ComfyUI template extra path bug
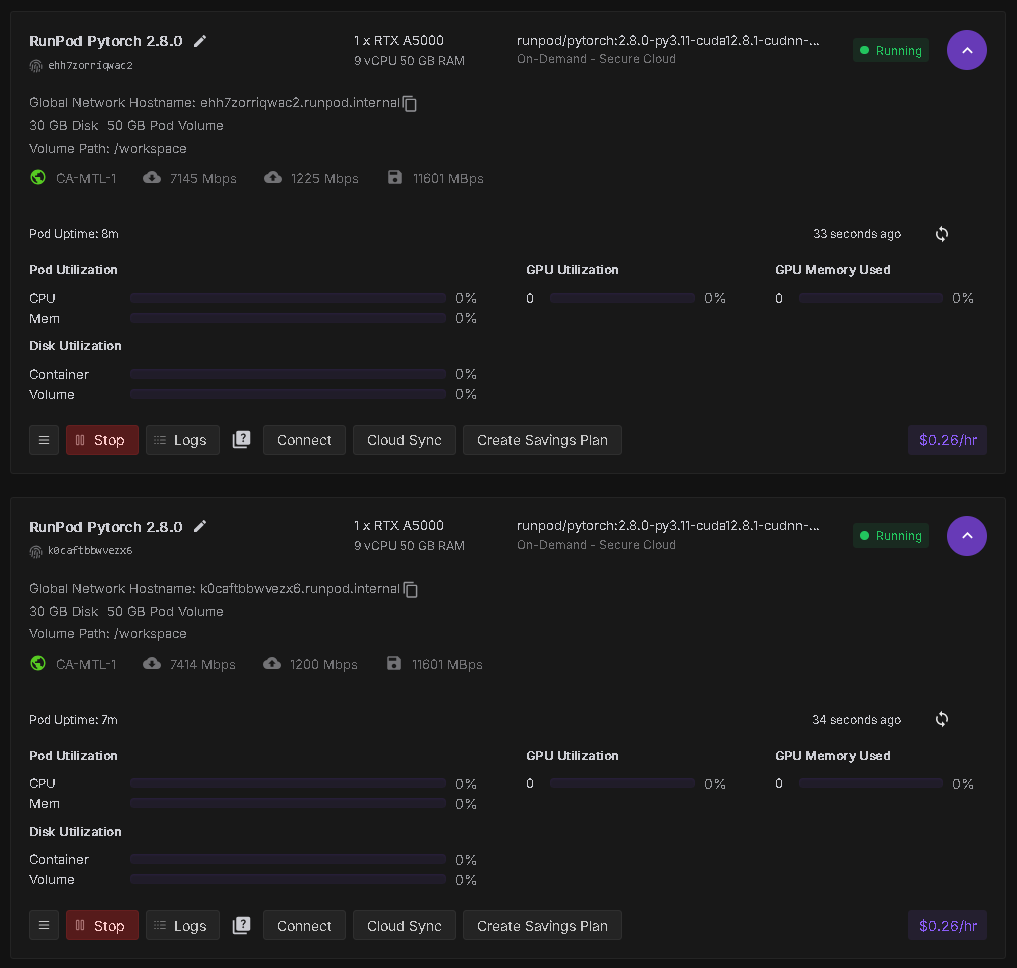
Network Volume Utilization
createing a pod in japan through sdk
How in the hell do I get my files off my pod... ima pull my hair out...
Being charged for inaccessible pod
Having issues connecting on desktop
Site-to-Site VPN
Official template fail to start
Python venv setup in my network storage doesn't work after spinning up another pod
Cannot connect to web terminal with dual 4090s
POD deleted despite Network volume
Trying to Connect to Pod Storage with SCP on WinSCP
How do I transfer files into my network volume? Is that the /workspace folder on my pod?
Template issues
Is it possible to do GPU profiling on Runpod's pods
Global Networking - Official Template - Not Working
Creating a pod using a Docker image built via Serverless GitHub integration
Slow Model Loading - Solutions
all installed py libs are consistent except yfinance
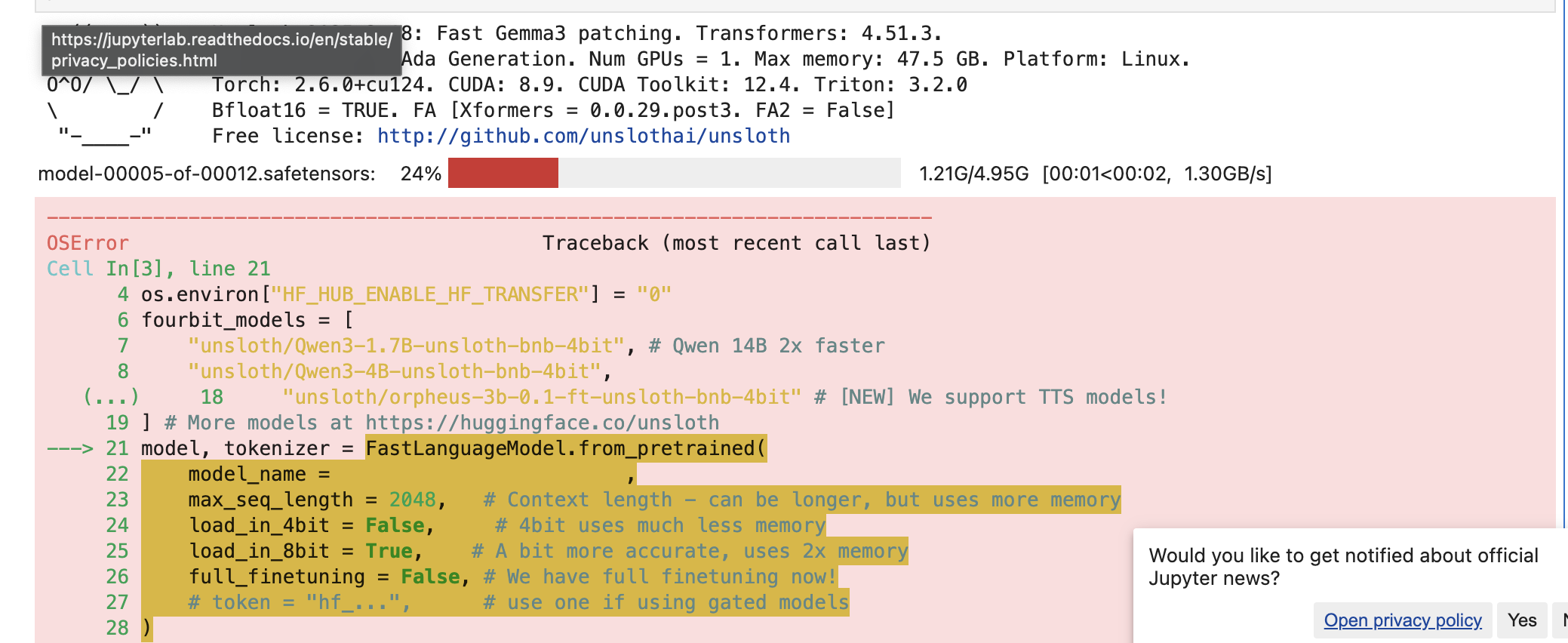
Unable to download huggingface model in runpod . facing issue : OSError