Hello everyone. I am Dr. Furkan Gözükara. PhD Computer Engineer. SECourses is a dedicated YouTube channel for the following topics : Tech, AI, News, Science, Robotics, Singularity, ComfyUI, SwarmUI, ML, Artificial Intelligence, Humanoid Robots, Wan 2.2, FLUX, Krea, Qwen Image, VLMs, Stable Diffusion
No I typed wrong , I mean, how can I adjust the details of the enhanced image to make it sharper? Without losing details Refers to my face shape used for training
I liked the hires fix better. For the face trained loras, it definitely worked better with the hires fix than with adetailer. I tried the other adetailer models, but most of the time they made the original result worse. True, I just turned it on by default, not trying to get a better result, but I would think it would work fine by default. But I'll check later to see if I really need a pilot test.
@Dr. Furkan Gözükara hi, I trying to do a training in dreamboth using runpod when I try to put the path of the source directory like "/workspace/768x1024" where my images to be trained is supposed to be I and the click on preprocess I have an error --- Error completing request
files = listfiles(src) File "/workspace/stable-diffusion-webui/modules/textual_inversion/preprocess.py", line 30, in listfiles return os.listdir(dirname) FileNotFoundError: [Errno 2] No such file or directory: '/workspace/768x1024'
Hi @Dr. Furkan Gözükara I follow your runpod tutorial for creating portrait photo images training model of a data set of a woman and the output start to create naked pictures half body there is any way to avoid that?
Hi, could someone plz point me to the right resources for incorporating two safetensors into sd 1.5 or sdxl? Is it possible to use one that's completely different from the other (one that tells the model what my dog looks like & the other that is a pixel art theme)
Very useful & interesting thank you very much. How is your flexibility test going? CivitAI also use batch 2 to train their Lora so I guess batch 2 could be a sweet spot.
should I add negative prompts before start the training? also I’m getting double persons and half bodies instead of portrait shots. I’m training 768x1024 maybe is better use 1024x1024?
Hi guys how do you save Prompt as a text file with ComfyUI please? I found this node of pythongosssss but I'm not a coder so I don't know how to change the "$output/*/.txt" to save the txt file into /workspace/ComfyUI/output/ComfyUI_00471.txt (next to the ComfyUI_00471.png so I can download both of them. I'm using Runpod) https://github.com/pythongosssss/ComfyUI-Custom-Scripts
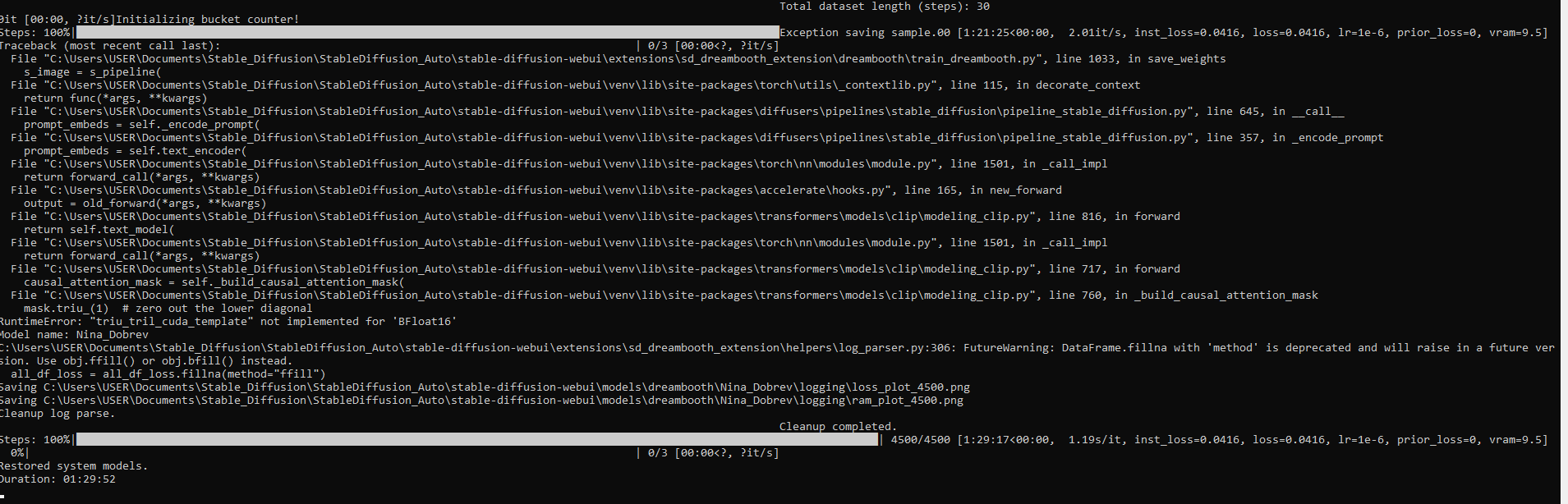
Initializing bucket counter! Steps: 1%| | 10/1100 [01:38<1:59:03, 6.55s/it, inst_loss=0.0501, loss=0.0501, lr=0.0001, prior_loss=0, vram=6.8] guys is this a normal ? I started use brand new stable diffusion v1.6. If you got advice how can i increase this speed please share me. Sorry for my bed england
@Stefanoid9343 from my experience the double the double people thing really depends on the model you are using to train with because if it was trained in 512 or you are much more likely to get double people if you go higher than 768 and it's still not always perfect if it was a 768 training. a lot of the newer really good models i have downloaded have specified that you need to specify outfits or you are more likely to get nsfw results. your best bet if you don't want any chance of nude images is to find a model that doesn't produce nsfw images i think. but i am no expert.
@Dr. Furkan Gözükara I am using 150 training steps per image and have 30 images in my dataset. I am not using any classification images. Do you have any advice why does my train model look different from my dataset?
 F
F
 J
J M
M E
E S
S A
A
 M
M
 S
S



 D
D
 E
E K
K V
V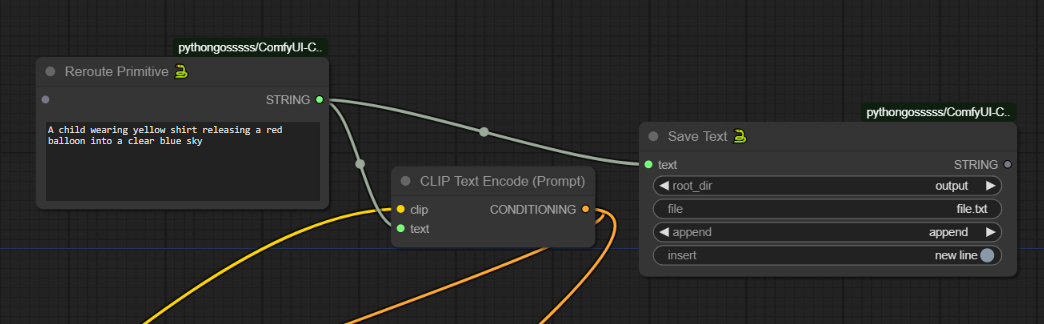
 M
M E
E F
F L
L