Prompt formatting is weird for my model
/run or runsync, the payload should be:
```json
{
"input": {
"messages": [...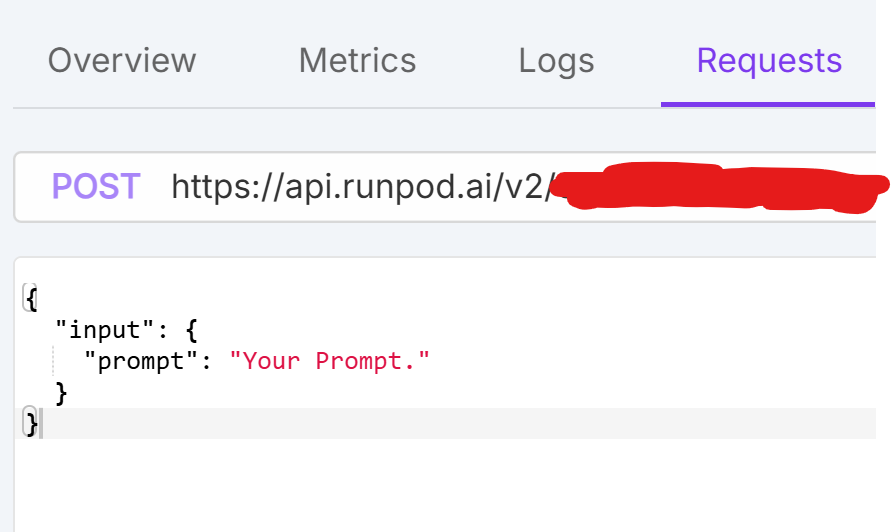
Output is 100%, but still processing
runpod.serverless has no attribute progress_update (runpod_python 1.7.12)
runpod.serverless has no attribute "progress_update". I looked into it, and it seems that it's defined in rp_progress, which is not being exposed as a module? is this intentional? is there a different feature that exposes the same functionality that is undocumented, or am I doing something wrong? It's been the first time in forever that I did any python aside...How much is payment? How to pay?
Default stable diffusion preset doesn't work on rtx 5090 serverless
In Faster Whisper Serverless, how to get transcribe result?
When serverless uses a worker, is that worker shared between other serverless endpoints?
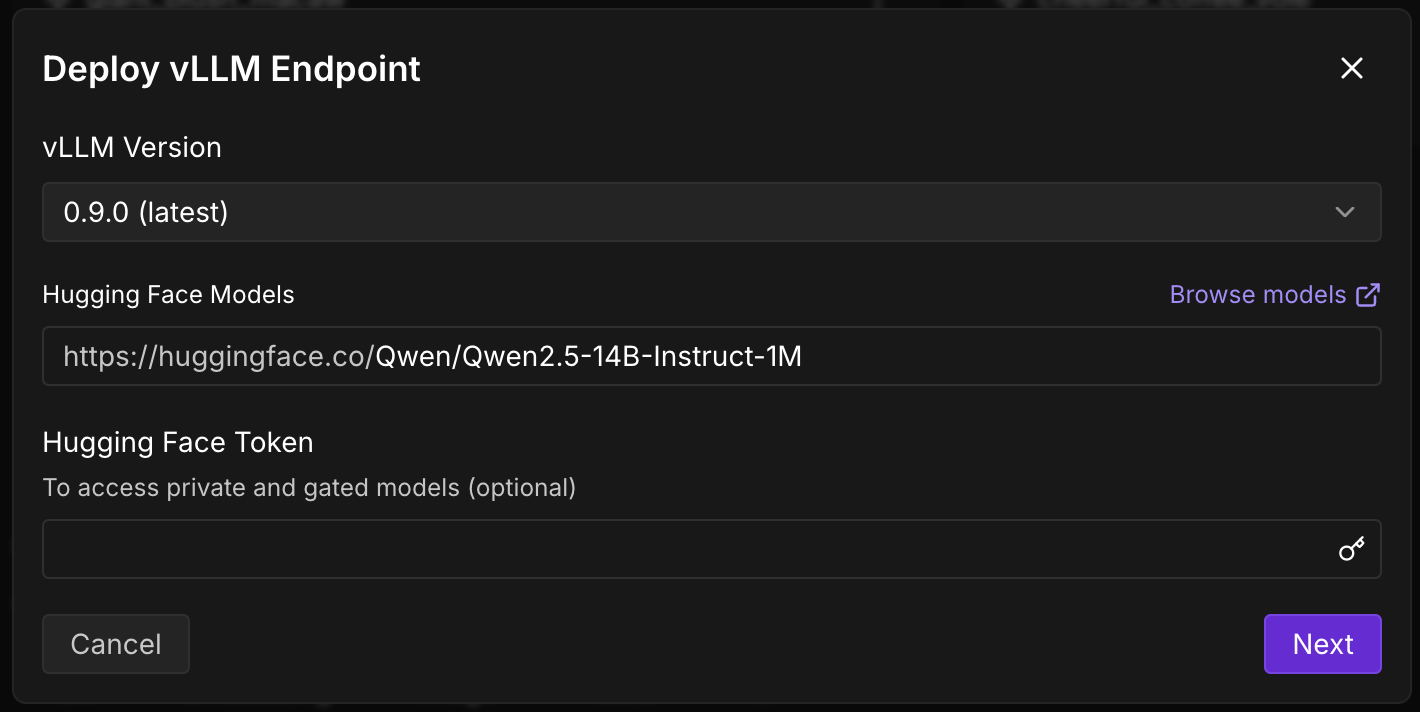
Can't deploy Qwen/Qwen2.5-14B-Instruct-1M on serverless
Unhealthy machines
Is /workspace == /runpod-volume ?
Qwen2.5 0.5b worked out of box and Qwen3 0.6b failed
ValueError: The checkpoint you are trying to load has model type `qwen3` but Transformers does not recognize this architecture. This could be because of an issue with the checkpoint, or because your version of Transformers is out of date.
ValueError: The checkpoint you are trying to load has model type `qwen3` but Transformers does not recognize this architecture. This could be because of an issue with the checkpoint, or because your version of Transformers is out of date.
Not possible to set temperature / top_p using Serverless vLLM via quick deploy?
temperature / top_p) from a model's generation_config.json if present. (see here: https://github.com/vllm-project/vllm/issues/15241). To override this you, have to pass --generation-config when starting the vLLM server.
Because RunPod's worker-vllm (https://github.com/runpod-workers/worker-vllm) doesn't expose an environment variable to pipe through a --generation-config value, does this mean it's not possible to change the temperature or top_p for any model deployed by Serverless vLLM quick deploy that has a generation_config.json file e.g. all the Meta Llama models?
And the solutions is a customer Docker image / Worker?...Stuck on initializing
No available workers
Is it okay to use more than 10+ workers using 5090 or we will experience inconsistencies?
RAM and CPU
Are Docker images cached?
Why is this taking so long and why didn't RunPod time out the request?