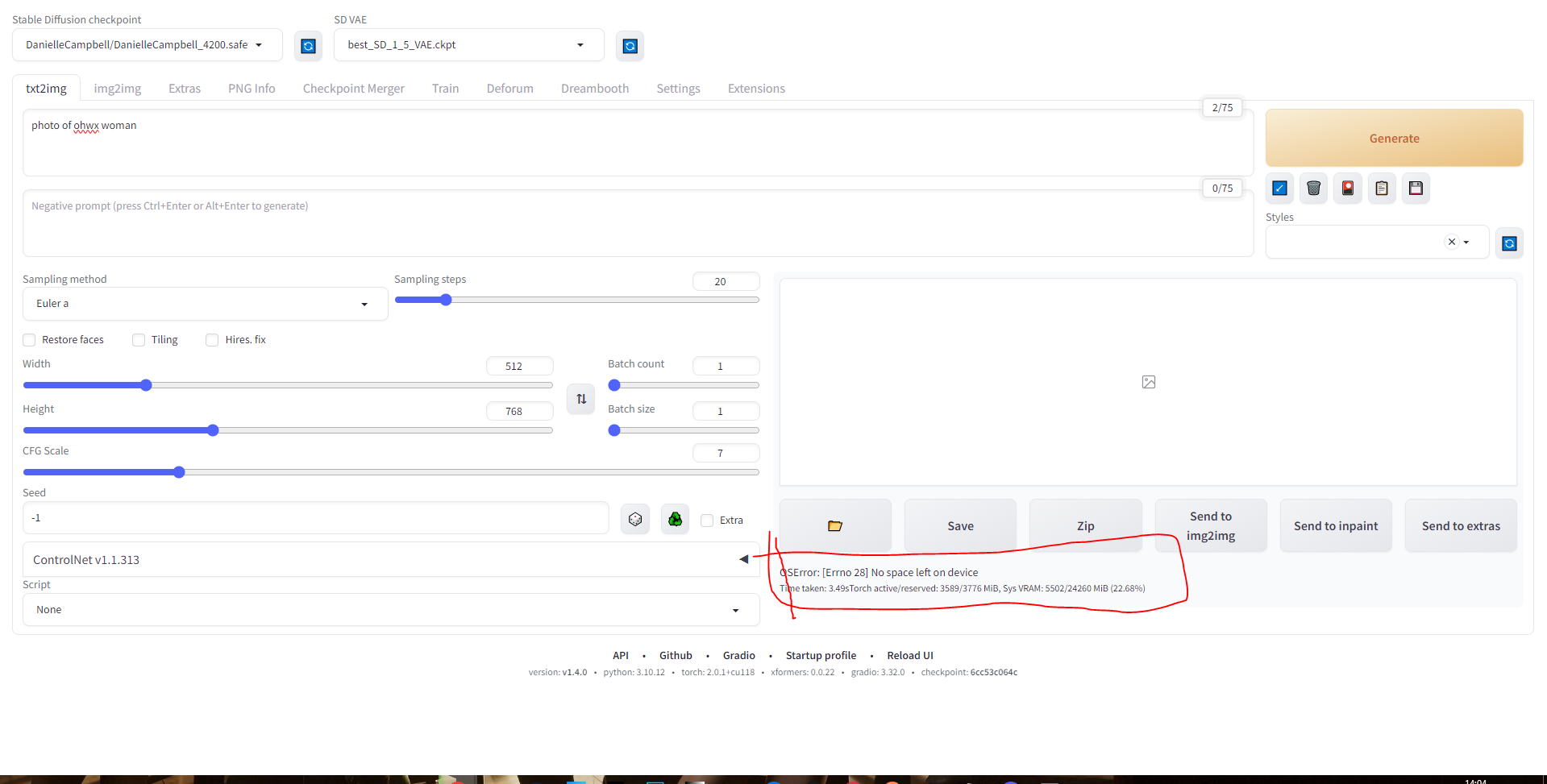
I have trained my model and try to test it but getting this error. Does anyone know how to solve it
I have trained my model and try to test it but getting this error. Does anyone know how to solve it ?
 L
L ML
ML N
N I
I FFFFF
FFFFF FFFFFFFMM
FFFFFFFMM DF
DF FLFLFF
FLFLFF ED
ED FFFEFFFEDEF i can also make private session and explain you if you are interested in professionallyEFDFD
FFFEFFFEDEF i can also make private session and explain you if you are interested in professionallyEFDFD ELL
ELL F
F




