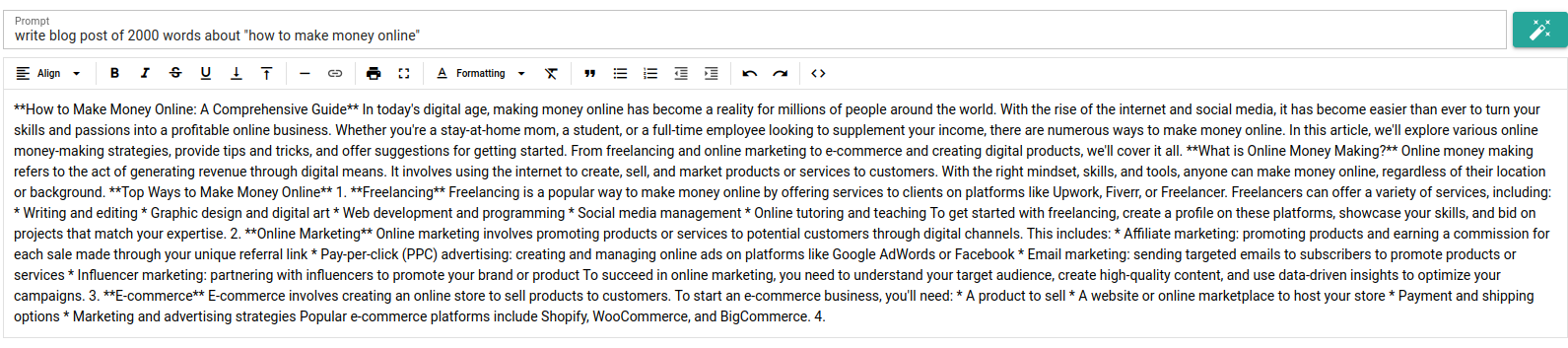
I use llama 3.1 which has 128k token context window, it might be worth the upgrade in your use case
I use llama 3.1 which has 128k token context window, it might be worth the upgrade in your use case if you are going over limits

 AA
AA SA
SA A
A AAAA
AAAA K
K A
Af55b85c8a963663b11036975203c63c0. I am using the http api to run it so i dont have a script name for thisA@cf/mistral/mistral-7b-instruct-v0.1 model because i didnt know the v0.2 model existed on cloudflare until 2 minutes ago  A
A M
M I
I R
R D
D �
�
 C
C A
A M
M
 K
K FF
FF S
S
 C
C T
T DD
DD TTK
TTK A
A
 K�
K� �
� C
C M
M LIM
LIM L
L
 S
S S
S B
B
const answer = await ctx.env.AI.run('@cf/meta/llama-3.1-8b-instruct', {
messages,
stream: true,
max_tokens:10000
});f55b85c8a963663b11036975203c63c0@cf/mistral/mistral-7b-instruct-v0.1{"errors":[{"message":"AiError: AiError: Unknown internal error","code":3028}],"success":false,"result":{},"messages":[]} if (attachment) {
const res = await fetch("https://img.xyz" + attachment).catch(() => null);
blob = await res?.arrayBuffer();
}
const response = await env.AI.run(model as any || '@cf/meta/llama-3.1-8b-instruct', {
stream: stream,
messages,
max_tokens: 512,model (meta llama)
...(blob && { image: [...new Uint8Array(blob)] }),
}