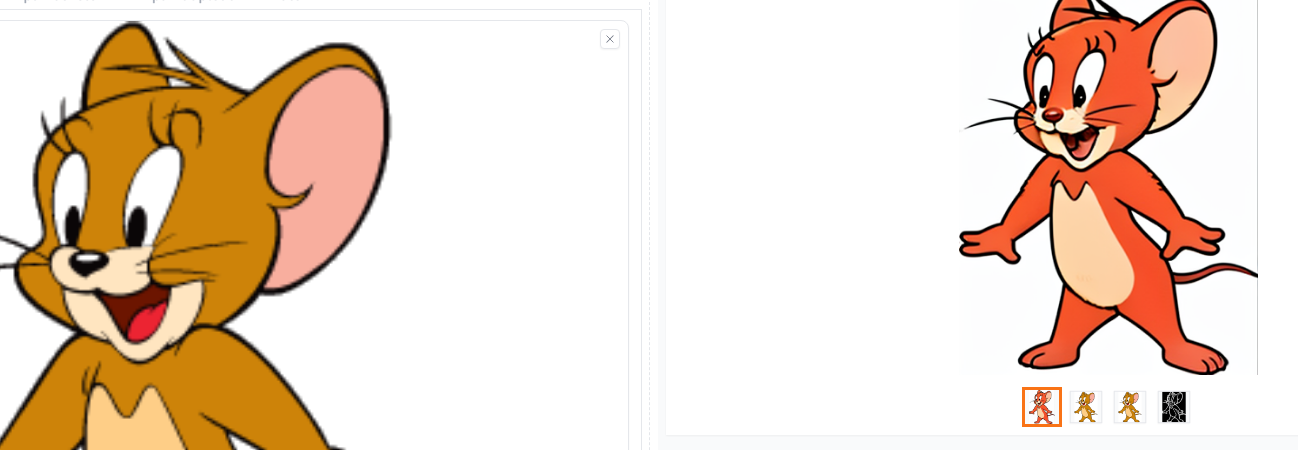
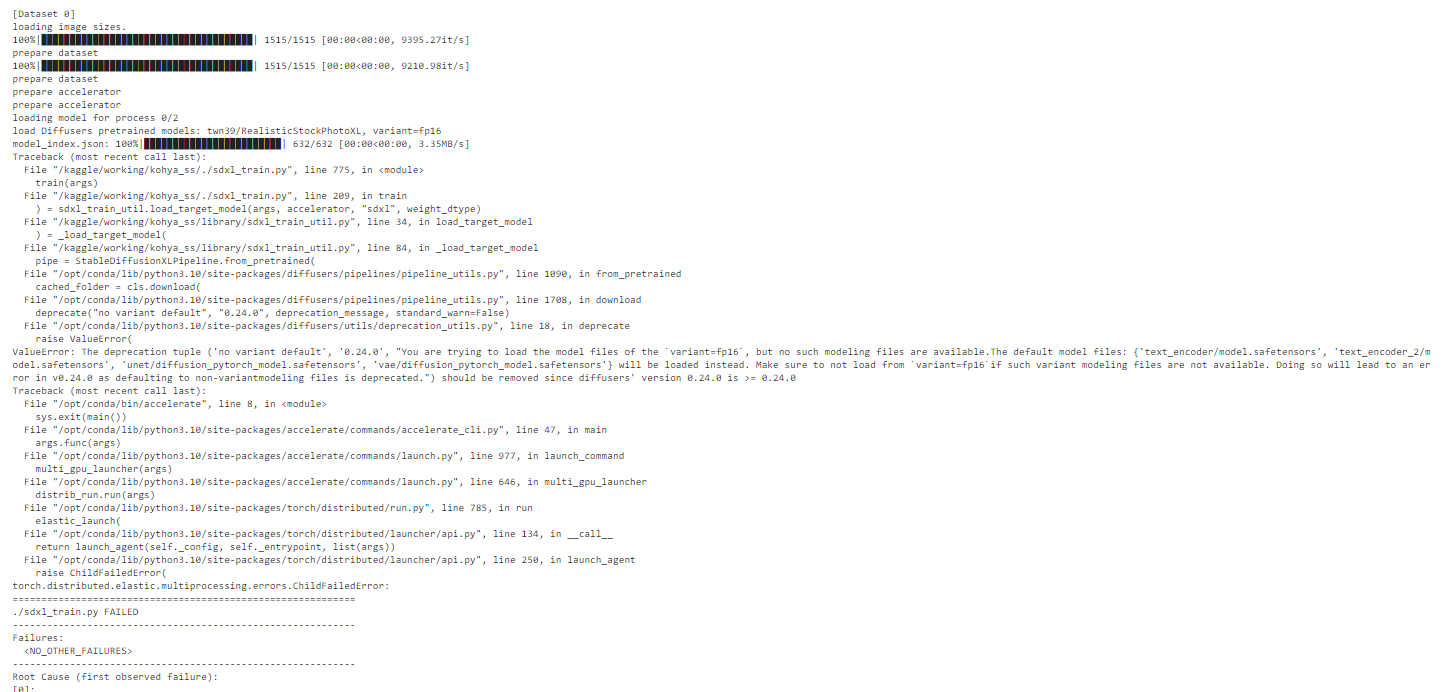
I stopped using the kohya GUI because I couldn't see how to enable multi-gpu, so I've just been usin
I stopped using the kohya GUI because I couldn't see how to enable multi-gpu, so I've just been using a command line argument. This is the argument:
I've tried this with a batch size of 1 and 2. 2 is actually slower than 1, and anything higher than 2 gives me an out of memory error.
I've gone ahead and tried doing a repeat of 40 on the original images, and now 7 (close enough to 40 / 6).
Changing that didn't change the total number of optimization steps, which was always 9600, or the time to complete training. I think it just wanted to do more epochs.
After changing the repeats to 7 and removing the flag for
I tried using the
I've tried this with a batch size of 1 and 2. 2 is actually slower than 1, and anything higher than 2 gives me an out of memory error.
I've gone ahead and tried doing a repeat of 40 on the original images, and now 7 (close enough to 40 / 6).
Changing that didn't change the total number of optimization steps, which was always 9600, or the time to complete training. I think it just wanted to do more epochs.
After changing the repeats to 7 and removing the flag for
--max_train_steps="9600"I tried using the
--ddp_gradient_as_bucket_view