Sorry I am still beginer , for what usage google colab
Sorry I am still beginer , for what usage google colab
 B
B FF
FF![Dazzastrous [4090]](https://cdn.discordapp.com/avatars/871389071686135838/c4a5f4d81d9eeb18d856295d692e2c07.webp?size=40) D
D FF
FF J
J Muhammad Ghulam Jillani(Jillani SoftTech), Senior Data Scientist and Machine Learning Engineer
Muhammad Ghulam Jillani(Jillani SoftTech), Senior Data Scientist and Machine Learning Engineer
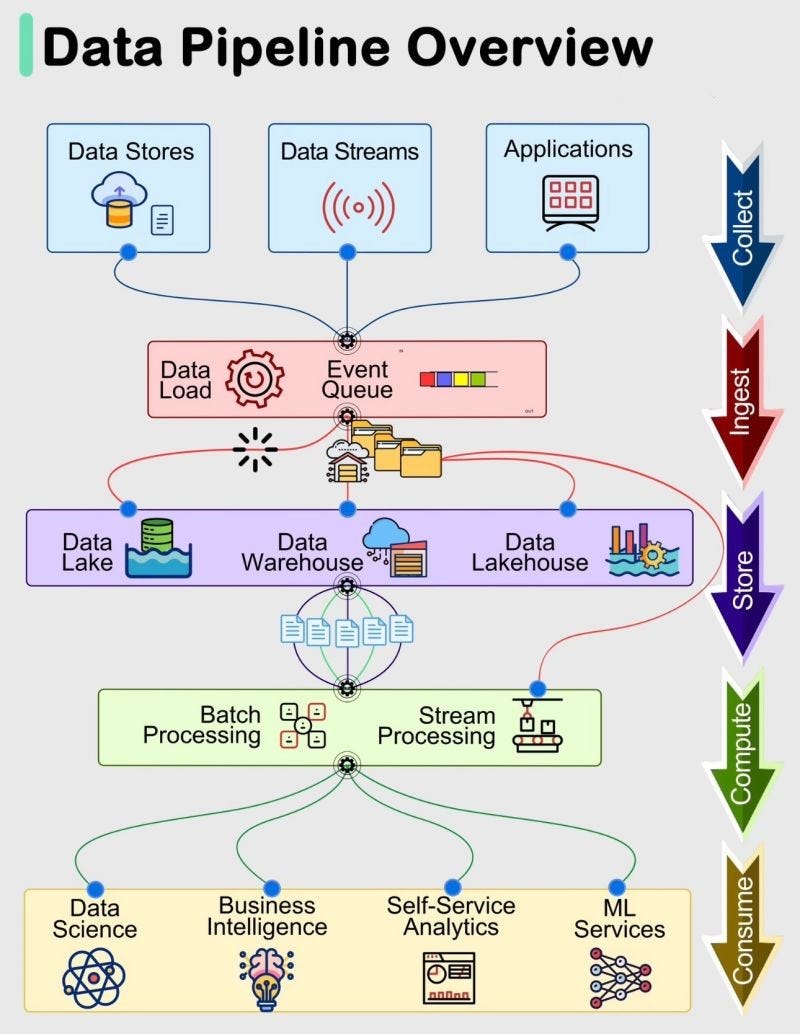
 TFF
TFF D
D RFF
RFF ZZFF
ZZFF ᴏFFFᴏ
ᴏFFFᴏ AFFAFD
AFFAFD
 A
A DF
DF DRFFFFRRF
DRFFFFRRF WADFAF
WADFAF D
D D
D
![Dazzastrous [4090]](https://cdn.discordapp.com/avatars/871389071686135838/c4a5f4d81d9eeb18d856295d692e2c07.webp?size=16)






