ComfyUI API
Possible bug with environment variables
Load balancing to death?
Serverless not running with NIM - NVidia custom models
Serverless API - It's not returning visually what it says in the response data
Serverless Docker AWS ECR failed connections still charges requests until timeout
Endpoint ID changing after Pulumi deployment
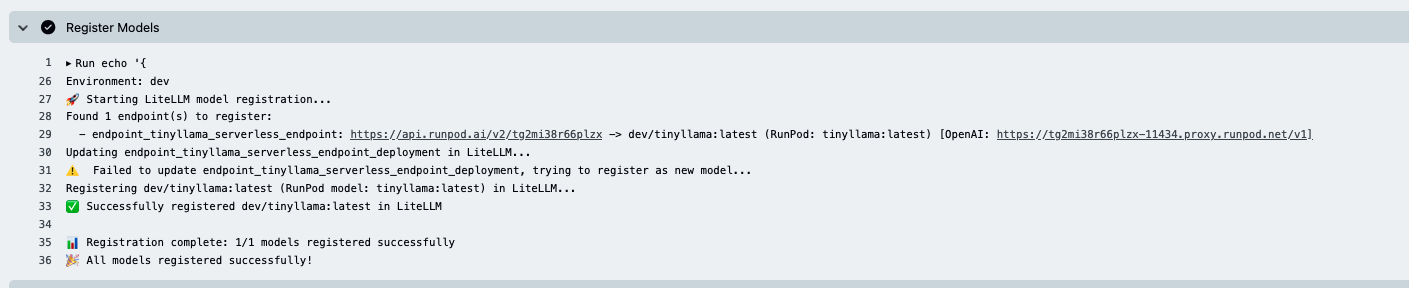
ComfyUI Worker: FLUX.1 dev & Network Volume Setup Questions
CRITICAL: Runpod charging more unfairly
2025-07-10 20:37:18.701 -> START
2025-07-10 20:37:24.854 -> END
2025-07-10 20:37:18.701 -> START
2025-07-10 20:37:24.854 -> END
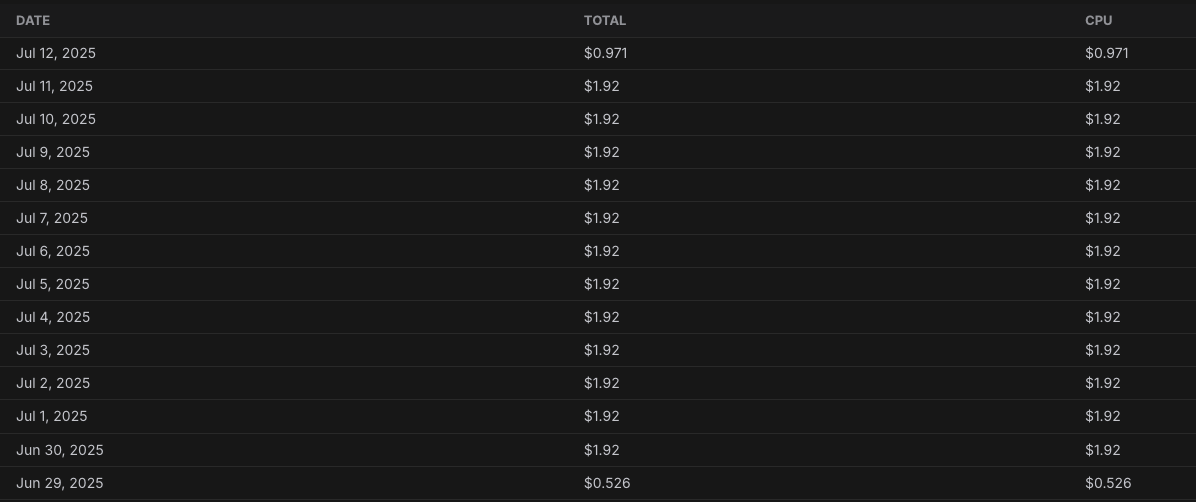
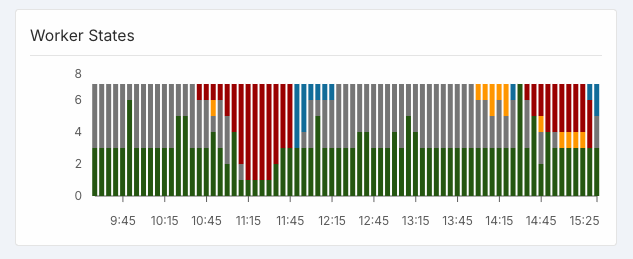
Unhealthy workers keep sabotaging production
How Do You Speed Up ComfyUI Serverless?
Akira: Ghosts in KS2 .. spooky...
Unable to edit template due to invalid container image name even it is valid
us-central1-docker.pkg.dev/ai-platform/speech/speech-to-text:3c7f537
us-central1-docker.pkg.dev/ai-platform/speech/speech-to-text:3c7f537
RunPod Worker Infinite Loop
Ollama Worker Keeps Redownloading Model
max_num_seqs
TypeError: '<' not supported between instances of 'int' and 'str'...
Does anybody experiencing outages tonight?
Choosing GPU based on task data
How do people serve large models on Runpod Serverless?
Hunyuan or LTX on Serverless Endpoints?