Achieving concurrent requests per worker
How to change the github repository in my serverless.
serverless does not cache at all
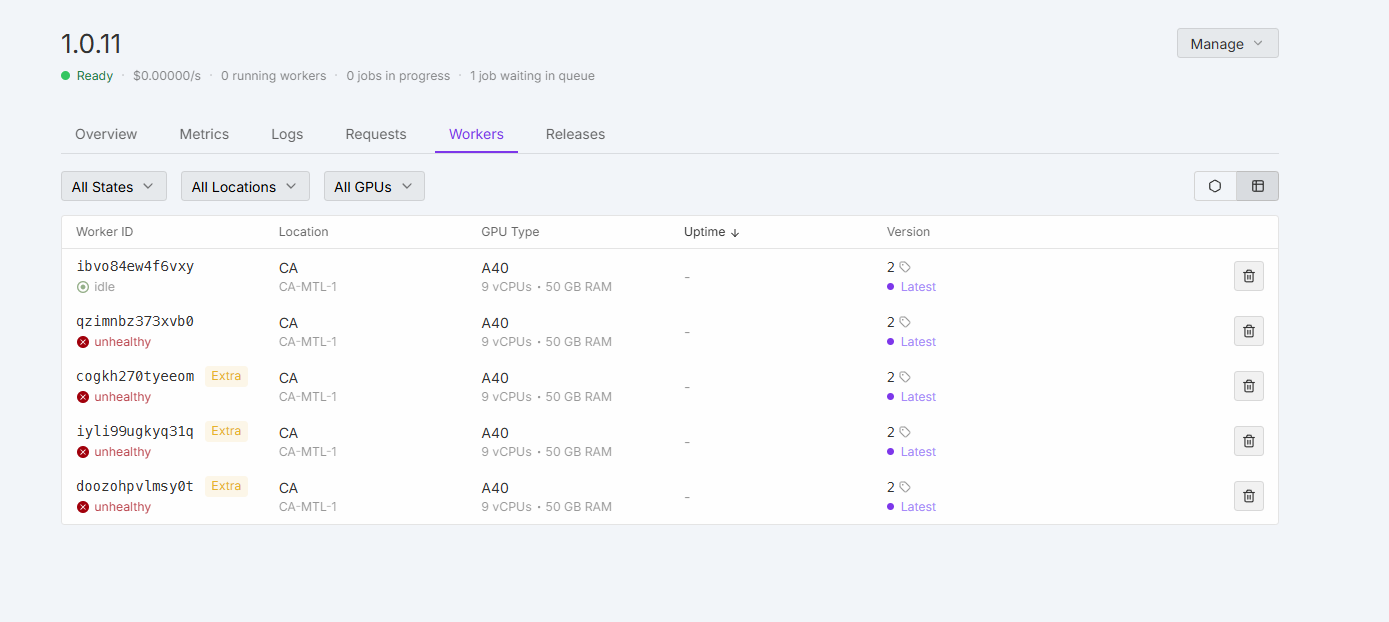
Updated serverless workers are all unhealthy
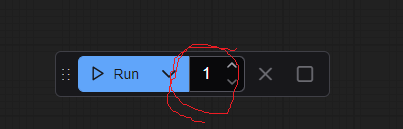
how to change batch count in serverless comfyUI?
limit_mm_per_prompt removed again?
Serverless VLLM batching
Deploy a standard http server?
Where is the 250ms cold start metric that you advertised derived from?
Load balancing + scaling
H100 Replicate VS RunPod
serverless endpoints are BUGGED since yesterday
Is it possible to change the endpoint ID after deployment?
Help Needed: Chatterbox TTS Server on Runpod Serverless - Jobs Stuck, Handler Not Reached
How do I run Qwen3 235B Q5_K_M Using vLLM
github.com/Zheng-Chong/CatVTON
need help with serverless flux lora training using ai-toolkit
Best,
Jesse...
Need help with Serverless Dreamshaper XL Worker Unstable/Throttle Issue.
API Docuementation of Preset Models like Faster Whisper