@Dr. Furkan Gözükara how would I get it to not use VAE in addition to Juggernaut for training? Jugge
@Dr. Furkan Gözükara how would I get it to not use VAE in addition to Juggernaut for training? Juggernaut already has vae baked in
 GG
GG FFFFFF
FFFFFF Master Stable Diffusion XL Training on Kaggle for Free! Welcome to this comprehensive tutorial where I'll be guiding you through the exciting world of setting up and training Stable Diffusion XL (SDXL) with Kohya on a free Kaggle account. This video is your one-stop resource for learning everything from initiating a Kaggle session with dual ...
Master Stable Diffusion XL Training on Kaggle for Free! Welcome to this comprehensive tutorial where I'll be guiding you through the exciting world of setting up and training Stable Diffusion XL (SDXL) with Kohya on a free Kaggle account. This video is your one-stop resource for learning everything from initiating a Kaggle session with dual ... GF
GF DGFFF
DGFFF MDDDDTT
MDDDDTT
 JMGGG
JMGGG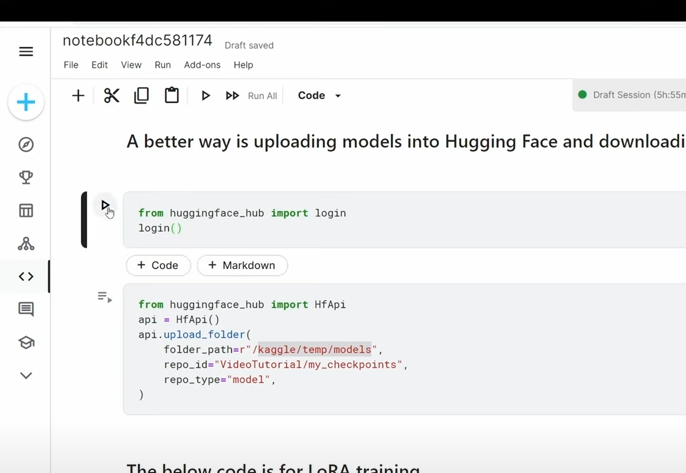 GDMDDD
GDMDDD F
F GGDDD
GGDDD FGFFM
FGFFM AMDFMF
AMDFMF



