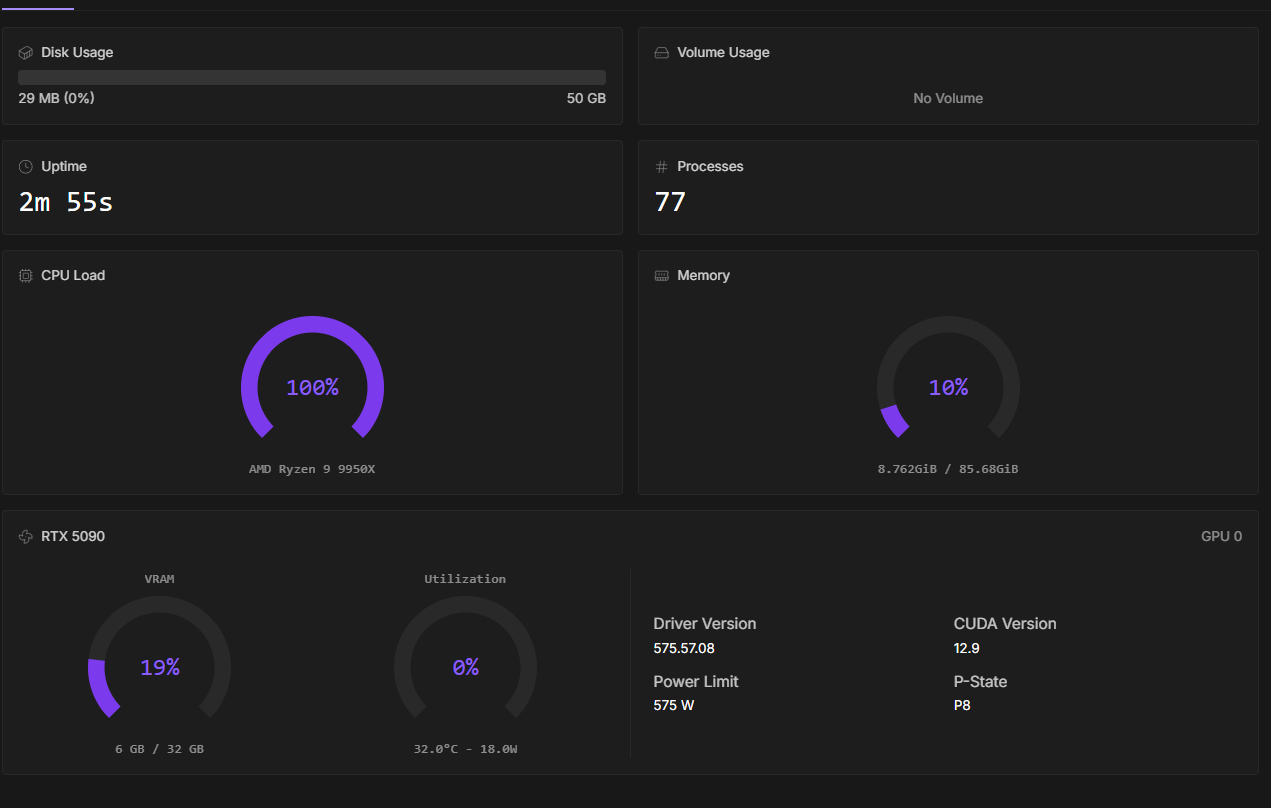
serverless down ?
