Whats going on jupyter lab on pods
Wan2.2 generation is too slow
Can't SSH into fresh pod
CUDA NO WORKY?
Error response from daemon: container a94707bd5f391d6a3f25d13f3ba02a425757bdbecfcb7de3b1169ddda866d434 is not running
Error response from daemon: container a94707bd5f391d6a3f25d13f3ba02a425757bdbecfcb7de3b1169ddda866d434 is not running
intermittent network/proxy issue on the path to Runpod’s S3 API
-- RUNPOD.IO --
Infinity Fabric networking for multi AMD GPUs pod
Pod auto-moving if no GPU available
Runpod terminal crash
Volumn
Started Pod takes a long time and uses no RAM on VLLM GPT-OSS-120B
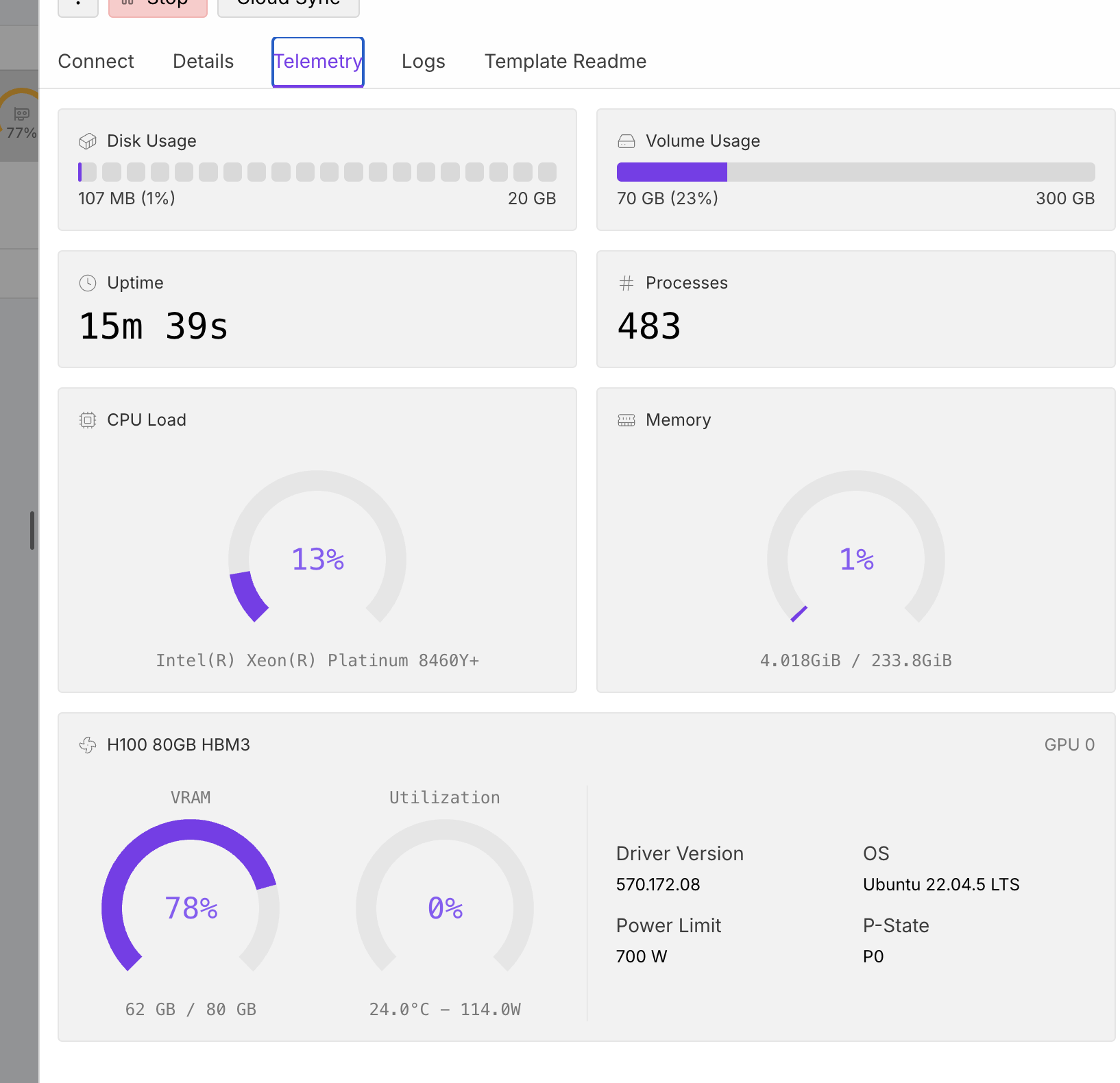
Pod start time varies although I'm using the same docker image.
