@Furkan Gözükara SECourses The command you gave does not seem to wrk
@Furkan Gözükara SECourses The command you gave does not seem to wrk
 F
F G
G G
G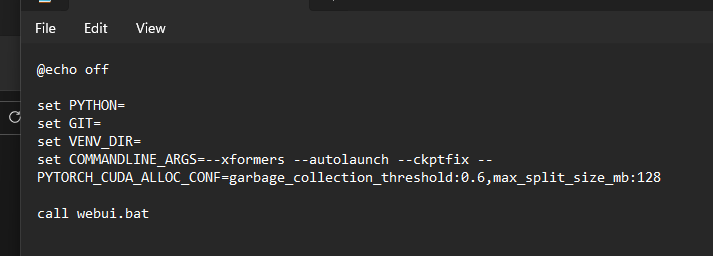 GFF
GFF SF
SF KFFGFGGFGGGFFGGGF
KFFGFGGFGGGFFGGGF GGGGFFGGGK
GGGGFFGGGKmemory_efficient_attention_forwardcutlassFflshattFtritonflashattFsmallkF ZZ
ZZ GGG
GGG FFFFFFK
FFFFFFK F
F

