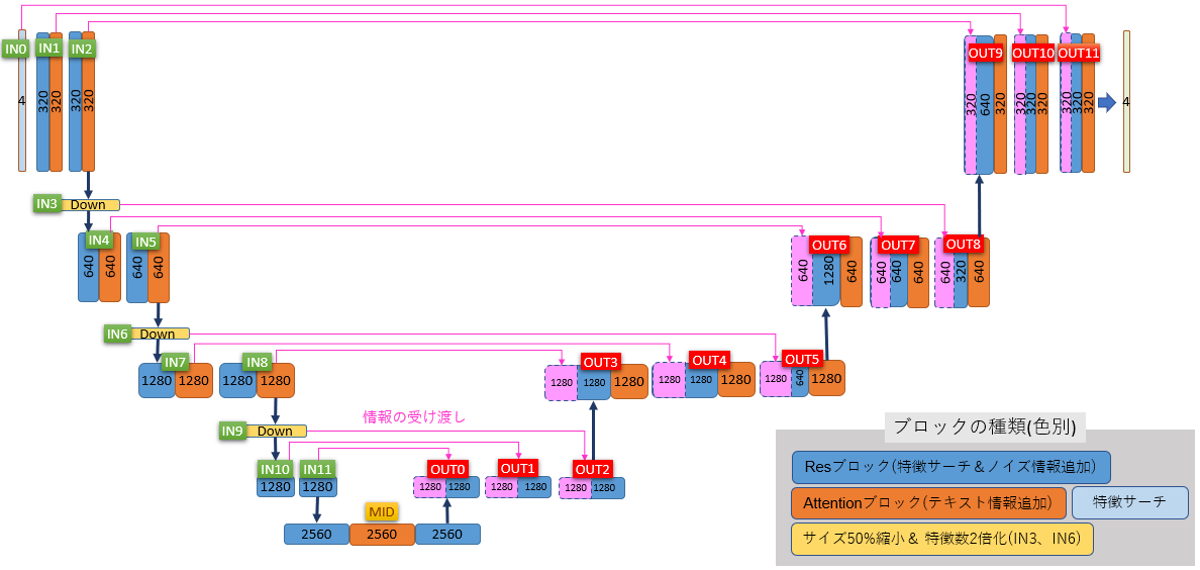
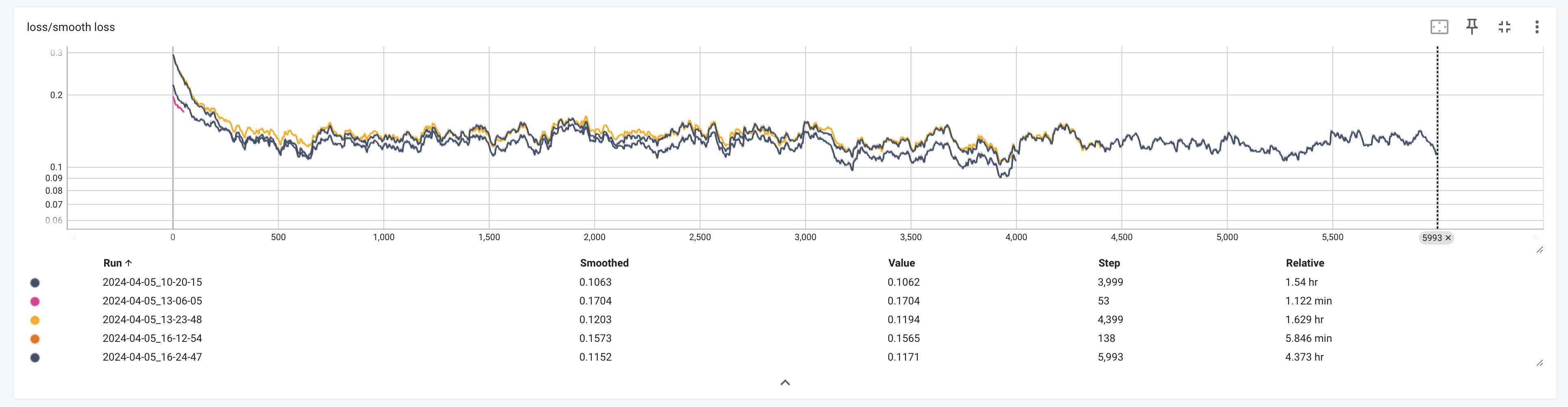
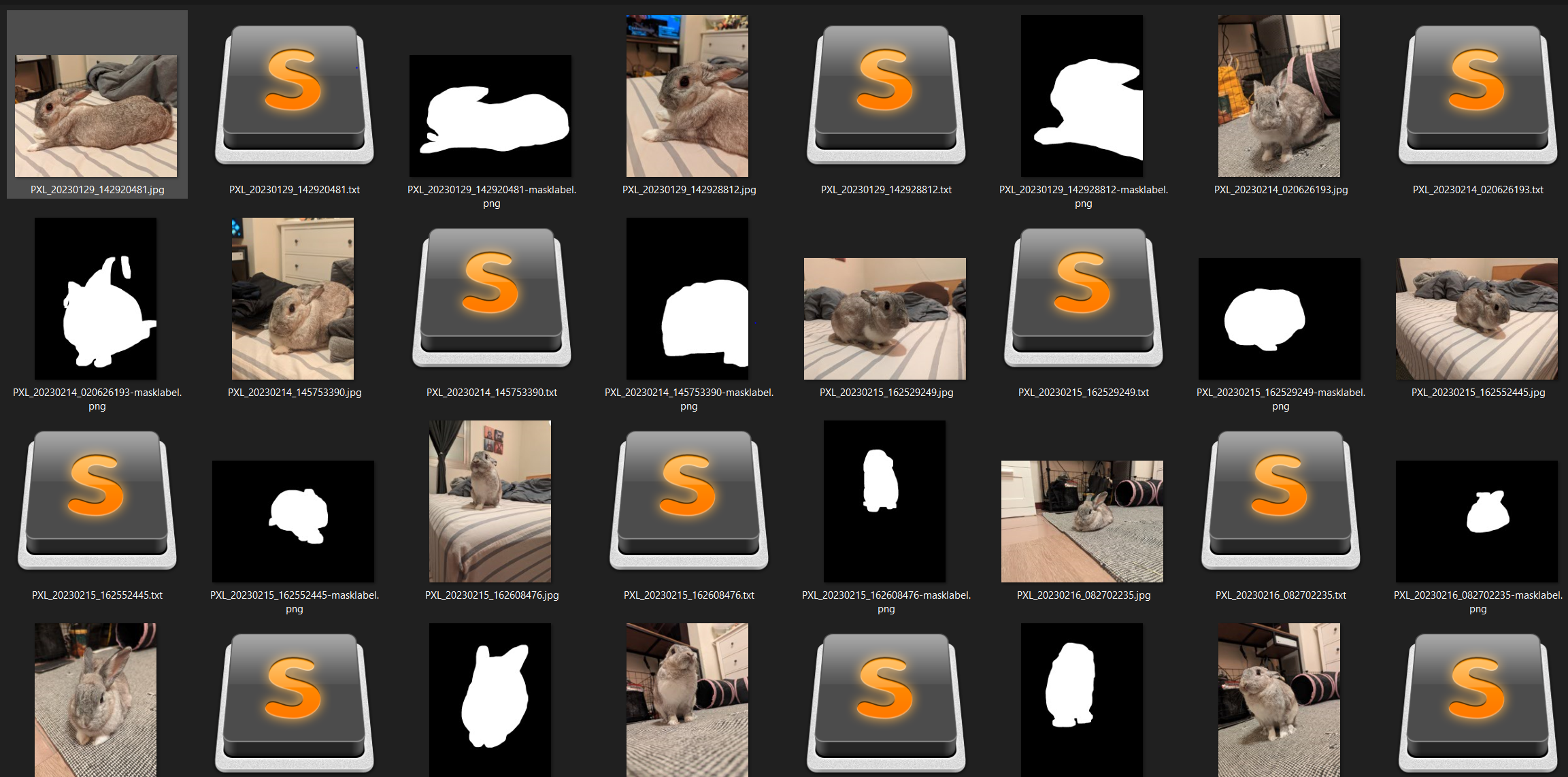
Not sure who has responded but I train LoRAs (presently using Kohya, will attempt to transition to O
Not sure who has responded but I train LoRAs (presently using Kohya, will attempt to transition to OneTrainer soon) that require a high amount of quality and accuracy due to celebrity reproduction. What I am finding is that approaching model sized datasets (~300 images) is the key to increased accuracy across the board of your concept. This is the easiest and most straight forward method, but not always available if you can't acquire a dataset with enough good quality representations of your concept(s). So alternatives:
1) Train multiple concepts - This from reports is a mixed bag. I've done it for a TV celebrity who plays an iconic character with OK success. If I did it again, I would increase the size of my dataset for each concept to ~250 or more images.
Further to this, you will also need to watch out when training lots of closeups to get it to learn a concept as it will lose reference with your MAIN subject (depending on what your concept). So say your concept is a male celebrity but you want the abs more accurate, doing all closeups of the abs may cause it to lose reference to the main subject you want. After all it is giving you what its learned (just abs closeups) from the trigger word you associated it with.
2) Train with color association or some other novel machine learning method - See Civitai article here: (sorry it appears he's removed the article and model). There is a reddit post still here about it: https://www.reddit.com/r/StableDiffusion/comments/1aolvxz/instructive_training_for_complex_concepts/?share_id=TyIZDSSNoYSqsqZVR0SzW
