
Welcome to the official Cloudflare Developers server. Here you can ask for help and stay updated with the latest news
83,498Members
View on DiscordResources
Similar Threads
Was this page helpful?
 Z
Z Z
Z
 O
O S
S C
C K
K J
J{
"name": "my-database"
} J
J
 J
JDELETE statement from a sql file, the metric returned in the terminal (the same number is in the web dashboard) for rows read was astronomically bigger than it should be:prods db has close to 12K rows (yes 12_000, not 12M).tid is indexed. The statement was correctly applied and it took only a couple of seconds..scanstats on:V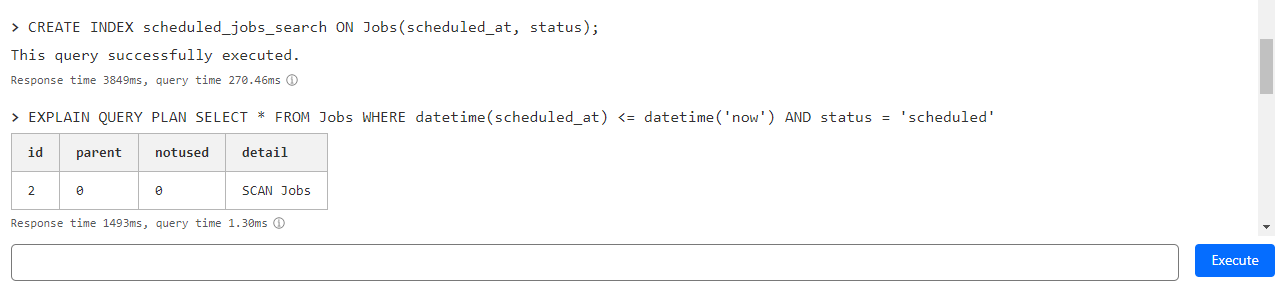 V
V K
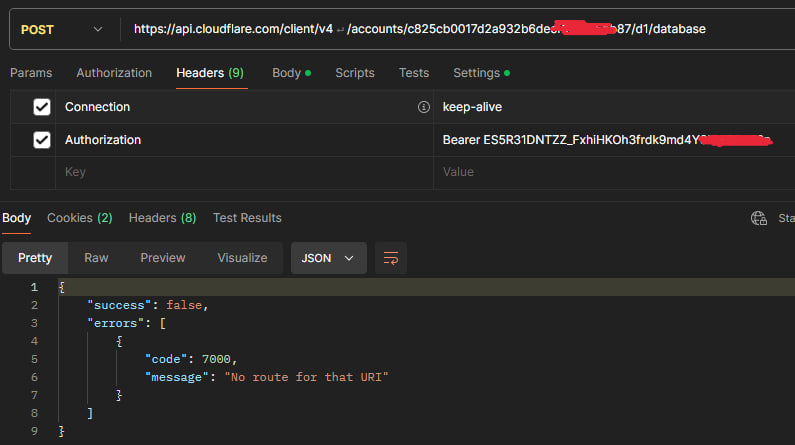
Knear "��P": syntax error at offset 0: SQLITE_ERROR [code: 7500], and yes I followed the steps in the guide and yes I tried to remove the line and checked for invisible charsA AA
AA"Durable Objects guarantee global uniqueness, so once we depend on Durable Objects, routing HTTP requests is easy: just send them to the D1 Durable Object."
AACIs the D1 database file stored in a Durable Object or vice versa? The blog states:Durable Objects are a building block. D1 runs on Durable Objects.
"Durable Objects guarantee global uniqueness, so once we depend on Durable Objects, routing HTTP requests is easy: just send them to the D1 Durable Object."
does anyone know more about the routing process? It seems similar to a DNS or load-balancing process, so how exactly do we locate where the Durable Object is?
running_in_region │ ENAM . A specific machine in a specific colo/data center runs your DB as a Durable Object, which is just a V8 Isolate/single thread. There's a community site which identifies all of the colos that are used for a specific region: https://where.durableobjects.live/region/enam. Your D1 Db will never switch regions, but may switch colo/machine (machine issues, migration, etc). I am very curious about this. In a serverless environment, is a connection pool necessary? Or can we maintain connections between (user workers running workerd) and (D1 workers running workerd)?Connection pool not necessary and with Workers not really doable either, with how often they are created/destroyed. From what they've said before in here, just a request from the user worker -> d1 worker -> d1 durable object is my understanding. Workerd is open source, you can see the implementation (to a degree, can see sqlite is accessible internally for them on d1 storage's class -> sql). There was talk about giving Durable Objects access to an Sqlite db a while ago.
