Couldnt I technically do like RANK 6 Batch 4 or 5 on 1 A6000? - Currently doing rank 2 FAST Batch 2
Couldnt I technically do like RANK 6 Batch 4 or 5 on 1 A6000? - Currently doing rank 2 FAST Batch 2 on 1 A6000, taking about 4 hrs so not too bad
 LL
LL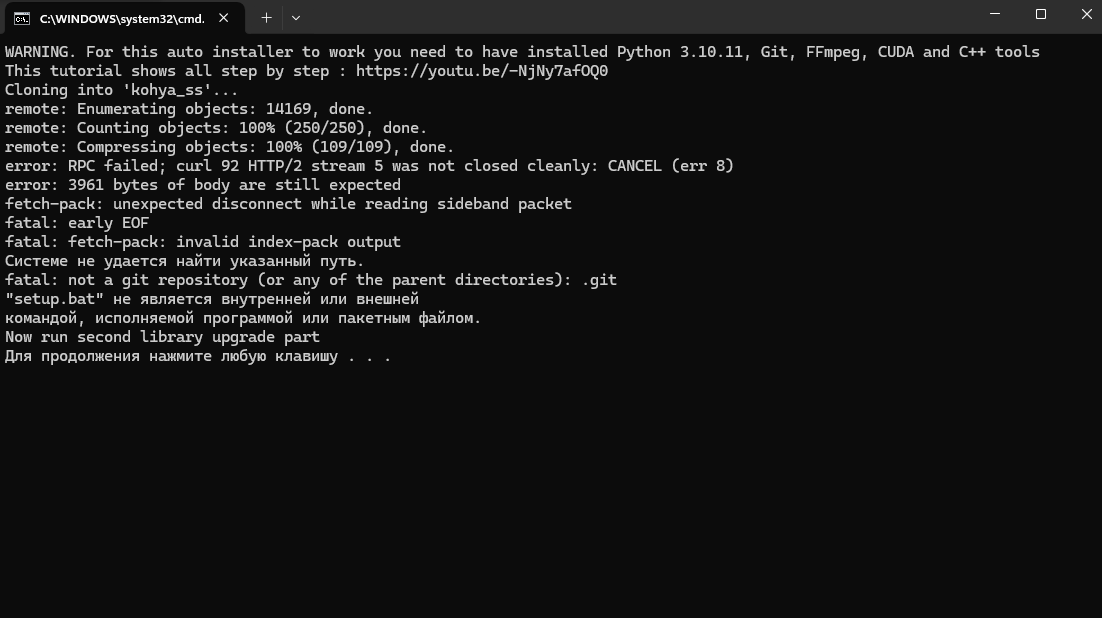
 FFF
FFF
 DFFFDFFFFFFF
DFFFDFFFFFFF F
F O
O L
L F
F FF
FF SFL
SFL L
L FFO
FFO D
D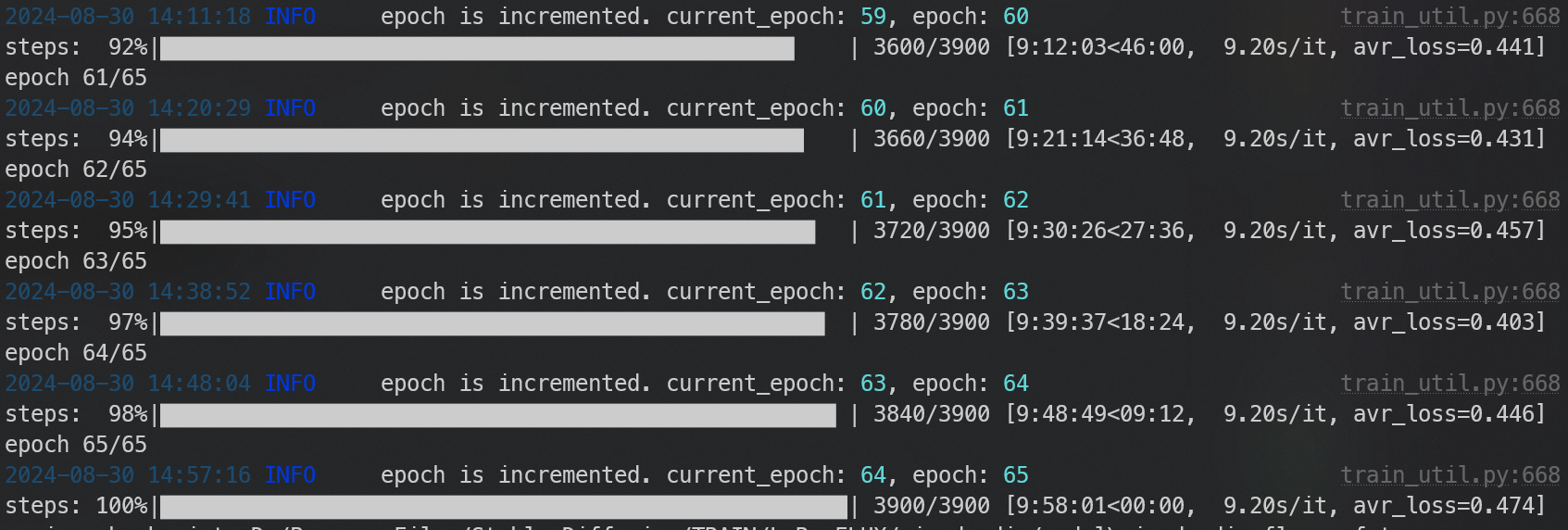 FFFFF
FFFFF MFF
MFF DFF
DFF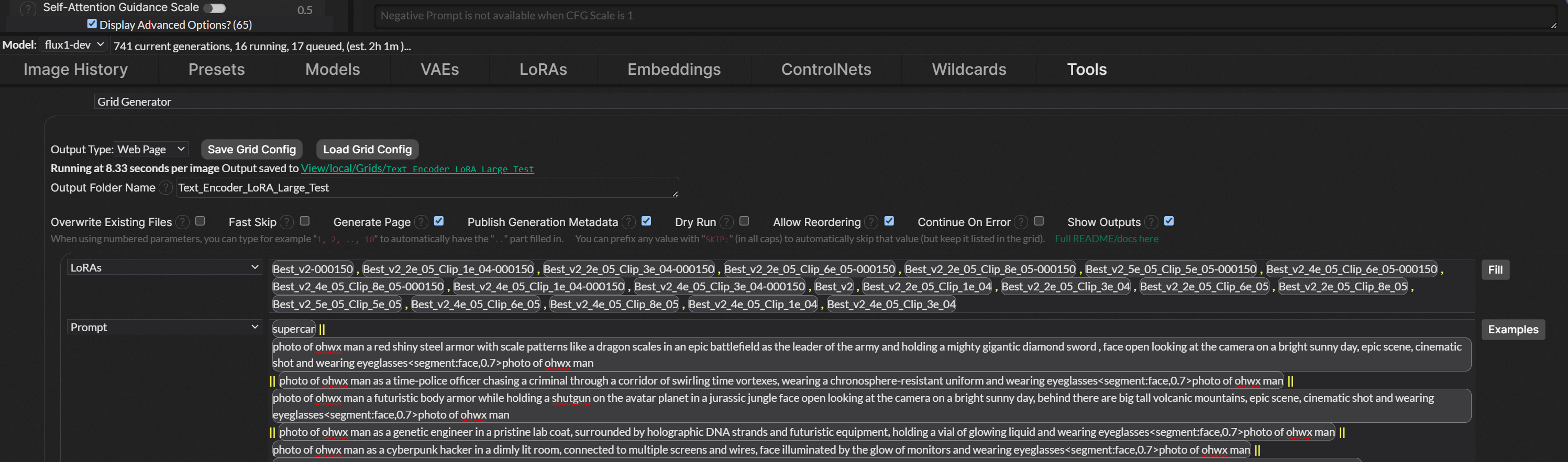 D
D GFFF
GFFF V
V