3) Train them as separate LoRAs, this would operate like 1) but remove the pitfalls people claim happens with multi-concept training in a single LoRA.
4) Learn how to train a model for ADetailer specific for your subject (tbh, I have no idea where to start with this one, but it may be what you and I both need to get body part accuracy)
1) Train multiple concepts - This from reports is a mixed bag. I've done it for a TV celebrity who plays an iconic character with OK success. If I did it again, I would increase the size of my dataset for each concept to ~250 or more images.
Further to this, you will also need to watch out when training lots of closeups to get it to learn a concept as it will lose reference with your MAIN subject (depending on what your concept). So say your concept is a male celebrity but you want the abs more accurate, doing all closeups of the abs may cause it to lose reference to the main subject you want. After all it is giving you what its learned (just abs closeups) from the trigger word you associated it with.
2) Train with color association or some other novel machine learning method - See Civitai article here: (sorry it appears he's removed the article and model). There is a reddit post still here about it: https://www.reddit.com/r/StableDiffusion/comments/1aolvxz/instructive_training_for_complex_concepts/?share_id=TyIZDSSNoYSqsqZVR0SzW
3) Train them as separate LoRAs, this would operate like 1) but remove the pitfalls people claim happens with multi-concept training in a single LoRA.
4) Learn how to train a model for ADetailer specific for your subject (tbh, I have no idea where to start with this one, but it may be what you and I both need to get body part accuracy)
Reddit
Explore this post and more from the StableDiffusion community