Running Workers Not Shutting Down & Incurring Charges
Runpod setting my workers to 0
Unstable Serverless GPU performance (Mostly too slow)
OLLAMA docker from docker hub.
CPU usage rises to 99% even though no processing is being performed
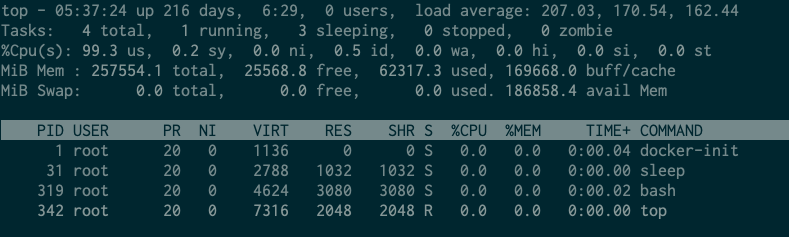
Can I use a stronger single core cpu for the serverless
Streaming responses Serveless Endpoint
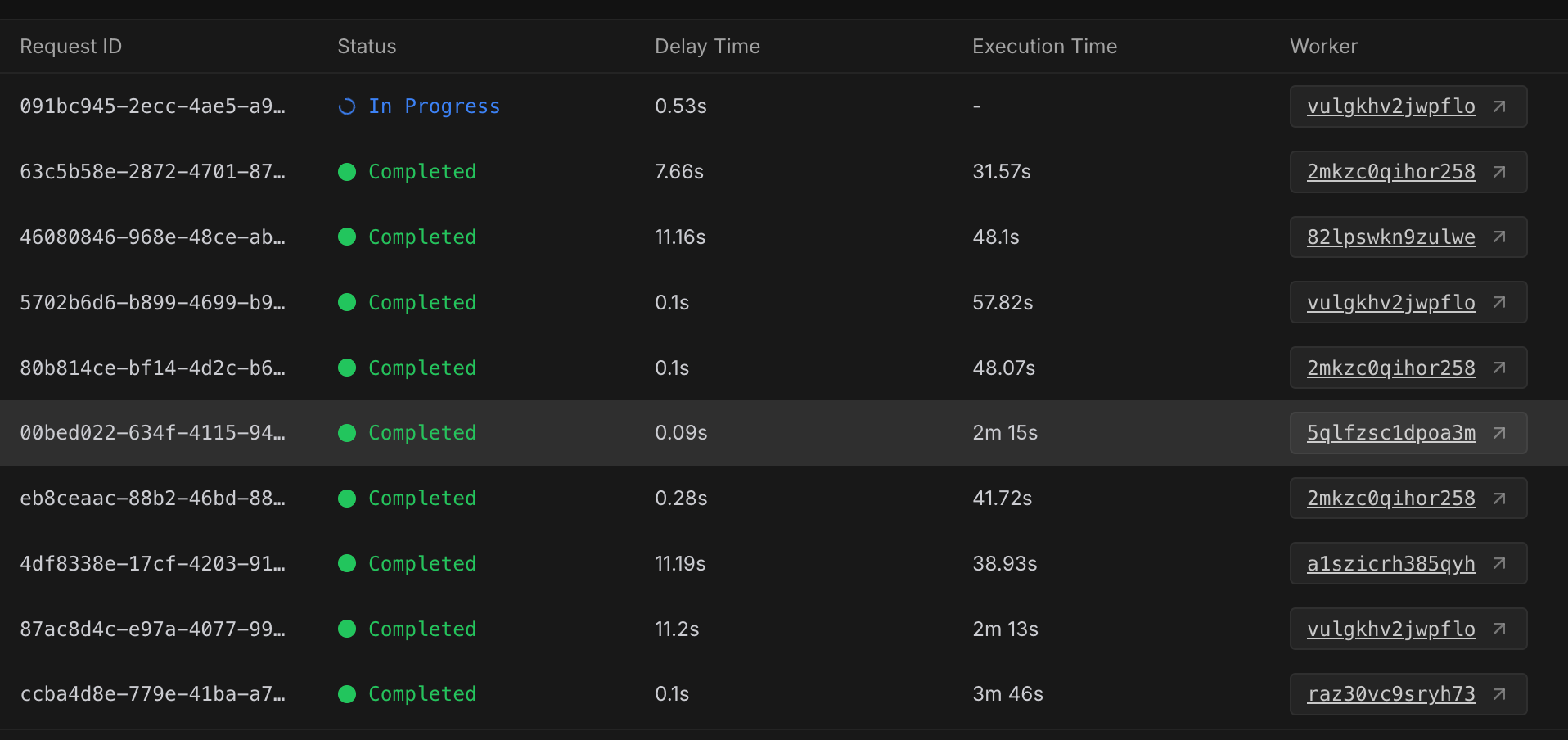
Bad workers are lurking. Clear differences in processing speed
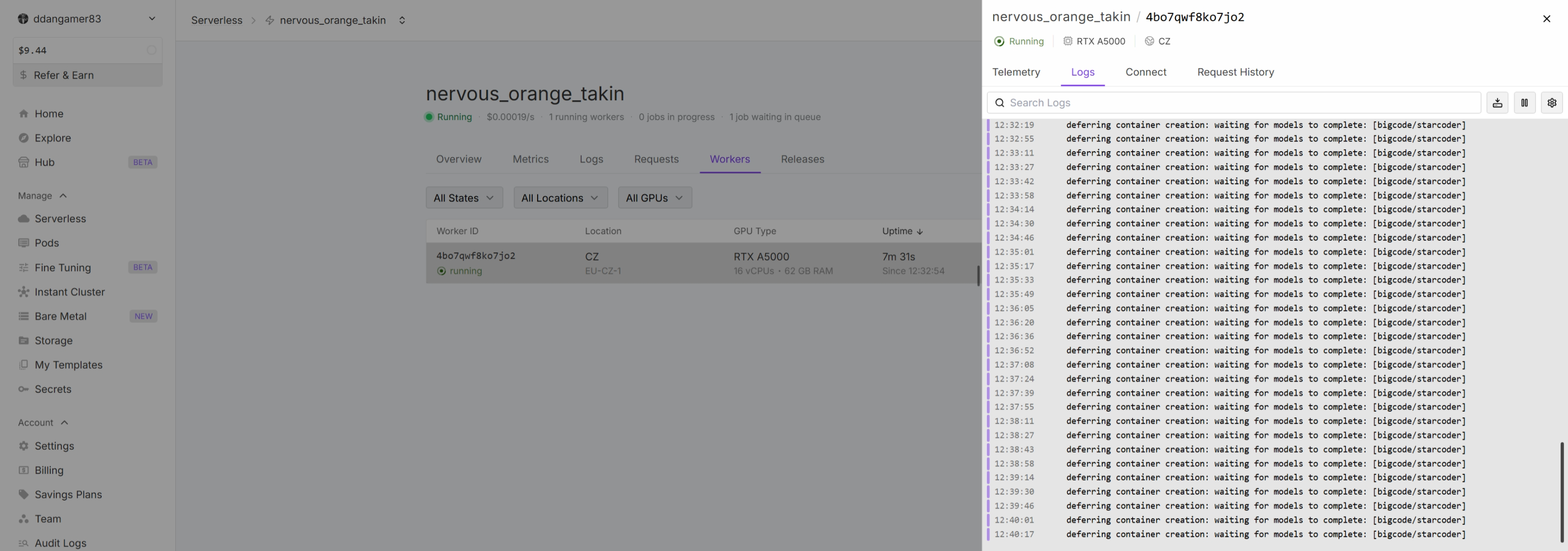
Comfy worker for custom docker is taking too much time
Still waiting
Failed to return job results.
