queues backlog and retry/lag times available now in graphql!! 👀 thanks!
queues backlog and retry/lag times available now in graphql!! 
thanks!
thanks!



 J
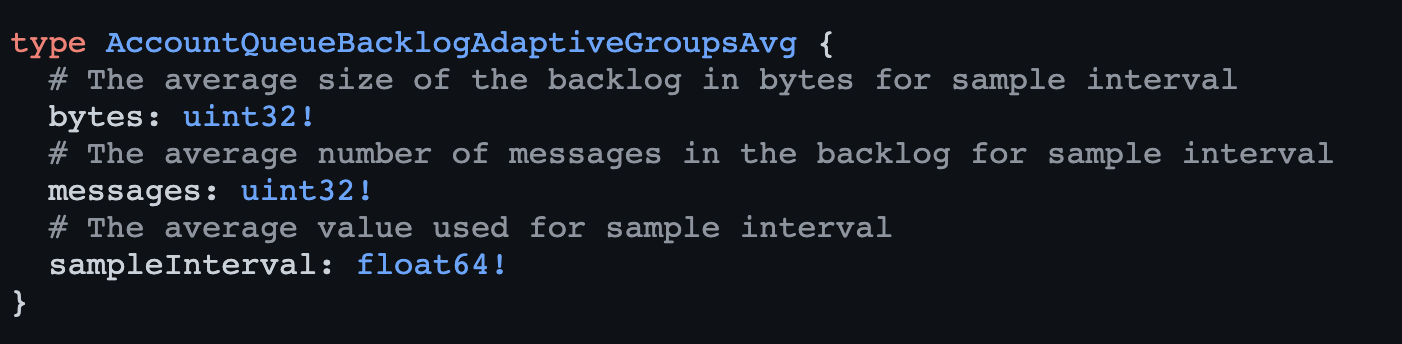
J# Beta. Queue backlog data with adaptive sampling. Queues that are not being written to, or read from, will not return data, even if they have a backlog. E
E EJJ
EJJqueuefetch MM
MMenv.YOUR_BINDING_NAME.send() (and passing in envObject.keys(env) and paste the output? DM me if you prefer.MMMMM MM
MM E
Ebatch object to know which Queue you're consuming from in that particular execution.EWorkers > Overview > (your worker) > Triggers > Queues (bottom of page)) or by removing it from the wrangler.toml.ack() on every message (or the entire batch) when handling it? .retry() would exist for the cases where you want to explicitly, negatively acknowledge. this post; if no, reply with why! Keep in mind I am familiar with other messaging systems; there’s not an agreed-upon approach here!MMM
this post; if no, reply with why! Keep in mind I am familiar with other messaging systems; there’s not an agreed-upon approach here!MMMYOUR_QUEUE.send(). In the longer term we’re exploring other on-ramps to support this nativelyMM UUMUM
UUMUM.ack() to make partial progress through a batch so that message is not retried if the handler errorsretry() or retryAll() on a message or a batch to force a retry, even if the handler returns successfully DU
DU# Beta. Queue backlog data with adaptive sampling. Queues that are not being written to, or read from, will not return data, even if they have a backlog.env.YOUR_BINDING_NAME.send()Object.keys(env)batchWorkers > Overview > (your worker) > Triggers > Queues (bottom of page).ack().ack().retry()YOUR_QUEUE.send()retry()retryAll()export default {
...
async queue(batch: MessageBatch, env: Env, ctx: ExecutionContext) {
if (batch.queue === 'my-first-queue') {
doSomething()
} else if (batch.queue === 'my-other-queue' {
doSomethingElse()
}
...
},
};







