 Z
Z1.0


 M
MIf not, you can make them with Furkan's yolo scripts, you can find pictures on Pixabay.
MJust change it from person to dog
Zi want sdxl turbo inpainting
 MM
MMYes, that's what I thought
Zi'm gonna tell you right now why i love sdxl turbo instant
ZIt's not the best graphically, but you can cycle through prompts and styles and see exactly what the prompts do, then you can use fooocus or auto1111 or comfyui with high step scheduler and get exactly what you want
 R
RWhat’s your workflow?
M![Digital [Starburst]](https://cdn.discordapp.com/avatars/220961909447458817/8ecbbb3132fc6e44312f3d6d2ae3df69.webp?size=40) D
DSo, I don't think CUDA is working with Automatic1111, but it does work with ComfyUI which I took the liberty of installing on my own and followed a img2img tutorial to try it out. However, I am not sure how to get ControlNet working with ComfyUI, but I can see you can do it.
DI haven't gotten that far in the class. EDIT: I spent the day experimenting and found a Reddit post that had a dupilicate on CivitAI which I was able to follow. I haven't completed it, but I do have Vid2Vid and Txt2Vid installed and proper workflows downloaded. I will work some more on it tomorrow. For now, I'm calling it a night.

 H
Hhey did you fix it?
 F
Fthis is a plan
 F
Fit auto generate that
 F
Fi dont know
Fi really dont bother with it
FI just had a client meeting. Explained how to train Stable Diffusion XL (SDXL) DreamBooth training with best hyper parameters.
Used my medium quality training…
Used my medium quality training…
 D
DVery much a novice -- I was watching your comprehensive tutorial on setting up ComfyUI on RunPod. There is now a template for: RunPod SD Comfy UI. To follow your tutorials, do I need to do anything other than save the checkpoints to the proper folder in the workspace?
Fif template working probably you dont need
Fbut templates usually dont get updated
Ffrequently
FStarted 3 massive Stable Diffusion XL (SDXL) DreamBooth trainings for a client.
I am trying to train a certain style drawings. Each training testing different…
I am trying to train a certain style drawings. Each training testing different…
 F
Fdoing a massive training
 A
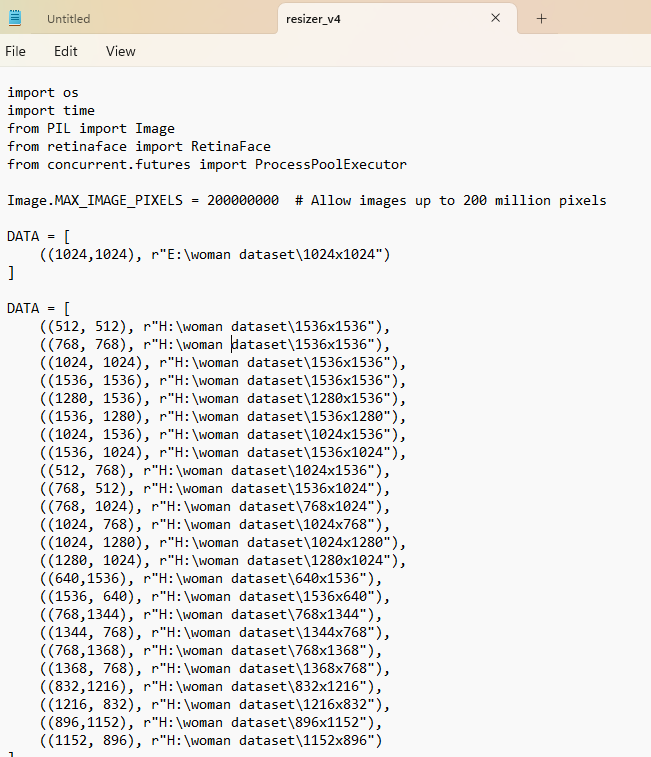
Ado we have to edit each of these or can I delete all but one and just have it as my 1024x1024?
 R
RDo they still? It mentions cropping 512 still down to
AWeird, it turns my images sideways and crops into the face for some reaosn, no idea why
AAny idea when why when I loaded the 24gb text json it doesn't autofill the additional params? usually this is longer I think
 D
Dcan you run animatediff on 3080 10 gb ?
Mwould you say its better to do dreambooth training via the extension on automatic1111 or do it on khoya?
Fyou can delete that you dont need
Fi dont know didnt test recently
Fi see auto filled
 F
Fi am yet to explore animate diff
Dit produced a bujnch of pics which were related but not worthy to be made into gif , if thats the output.. have to explore. The prompr length also seems to matter..
 W
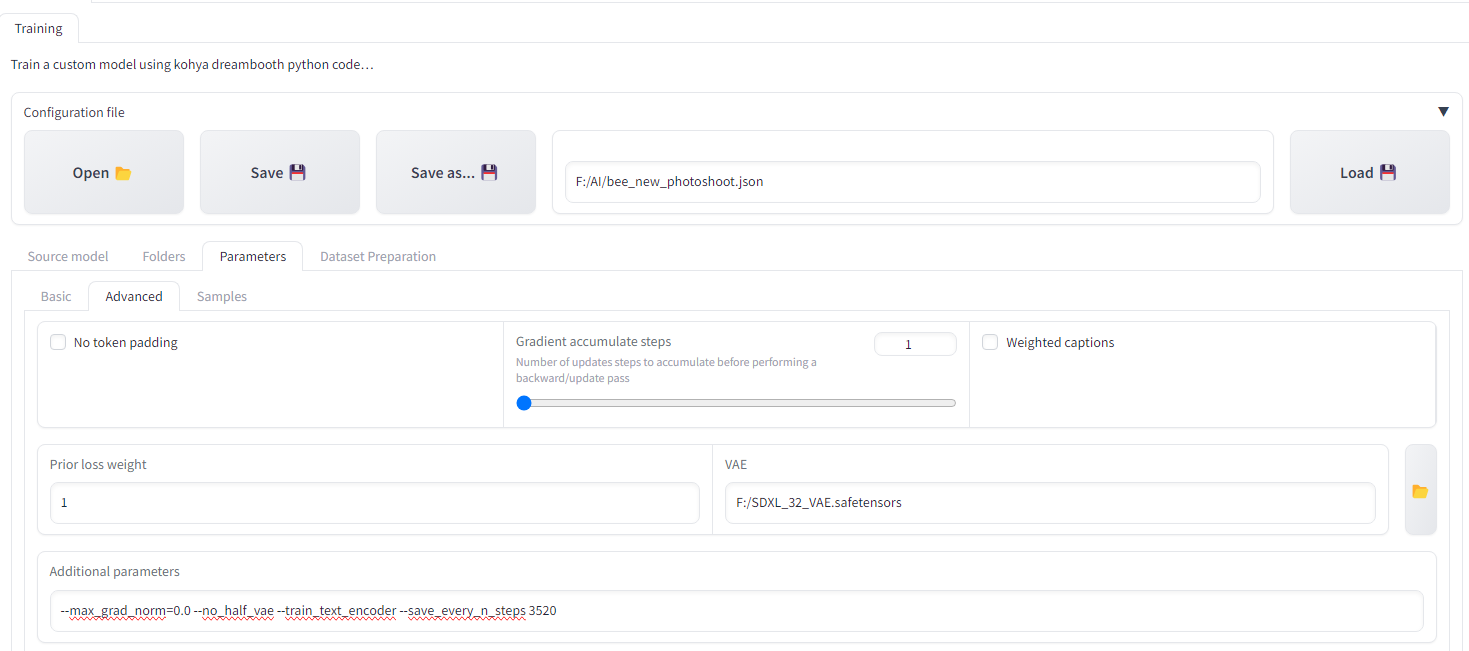
Wbest hyper parametrs , its about these you posted on patreon 24GB_TextEncoder kohya ? , and how many images did you select for training, and repeats while using class images
Wif im gonna use 3 4 gpus , i also need consider about for choosing right number of repeats , as u said , if i have two gpus need to devide it on number of gpus
 A
AVery inspiring, have you considered checkpoint training with EveryDream2 instead of LoRa...and watch these same parameters? Just wondering whether this could lead to even better results. Although I agree with you, the quick turnaround of LoRa training is great from a feedback cycle point of view.
 F
Fi used 14 images
Fmultiple gpu means increased batch size
Fso 2 gpu will make it batch size 2. so you should halve the number of steps
Fyes that training done with 24gb config on patreon
F24GB_TextEncoder.json
WThanks , Repeats should be around 160 for sdxl , I remember for 1.5 it’s easy to overtrain and 25-40 was okay
Dthis time , the image creation needed very little effort to bring the face output. Using correct , HQ face images , makes lora training much easier.




