
Welcome to the official Cloudflare Developers server. Here you can ask for help and stay updated with the latest news
83,498Members
View on DiscordResources
Similar Threads
Was this page helpful?
 D
D K
K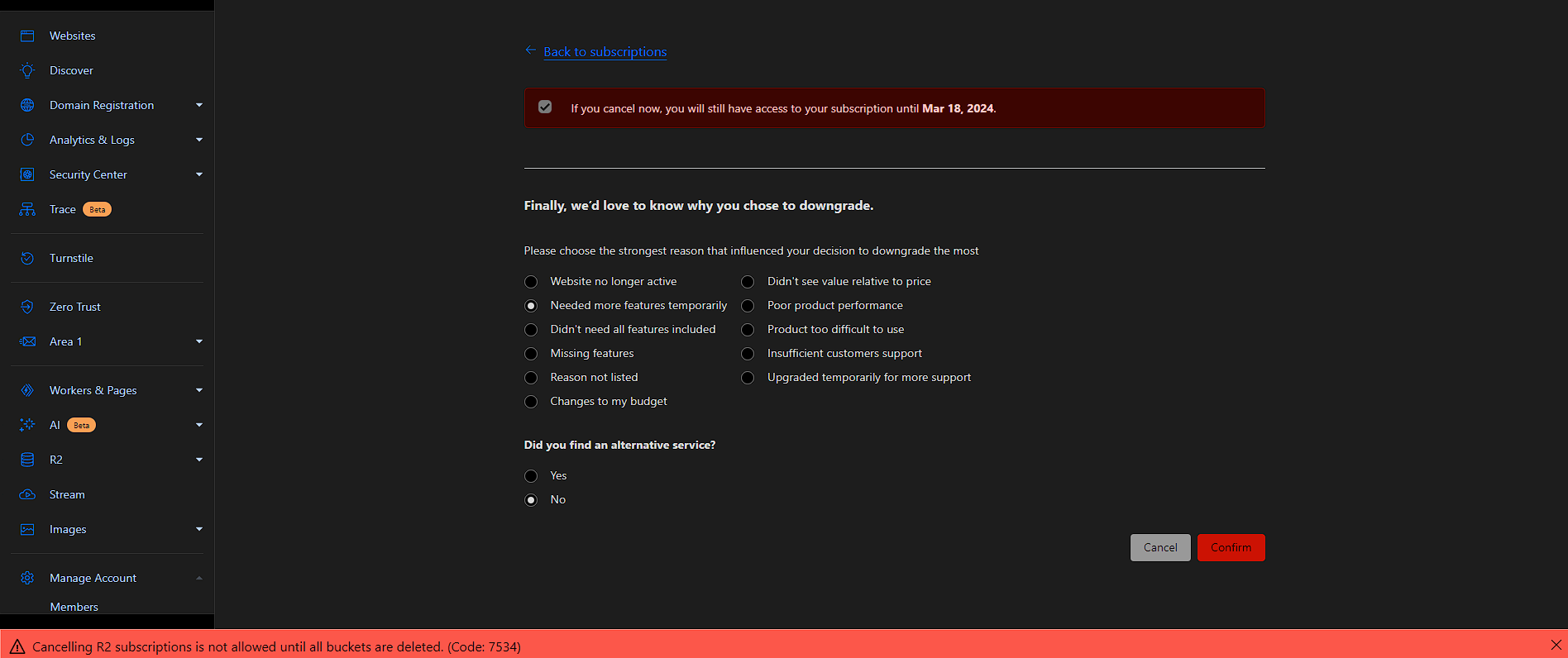 K
K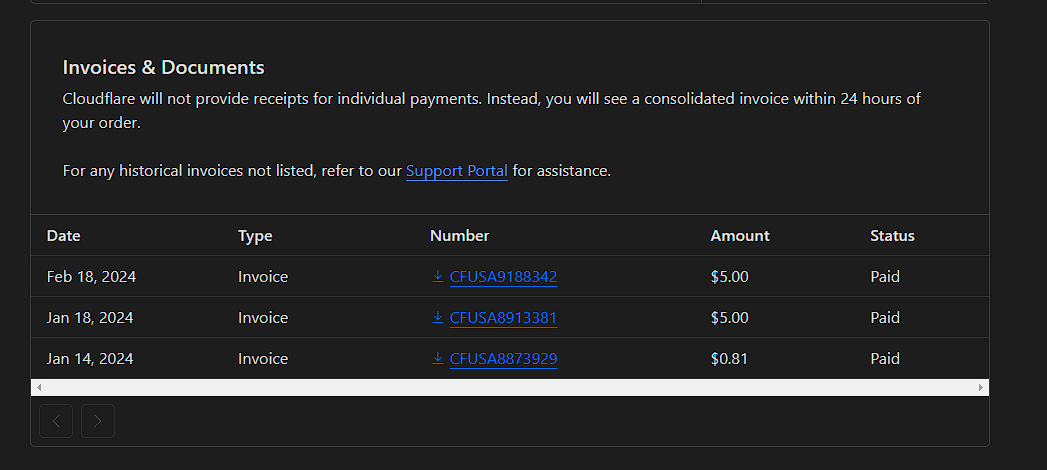
