Automation of Image Updates for a Serverless Endpoint
Billing history for endpoints not working

Some tasks are consistently in the IN_PROGRESS state
chat template not supported
Completion-style instead of Instruct-style responses
Serverless workers frequent switch to initializing / throttles
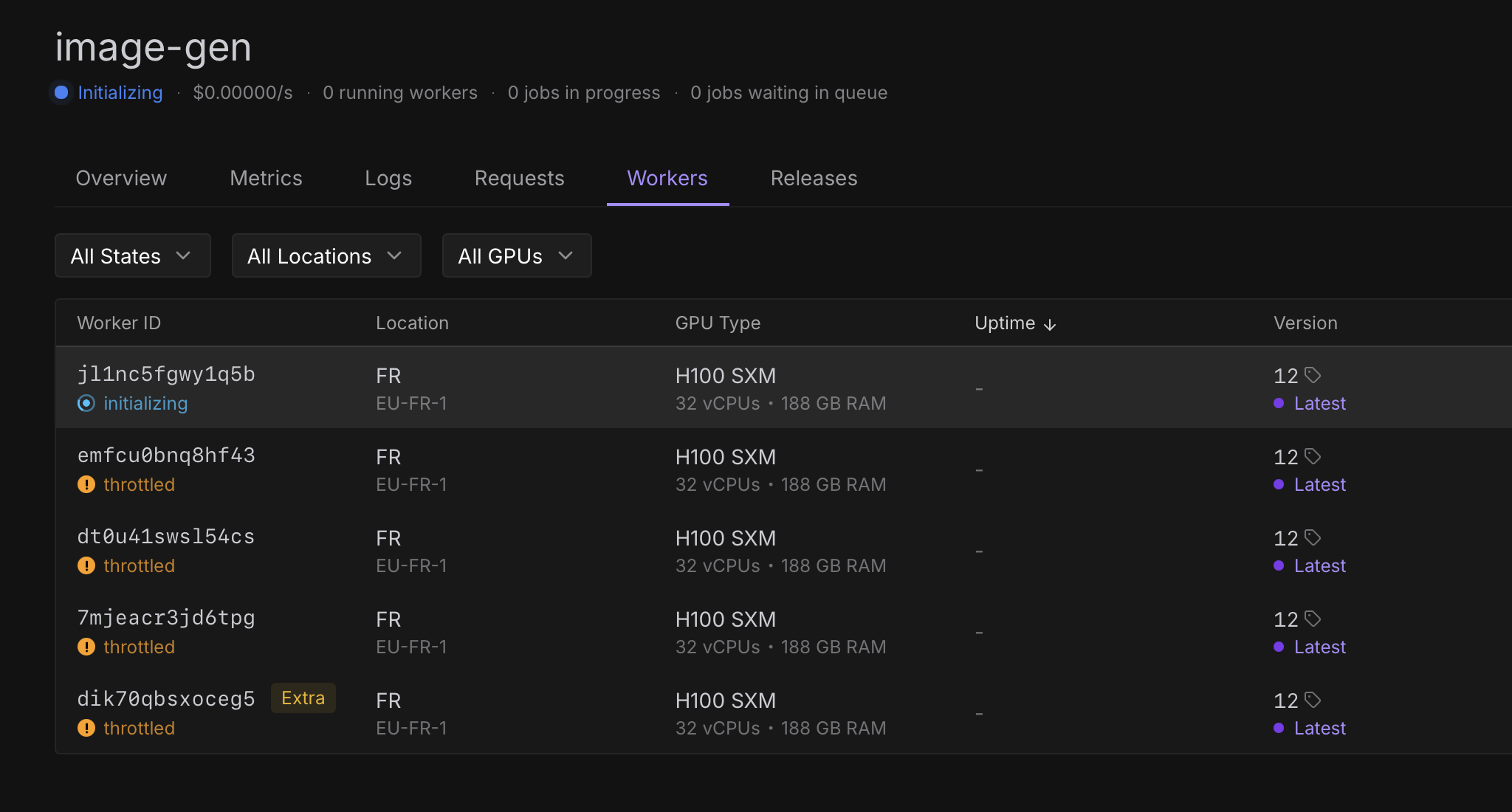
I have over 100 serverless running with different endpoint, and we face this timeout issue.
