Hello everyone. I am Dr. Furkan Gözükara. PhD Computer Engineer. SECourses is a dedicated YouTube channel for the following topics : Tech, AI, News, Science, Robotics, Singularity, ComfyUI, SwarmUI, ML, Artificial Intelligence, Humanoid Robots, Wan 2.2, FLUX, Krea, Qwen Image, VLMs, Stable Diffusion
14:35 How to use SwarmUI and FLUX on cloud services - no PC or GPU is required 14:48 How to use pre-installed SwarmUI on amazing Massed Compute 48 GB GPU for 31 cents per hour with FLUX dev FP16 model 16:05 How to download FLUX models on Massed Compute instance 17:15 FLUX models downloading speed of Massed Compute 18:19 How much time it takes on Massed Compute download all very best FP16 FLUX and T5 models
Just a quick FYI for anyone interested, here's how long it took me to do a 20img/150 epoch training session on a 4090 this morning. Used 'Rank 4 best config better colours' script
While you guys are training Flux, I'm experiencing the interesting features of PonyRealism 2.1 under Prodigy. (I see that the Flux training is still being tweaked at Kohya, so I'll wait.) It turns out that the SDXL rule of only training Unet doesn't apply here, because then the finished Lora will only look a little like the person. However, if I train normally (i.e. without the --network_train_unet_only switch), I'm already on target. By using the 'fp8 base training' switch I can weaken the strength of the model a bit, i.e. sometimes it can come in handy in achieving a more accurate Lora. Without fp8, the Lora is stronger, so the d_coef switch needs to be reduced.
seems to be a big training effort, not just remerge: "Hello everyone! An early version of RealVisXL V5.0 (560k steps) is now available on Hugging Face. The model is still in training, and the final version will be released on Hugging Face and CivitAI at the end of August. You can leave your feedback on this version in the comments below."
@Dr. Furkan Gözükara Bro, I am going to sleep now its 6am haha, training loras all night, I fixed all my machines now. Anyway, I want to Train 1000 images (a style of art) I want to train that but doing it on 1 A6000 it would take like a week right? What system you recommend and how much would it cost me on Mass compute? 4-8 GPU A6000? If its $3-5 an HR I am down to pay it. Please do recommend the correct VM to use on there and do you have a video setting one up as I only use local, never rented hardware before. Let me know thanks and gn brother! Totally worth the Patreon fee!
@Dr. Furkan Gözükara another question, if I want to use custom nodes in swarm UI, I did not see the folder, do I have to create one? Autocompletions Users-log.ldb clip_vision tensorrt Embeddings Users.ldb comfy-auto-model.yaml unet Lora VAE controlnet upscale_models Stable-Diffusion clip diffusion_models, or where are the custom node folder?
@Dr. Furkan Gözükara I've test on windows on my PC with A4000 (8go) and it worked, however as I suspected it use shared memory during the step "move text encoder to gpu" as there is not enough memory on the GPU, that's why it OOM on linux, because it can't use shared memory, then it's passed back to the cpu freeing memory and the rest is loaded that require less than 8go so during training it's stay under 8go. Is there a way to not move the text encoder to gpu, like having it calculated on cpu directly, having it use shared memory or making it use less VRAM, so it will work also on linux ?
