could maybe use some other proxy server (like nginx on a vps) to proxy the requests to workers but t
could maybe use some other proxy server (like nginx on a vps) to proxy the requests to workers but that'd be another step

 III
III J
J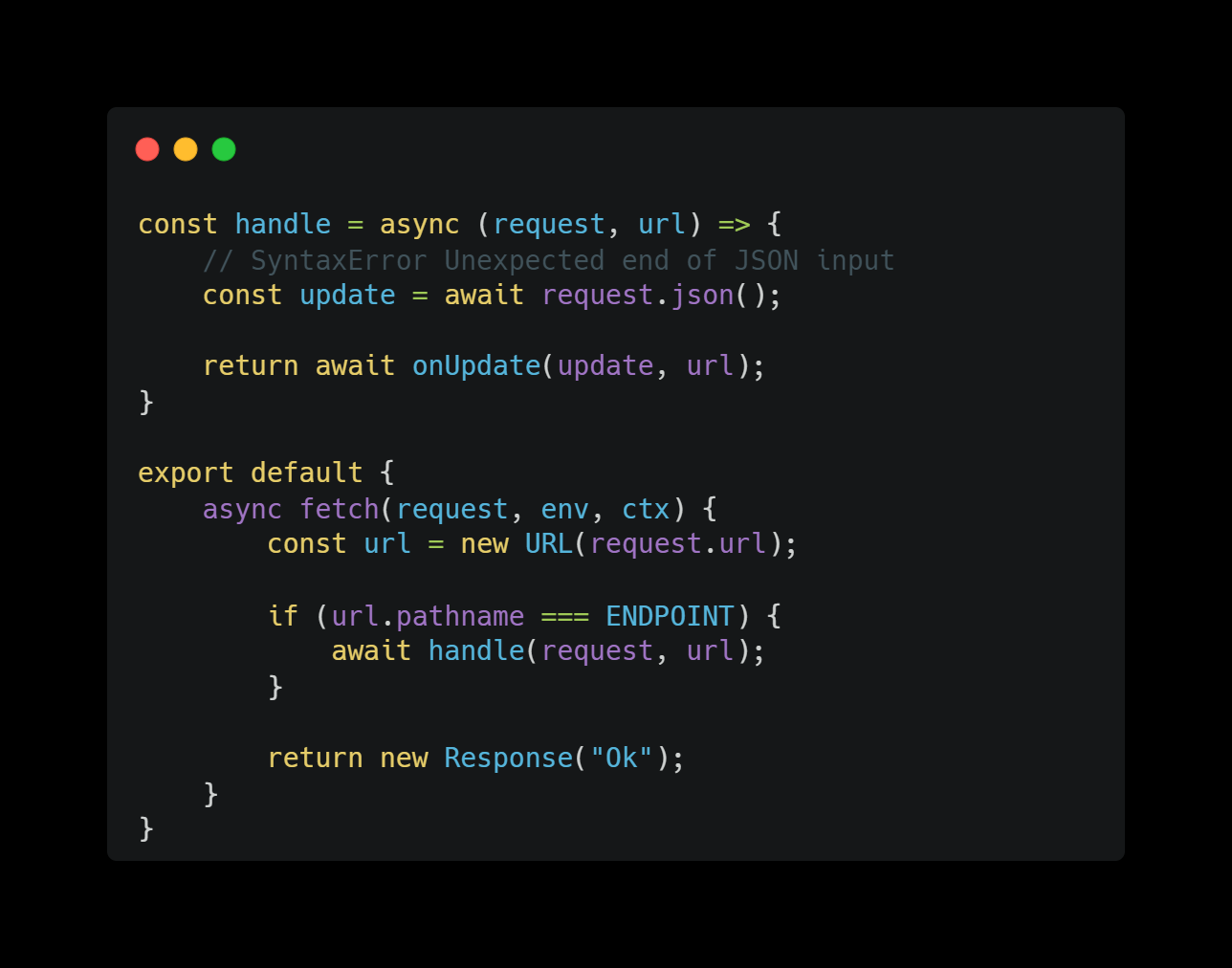
 I
I F
F H
H B
Bnoble-hashes KB
KBnoble-hashes M
M J
J
 K
K A
A S
S YK
YK C
C F
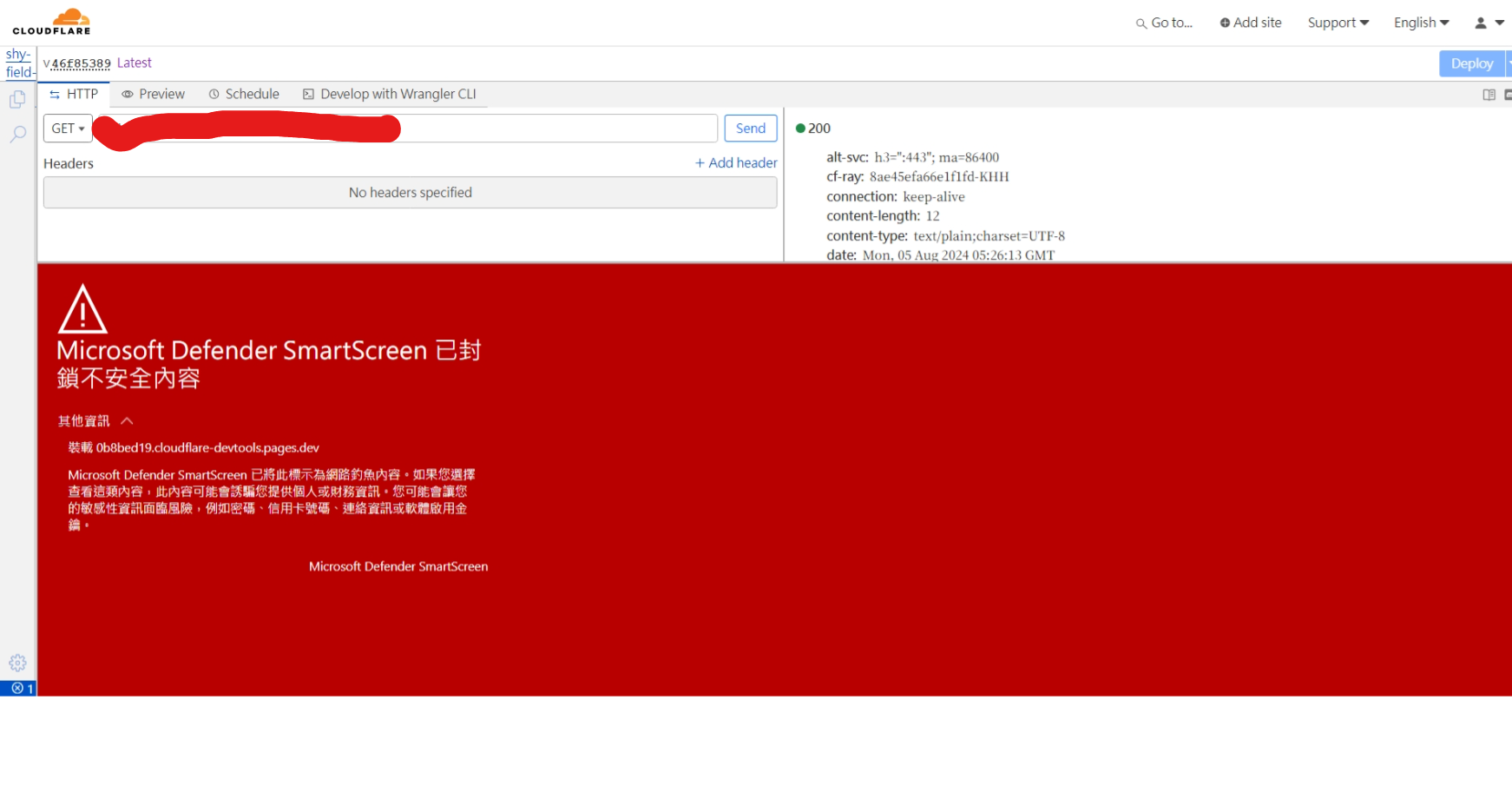
F welcome-and-rules. It creates confusion for people trying to help you and doesn't get your issue or question solved any faster.CKC
welcome-and-rules. It creates confusion for people trying to help you and doesn't get your issue or question solved any faster.CKCdoes anyone know why cloudflare worker ai llama 3.1 is 3x slower than local llama 3.1 running on rtx3080? is there no way to speed this up? 30-40 seconds for text generation is insane. I get that it is free credits but damn that is kinda slowAI team explain more in their channel, I'm no AI guy and don't know 100% their setup, but comparing local vs remote seems a bit silly. Workers AI is powered by a ton of shared GPUs, vs your one unshared gpu, and they've got lots of magic in front of it with request routing/etc to try to scale/shard requests. There's lots of different ways to run models too is my understanding, each with different quirks
 K
K D
Dload-contextenvworker/server.ts H
Hrequest.cf.colo/cdn-cgi/tracehttps://cloudflare.com/cdn-cgi/trace BBAA
BBAA I
I@clouflare/workers-types
 I
Iworkerd RRRIIR
RRRIIR 0
0 H
H KK
KKexport interface TraceMetrics {
readonly cpuTime: number;
readonly wallTime: number;
}
export interface UnsafeTraceMetrics {
fromTrace(item: TraceItem): TraceMetrics;
}