is binding 1000s of databases to a single worker a good idea? Will it slow down the execution of the
is binding 1000s of databases to a single worker a good idea? Will it slow down the execution of the worker?

 K
K H
H S
S
 S
S RS
RSINSERT INTO tokens VALUES('XXX',2024-01-27 08:56:38,2024-01-27 08:56:38,'XXX','XXX','ACCESS',NULL,NULL);R S
Swrangler d1 info + wrangler d1 insights?info is reporting 0 read queries in the past 24h (not the case unless it's somehow using some local version? The ID is the same as in my CF dash)insights is returning an empty array regardless of configurationS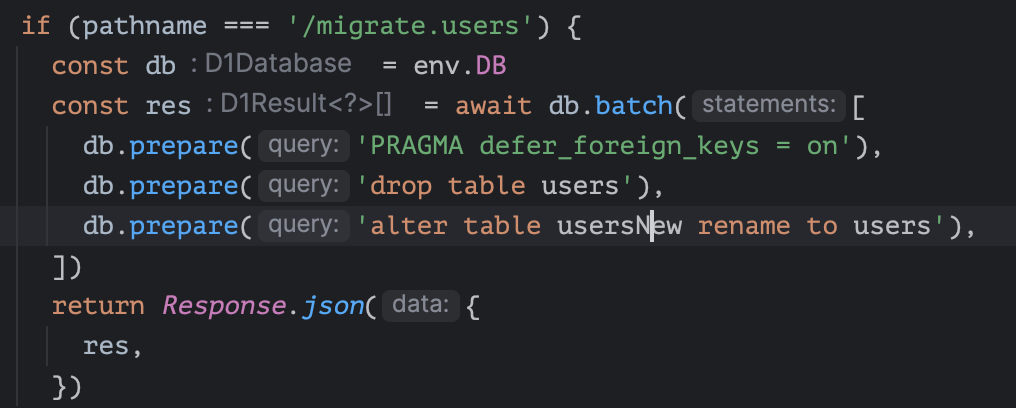
 D
D
INSERT INTO company_profile
(symbol, companyName, website, fullTimeEmployees, industry, overallRisk, description)
VALUES (?, ?, ?, ?, ?, ?, ?);
;Preparing to insert/update data for symbol: ${entry.symbol});Data successfully inserted for symbol: ${entry.symbol}, result);Insert failed for symbol: ${entry.symbol}, result);Failed to insert data for symbol: ${entry.symbol}, error);R U
U NNHNHNHHHNN
NNHNHNHHHNN K
Kdb.prepare('SELECT * FROM table WHERE status IN (?)').bind(['active','expired']).all(), would that work? M
Mselect count(1) from customer where country_id = 'uk' what is the cost for such a query?Rconst stmt = db.prepare('select count(1) from customer where country_id = "uk"').all();
console.log(stmt.meta.rows_read)MKmeta object will be in the HTTP response.Mcustomer table contains 900 records both queriesselect * from customer and select count(1) from customer "rows_read": 900,Mcount queries are quite expensive in D1D III
III UUMU
UUMU1. Rows read measure how many rows a query reads (scans), regardless of the size of each row. For example, if you have a table with 5000 rows and run a SELECT * FROM table as a full table scan, this would count as 5,000 rows read. A query that filters on an unindexed column may return fewer rows to your Worker, but is still required to read (scan) more rows to determine which subset to return.
Moffset, limit (so no cursors).totalCount10 this will result in 10 rows being queried.MMMIIIMMINSERT INTO tokens VALUES('XXX',2024-01-27 08:56:38,2024-01-27 08:56:38,'XXX','XXX','ACCESS',NULL,NULL);wrangler d1 infowrangler d1 insightsinfoinsights
INSERT INTO company_profile
(symbol, companyName, website, fullTimeEmployees, industry, overallRisk, description)
VALUES (?, ?, ?, ?, ?, ?, ?);
Preparing to insert/update data for symbol: ${entry.symbol}Data successfully inserted for symbol: ${entry.symbol}Insert failed for symbol: ${entry.symbol}Failed to insert data for symbol: ${entry.symbol}db.prepare('SELECT * FROM table WHERE status IN (?)').bind(['active','expired']).all()Every query returns a meta object that contains a total count of the rows read (rows_read) and rows written (rows_written) by that query. For example, a query that performs a full table scan (for instance, SELECT * FROM users) from a table with 5000 rows would return a rows_read value of 5000:
"meta": {
"duration": 0.20472300052642825,
"size_after": 45137920,
"rows_read": 5000,
"rows_written": 0
}
These are also included in the D1 Cloudflare dashboard and the analytics API, allowing you to attribute read and write volumes to specific databases, time periods, or both.select count(1) from customer where country_id = 'uk'const stmt = db.prepare('select count(1) from customer where country_id = "uk"').all();
console.log(stmt.meta.rows_read)metacustomerselect * from customerselect count(1) from customer"rows_read": 900,countoffsetlimittotalCount10