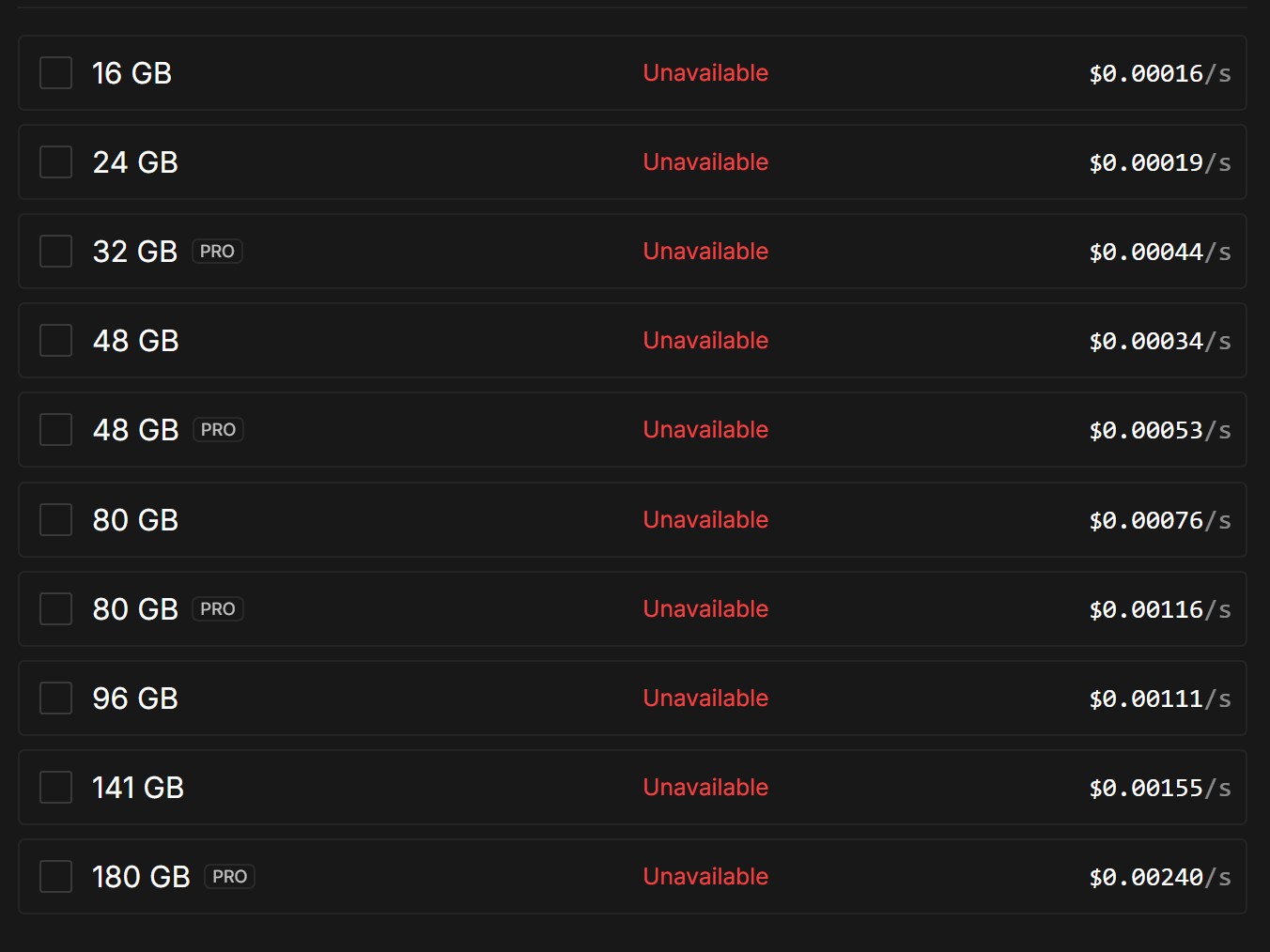
Please resolve this really urgent issue.
No workers available in EU-SE-1 (AMPERE_48)
s7gvo0eievlib3 hours ago with storage attached. Build was fine and release was created. But I don't have any workers assigned. The GPU is set to AMPERE_48 of which it said High Supply. What am I doing wrong and how do I fix this?Can't load load model from network volume.
MODEL_NAME, but even when setting up the template I got this error:
Failed to save template: Unable to access model '/workspace/weights/finexts'. Please ensure the model exists and you have permission to access it. For private models, make sure the HuggingFace token is properly configured.
