@Dr. Furkan Gözükara Is it possible to add a checkbox or something to make it possible for CLIP Inte
@Dr. Furkan Gözükara Is it possible to add a checkbox or something to make it possible for CLIP Interrogator to batch process subfolders as well?!
 NN
NN NN
NN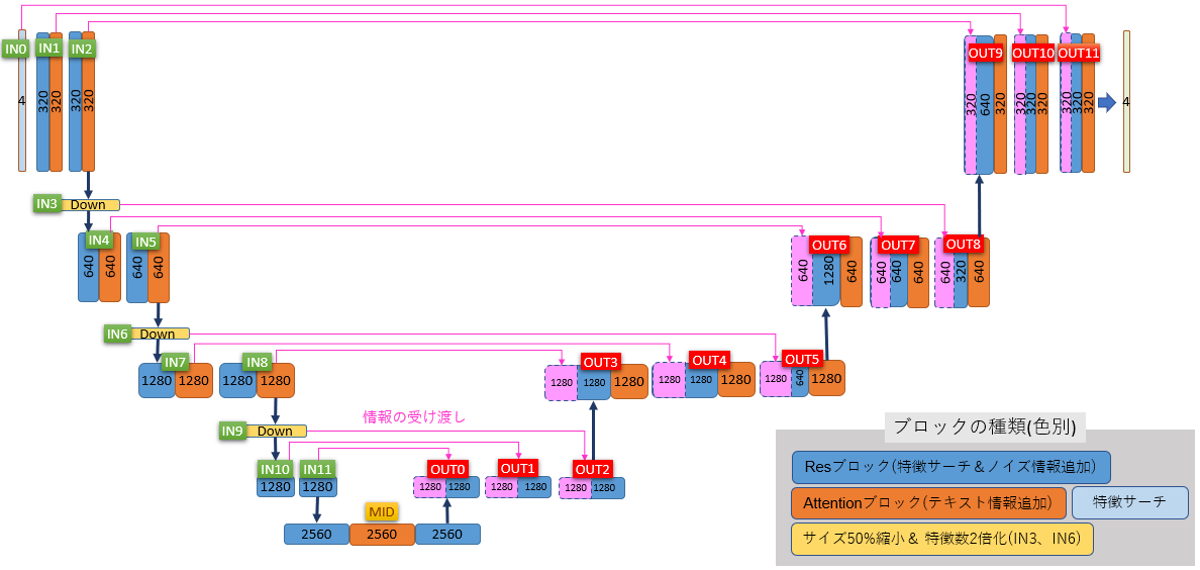 N
N K
K MMMN
MMMN KM
KM MM But I dont want these silicone boobs in my instance model
MM But I dont want these silicone boobs in my instance model  C
C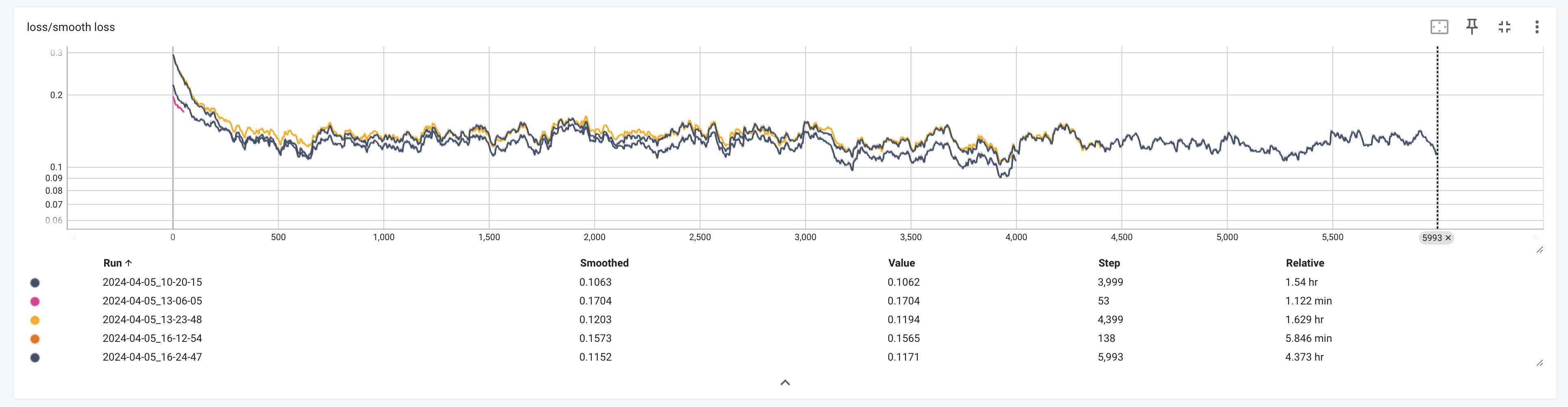 K
K L
L MMM
MMM M
M FFFF
FFFF AA
AA N
N FFFFFNNFNFFFFNFFNAFF
FFFFFNNFNFFFFNFFNAFF







