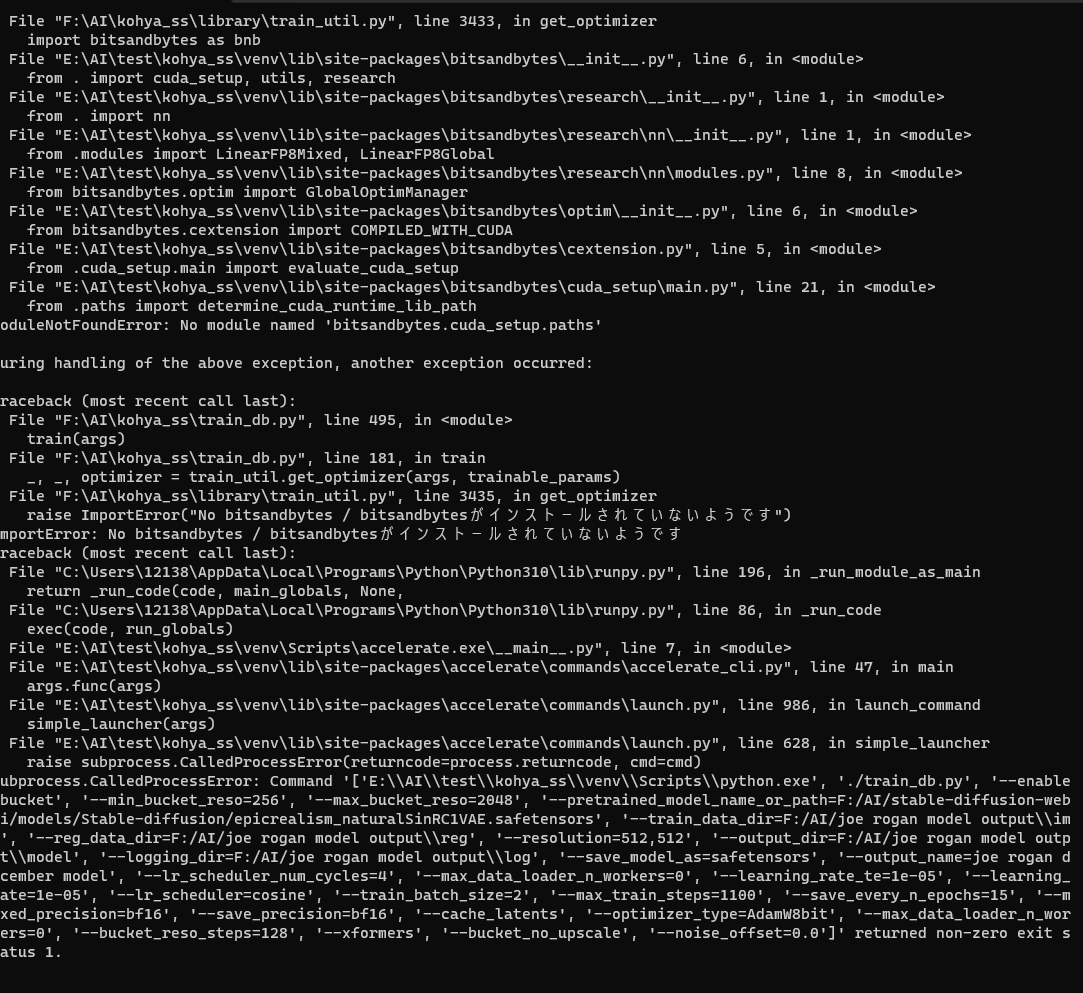
Any idea what this error is
Any idea what this error is
 T
T PP
PP D
D
 H
H DHH
DHH T
T FFFFFFFFFFFFD
FFFFFFFFFFFFD TFFFHFFFFHM