 F
F D
D
 O
O
 L
L

 S
S

 D
D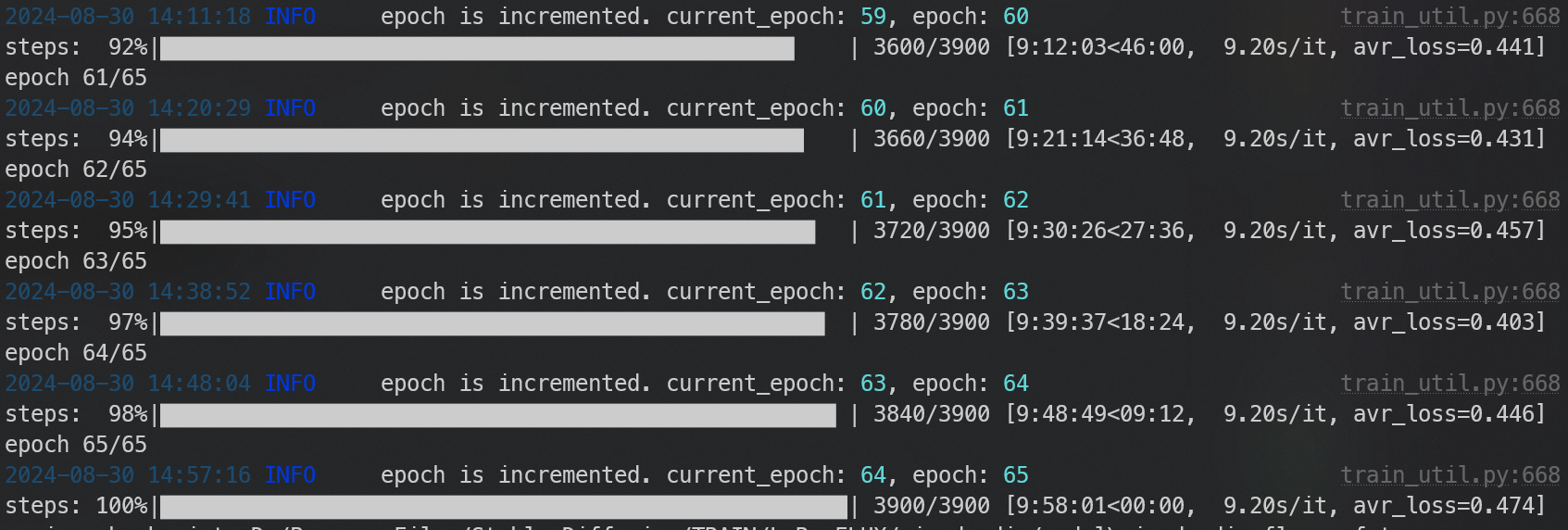
 M
M D
D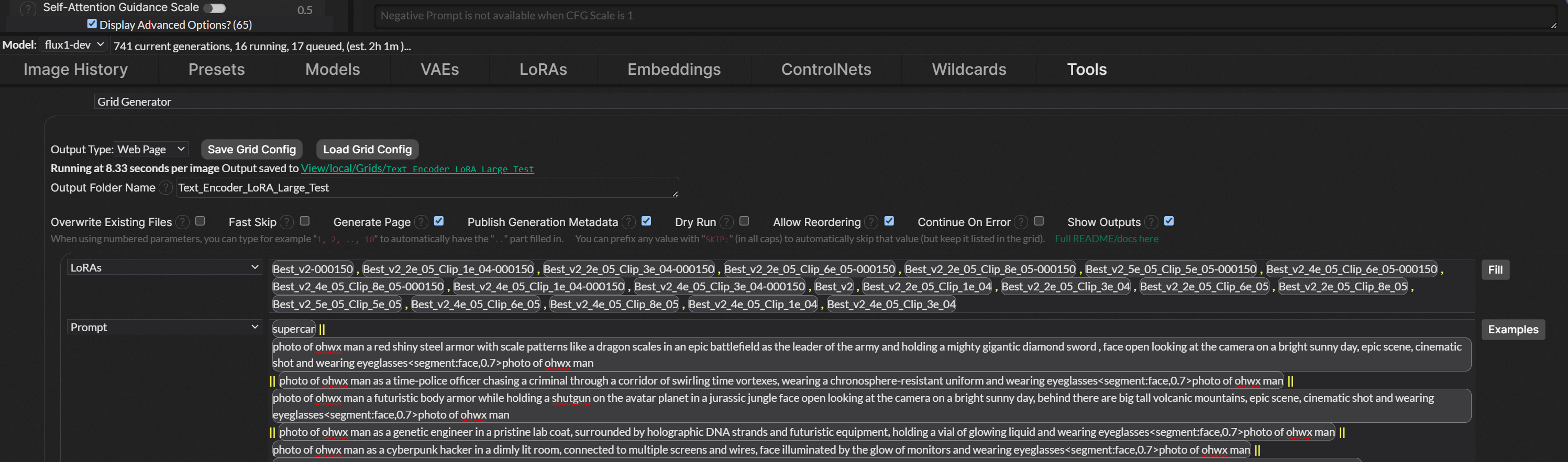
 G
G V
V M
M