{"requestId": "563f49bc-fe15-466f-a91c-99911ab7b100-e2", "message": "Failed to return job results. | Connection timeout to host https://api.runpod.ai/v2/idxmpy4kkpl9d1/job-done/qombpdb0mbxpew/563f49bc-fe15-466f-a91c-99911ab7b100-e2?gpu=NVIDIA+GeForce+RTX+4090&isStream=false", "level": "ERROR"}
{"requestId": "563f49bc-fe15-466f-a91c-99911ab7b100-e2", "message": "Failed to return job results. | Connection timeout to host https://api.runpod.ai/v2/idxmpy4kkpl9d1/job-done/qombpdb0mbxpew/563f49bc-fe15-466f-a91c-99911ab7b100-e2?gpu=NVIDIA+GeForce+RTX+4090&isStream=false", "level": "ERROR"}
Serverless GPU is unstable
CUDA error: CUDA-capable device(s) is/are busy or unavailable
Unacceptable downtime
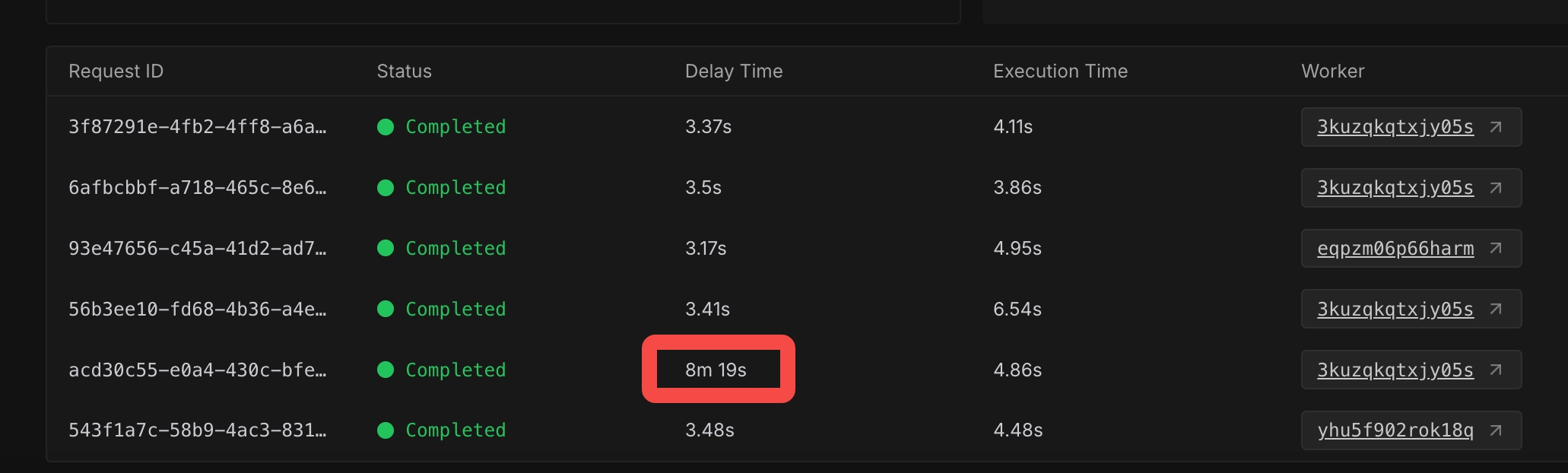
How to increase the idle time >3600s?
Can't set enviornment variables
How to manage frequent redownloads of large docker images ?
MD5 mismatch error when running aws s3 cp
aws s3 cp --region EUR-IS-1 --endpoint-url https://s3api-eur-is-1.runpod.io/ ./flight-2-1.JPG s3://<my-bucket-id>/flight-2-1.JPG I get the following error: An error occurred (BadDigest) when calling the PutObject operation: MD5 mismatch
Anyone that can tell me what I am doing wrong?...ComfyUI server (127.0.0.1:8188) not reachable after multiple retries