My guess is that SQLite is wrapped by workerd, providing APIs (bindings) to upper-level workers, and that D1 runs as some kind of worker to provide RESTful APIs or handle other tasks.
A H
H HHH
HHH B
B FFV
FFVRows read is so big after using an index.15,932 is the total number or rows in the table - 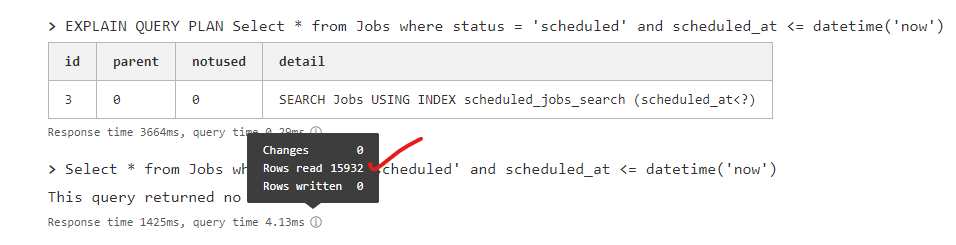 V
V SV
SV J
J JV
JVD1_ERROR: D1 is overloaded. Requests queued for too long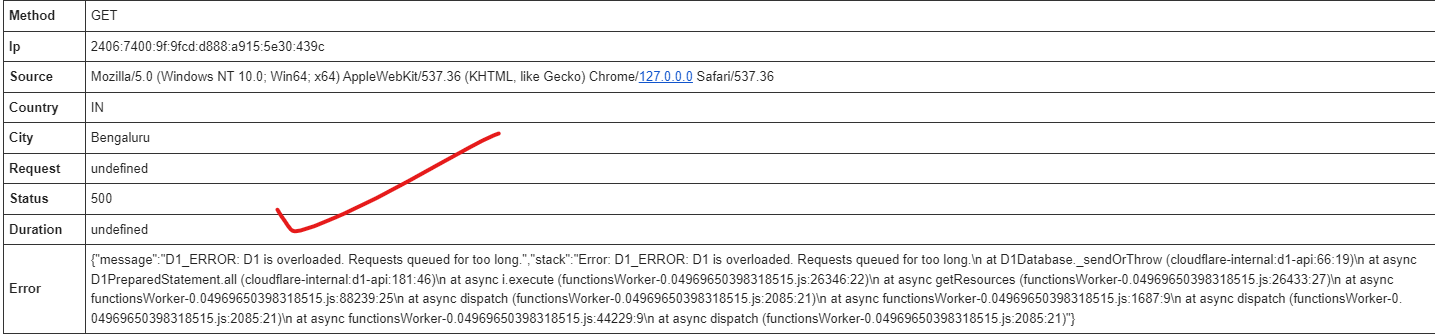
 C
C HCHHCH
HCHHCH CV
CV
 .
.
 I
I{
"name": "my-database"
}DELETEprodstid.scanstats onnear "��P": syntax error at offset 0: SQLITE_ERROR [code: 7500] running_in_region │ ENAMRows read15,932Select * from Jobs where status = 'scheduled' and scheduled_at <= datetime('now')CREATE INDEX if not exists scheduled_jobs_search ON Jobs (scheduled_at, status);CREATE INDEX if not exists scheduled_jobs_search ON Jobs (status,
scheduled_at);D1_ERROR: D1 is overloaded. Requests queued for too longnpx wrangler d1 execute prods --file $rm_rows_sql --remote
#returns
rows read: 70344030 (web dash display 70.72M)DELETE FROM products WHERE tid IN (5, 22, 34, 38, 41, 50, 57, 64, 90, 98,..)sqlite> .read del_not_shared.sql
QUERY PLAN (cycles=113272102 [100%])
`--SEARCH products USING INTEGER PRIMARY KEY (rowid=?) (cycles=26065003 [23%] loops=1 rows=1272)