RTX 5090 permanently unavailable on US-CA-2?
Network Volume + RTX PRO 6000 not starting on EU-RO-1
HELP!ComfyUI defaults to CPU on pod startup but switches to GPU after Comfyui Manager restart
Is it possible to lauch a Runpod official image while specifying available shm (shared memory)?
Help meee!! Kohya SS GUI template help needed!
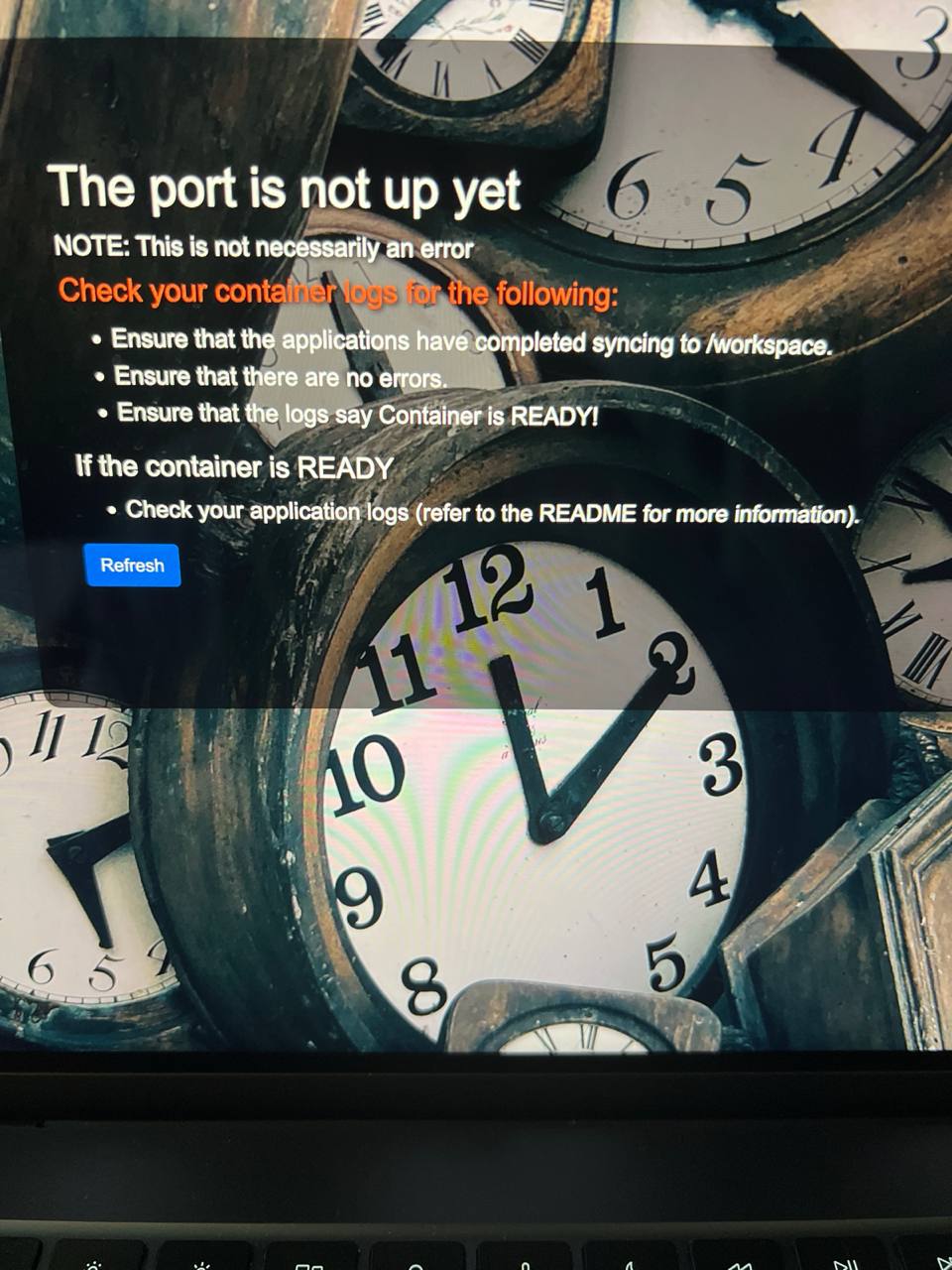
Help - Workflow for realstic product - WAN 2.2 14B
Docker Hub rate limits
Network Storage constantly "Not Ready" - EU-RO-1