just a standard LoRA with my usual settings. It is v2. 1. version was trained on 14 images (includi
just a standard LoRA with my usual settings. It is v2.
All training images are 4k - 8k, and captioned in a very similar manner
.. and so on.
See the attached screenshot on repeats. (the caption is done via text files, so only the number is used from those folder names)
I trained 10 epochs of which 7 - 10 at 0.7 - 1.0 weight are actually usable.
- version was trained on 14 images (including solo, coupled and character sheets) all on white background
- version included 35 images with more poses (including solo, coupled and character sheets) all on white background
All training images are 4k - 8k, and captioned in a very similar manner
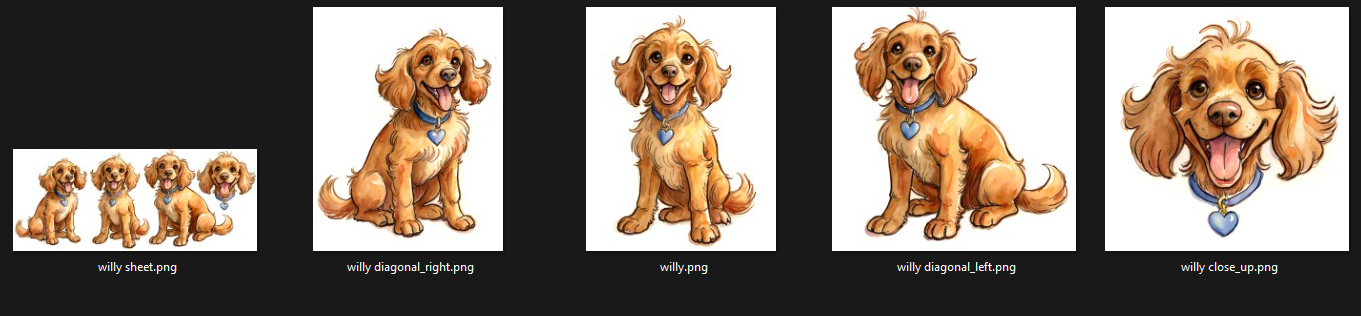
Mike the boyWilly the dogMike the boy with his dog WillyMike the boy is runningMike the boy with hands in pocket, upper bodyMike the boy with mouth open, screaming, close-up.. and so on.
See the attached screenshot on repeats. (the caption is done via text files, so only the number is used from those folder names)
I trained 10 epochs of which 7 - 10 at 0.7 - 1.0 weight are actually usable.