 NN
NN K
K PNNNNN
PNNNNN E
E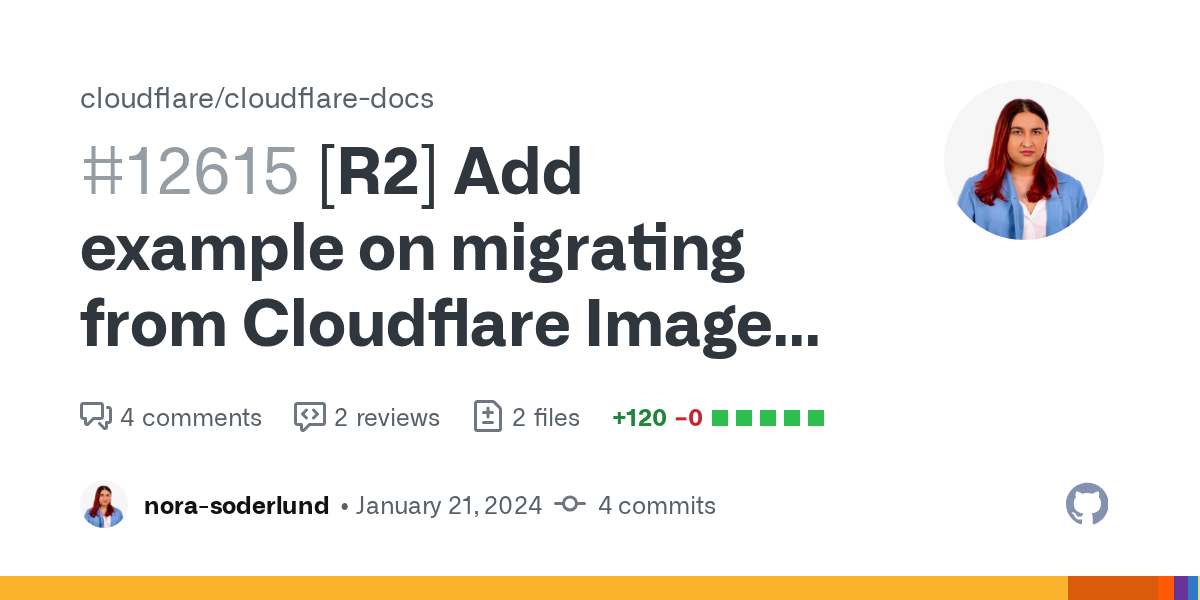 EEE
EEEresponse: {
status: 429,
statusText: 'Too Many Requests',
}EEEEEEError: Too many subrequests IIIE
IIIE SEEE
SEEE S
S
 Z
Z KK
KKresponse: {
status: 429,
statusText: 'Too Many Requests',
}


