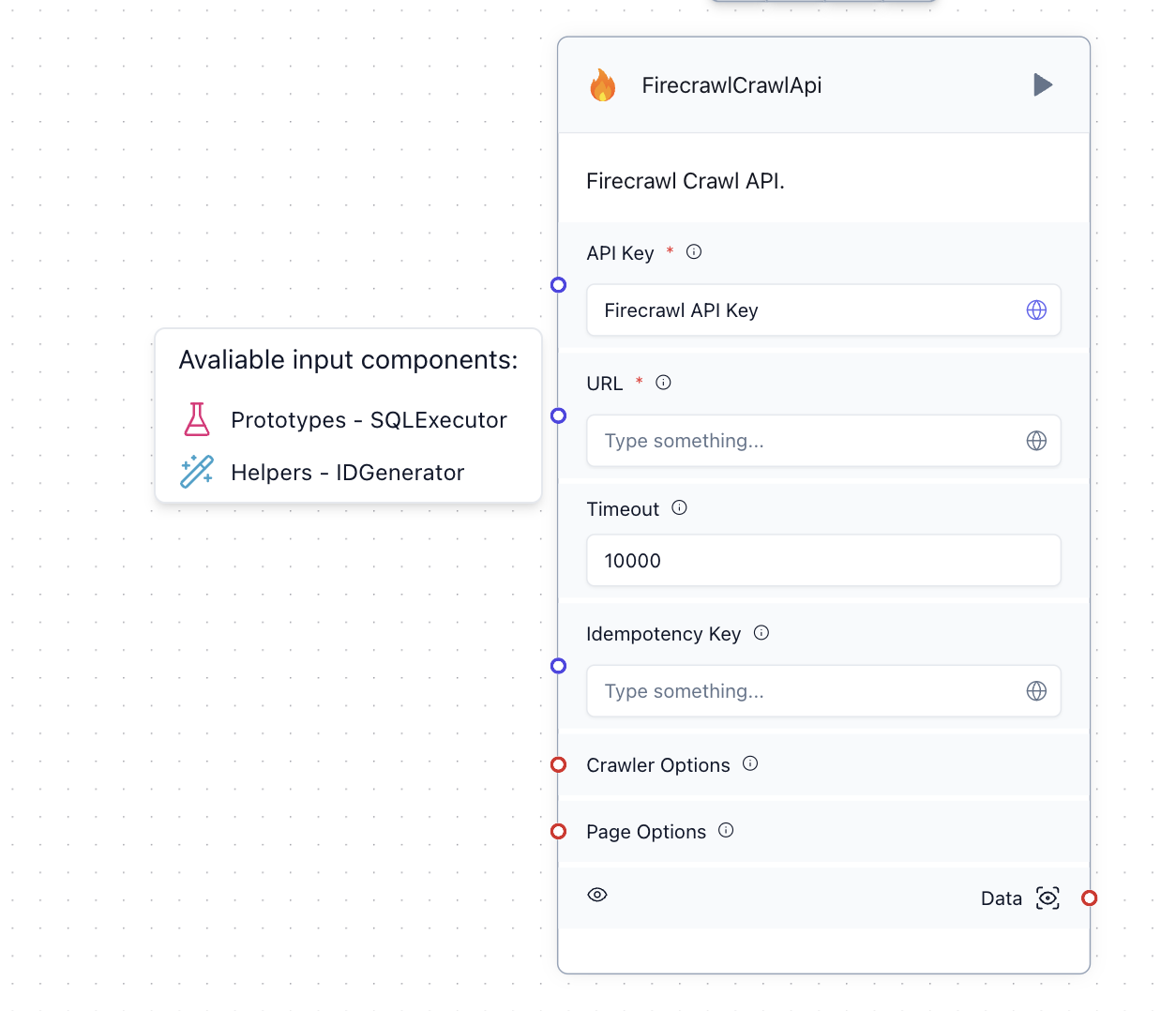
How to make Firecrawl component in langflow URL input field accept text?
Currently it accepts only SQLExecutor and ID Generator, which I find it quite strange, is it a bug or intentional?
how to change search location
is it possible to change the search location of a query? also, can you confirm which search engine is being used?
download individual pages as txt
Would it be possible to download each scraped page as a txt file, so that if i have thousands of scraped pages, we can easily use a select all button to say, download all the scraped pages as individual text file, so that in case there is an update on the client website, we just rescrape that particular url and replace the text file. The text file will be great as most times, there is some manual cleaning of the data.
Firecrawl api not giving output for crawl jobs
Hi folks, is there any outage on Firecrawl side?
Not getting output for the api requests on crawl api end point.
The response says status = WAITING...
detect url and query in a prompt?
Hi @Adobe.Flash @rafaelmiller , i have working with Firecrawl. Even though it works nicely for hard coded urls but wanted to take it one step ahead where i can add url and query in the prompt(str) in the Request Body.... Any use cases out there?
Question about Includes param on crawl
I am trying to crawl specific sections of https://www.lsu.edu by using the includes param. When I do this some of the pages I expect data for are returned but others are not:
e.g. in this code:
crawl_url = 'https://www.lsu.edu/'
params = {...
Firecrawl backend development
Hello guys is the backend provided in github exactly the same as the one user by the hosted service and if yes does it include the new smartCrawl feature . website to api or not yet ? Thanks in advace
No failure reason for crawl job
I am testing out firecrawl for one of our projects but I am finding that the crawl is repeatedly failing but no reason is given for why it failed. I only see this :
timeout param on LLM extract
hi guys, keep running into this error: Request Timeout: Failed to scrape URL as the request timed out. Request timed out. Increase the timeout by passing
timeout param to the request.
works fine on smaller sites, but if trying to scrape a bigger page i hit an error.
can find docs on how to add a timeout param to llmextract ...Scrape a login site
Hello, could be possible to scrape a site that is login protected (mail/username and password) ?
Self-host: unable to scrape/crawl, "Unauthorized" error
Hi all, I'm trying to self-host on a Ubuntu system. Every time I run a crawl or scrape cURL request, I get {"error":"Unauthorized"}{base}, regardless of whatever URL I'm trying to crawl/scrape.
My environment.env is basically a copy/paste of the example, except I've set USE_DB_AUTHENTICATION=false, since I'm not using supabase.
I've also opened port 6379 and 3002 in my firewall, so I can't see why there would be any permissions issues....