TFFFHFFFFHM Z
Z
 A
A MPPPPTT
MPPPPTTlow_cpu_mem_usage=Falseignore_mismatched_sizes=True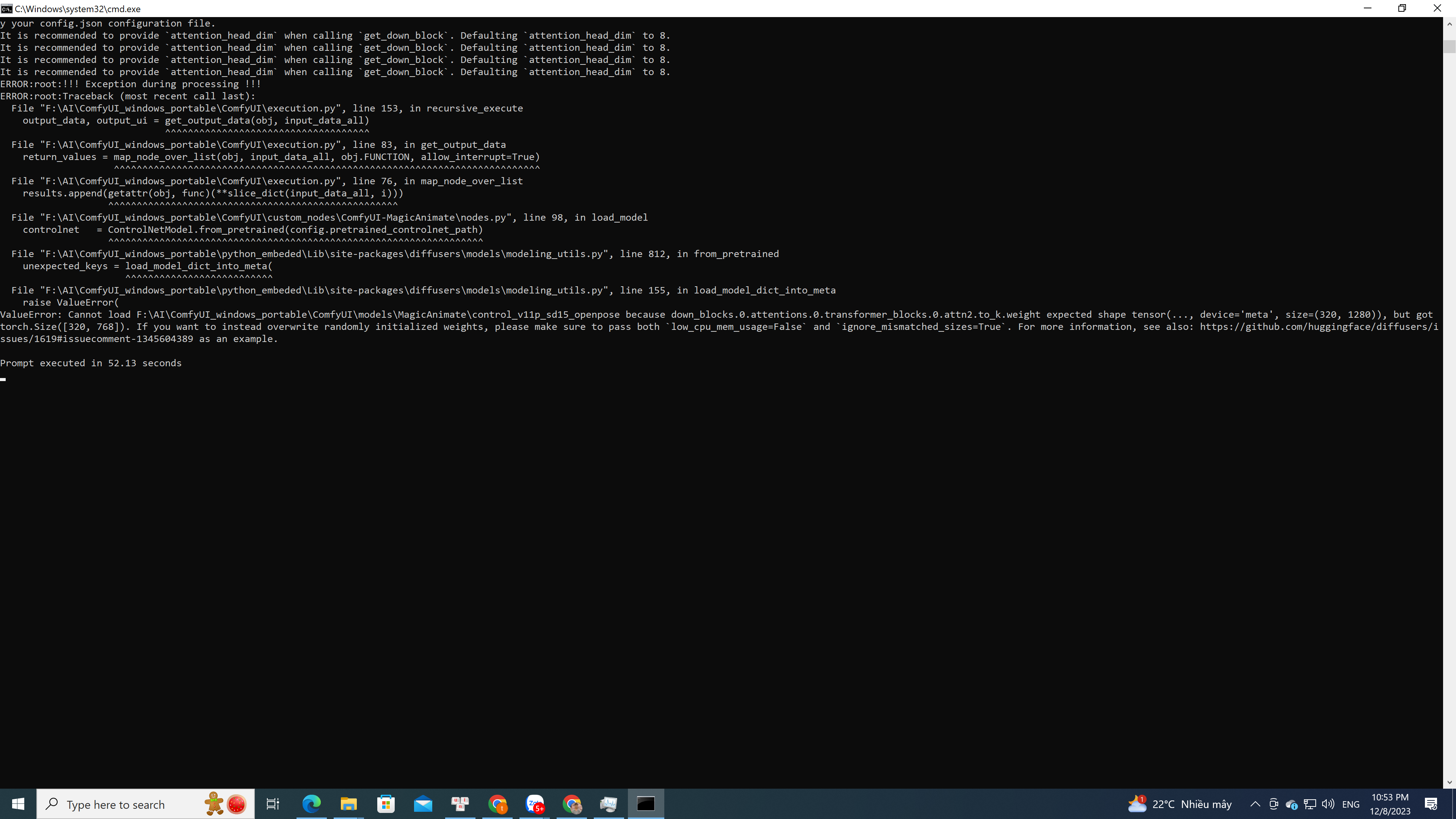
 PPT
PPT TPPT
TPPT the sameP
the sameP