10:51:35 voiceclone gunicorn[1267959]: Bad Request: /api/audio_to_audio/
Jul 22 10:51:35 voiceclone gunicorn[1267959]: Unexpected error: HTTPSConnectionPool(host='api.runpod.ai', port=443): Max retries exceeded with url: /v2/vn2o4vgw0aes0k/runsync (Caused by ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x74cc5bdf5ba0>, 'Connection to api.runpod.ai timed out. (connect timeout=3600)'))
Jul 22 10:51:35 voiceclone gunicorn[1267959]: - - [22/Jul/2025:05:51:35 +0000] "POST /api/audio_to_audio/ HTTP/1.0" 400 0 "-" "Proxyscotch/1.1"
10:51:35 voiceclone gunicorn[1267959]: Bad Request: /api/audio_to_audio/
Jul 22 10:51:35 voiceclone gunicorn[1267959]: Unexpected error: HTTPSConnectionPool(host='api.runpod.ai', port=443): Max retries exceeded with url: /v2/vn2o4vgw0aes0k/runsync (Caused by ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x74cc5bdf5ba0>, 'Connection to api.runpod.ai timed out. (connect timeout=3600)'))
Jul 22 10:51:35 voiceclone gunicorn[1267959]: - - [22/Jul/2025:05:51:35 +0000] "POST /api/audio_to_audio/ HTTP/1.0" 400 0 "-" "Proxyscotch/1.1"
Intializing for more than 20 + hours
How to write to network by API?
Geo-Redundant network storage
How to prevent removal of container
disk quota exceeded: unknown
error writing layer blob: rpc error: code = Unknown desc = close /runpod-volume/registry.runpod.net/[redacted-project-path]/ingest/[hash...]/ref: disk quota exceeded: unknown
error writing layer blob: rpc error: code = Unknown desc = close /runpod-volume/registry.runpod.net/[redacted-project-path]/ingest/[hash...]/ref: disk quota exceeded: unknown
Increase workers for serverless
Platform usage for jailbreak research
Format of runpod.create_endpoint gpu_ids
Runpod not detecting dockerfile
error on running moonshotai/Kimi-K2-Instruct
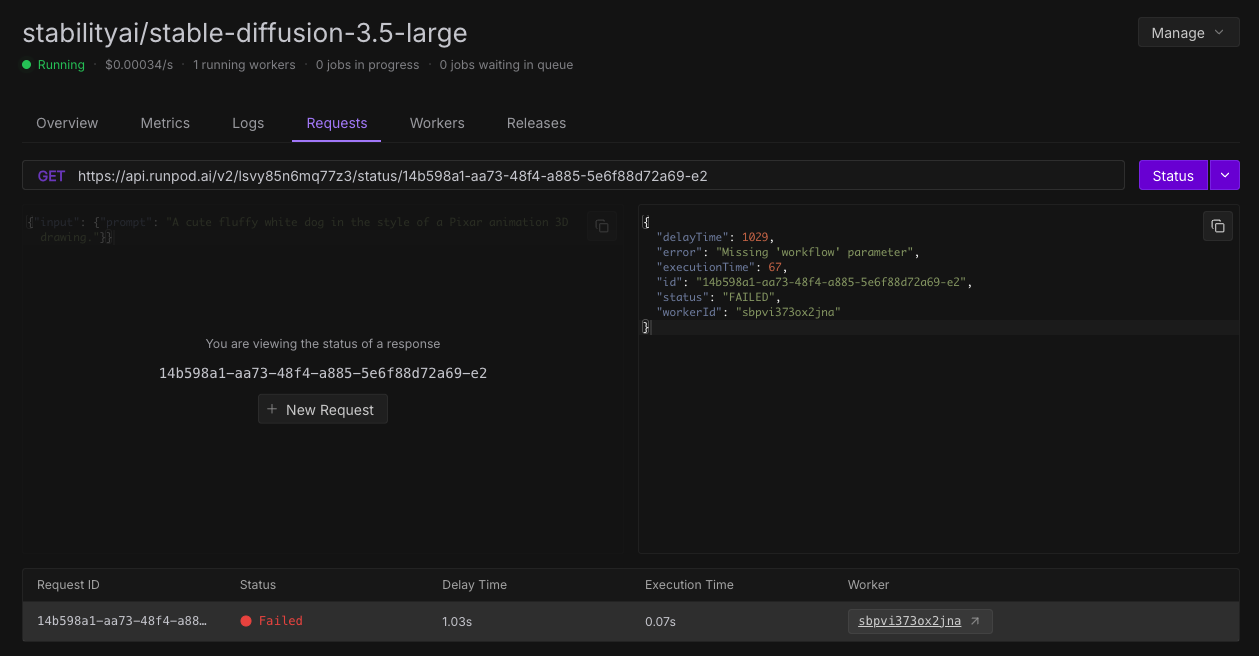
Need Help: Stable Diffusion 3.5 large Deployment Error on RunPod
ComfyUI API