Failed to save template: Unable to access model '/workspace/weights/finexts'. Please ensure the model exists and you have permission to access it. For private models, make sure the HuggingFace token is properly configured.
Need more RAM but not more VRAM in serverless endpoints
Are the Serverless Endpoints run on the "Secure Cloud" with 3-4 tier data centers?
Questions on preventing model reloads in Serverless inference
vLLM serverless not working with hugginface model
ComfyUI workers don't find my diffusion model
* UNETLoader 37:
- Value not in list: unet_name: 'wan2.2_ti2v_5B_fp16.safetensors' not in []
Output will be ignored
* UNETLoader 37:
- Value not in list: unet_name: 'wan2.2_ti2v_5B_fp16.safetensors' not in []
Output will be ignored
Download huggingface models that require hf-token during build time?
ReadTimeoutErrors in US-IL-1
'ReadTimeoutError("HTTPSConnectionPool(host='api.runpod.ai', port=443): Read timed out. (read timeout=8)")': /v2/6inskfdqe9z510/ping/ll0c30myrjn82o?gpu=NVIDIA+GeForce+RTX+4090&job_id=19f37b9a-f53e-4fea-b281-f7204b16df13-e2&runpod_version=1.7.13
For this particular run, the job ID is 19f37b9a-f53e-4fea-b281-f7204b16df13 and the worker ID is ll0c30myrjn82o (4090 in US-IL-1) in case someone can investigate....Does the documented rate limit also apply to Load balancing endpoints (e.g. FastAPI)?

Can't run gpt-oss:120b on ollama
S3 access for EU-RO-1 has been down for days but no update from the team?
I have 1 query/worker but my workers are stucks today
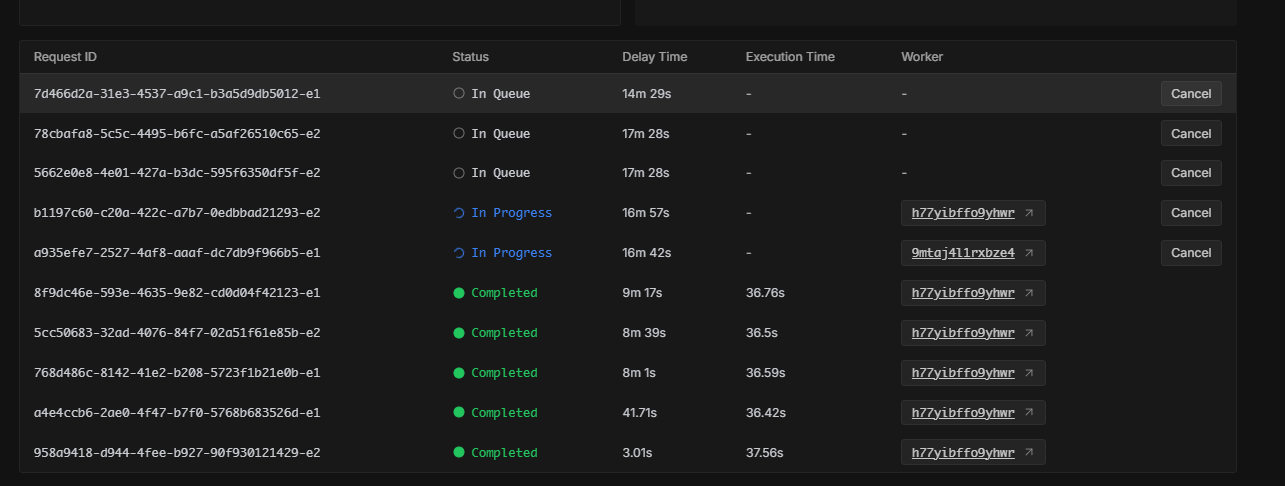
Unable to upload large files into network volume using aws s3 command
Adding Hugging face access token to vllm serverless endpoint
Accessing Network Volume via S3 Returns "error"
Running 30 a100 workers
Deploying blender on serverless doesn't utilize GPU