 A
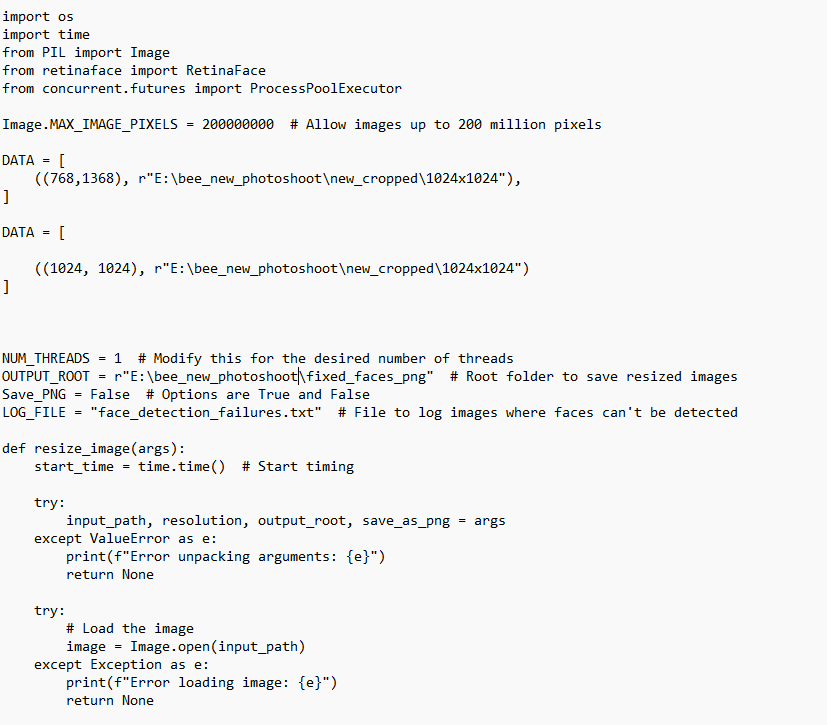
ADo we use extract faces or resizer?
Ais this correct? I just want to do 1024x1024
 M
MI find the big model training unnecessary. I'd only do it if I really wanted to make a new model, but that would require millions of photos, and I only do DreamBooth very rarely (for example for a pose that no model can do by default, like a full undereye). For everything else, I have Lora, which is fast, perfect for me, and the quality is absolutely comparable to a DB model, plus I can put it on top of any model, mix it with other Lora.