 M
M@Furkan Gözükara SECourses seems prior preservation in kohya is broken
MGitHub
Replace SD3Tokenizer with the original CLIP-L/G/T5 tokenizers.
Extend the max token length to 256 for T5XXL.
Refactor caching for latents.
Refactor caching for Text Encoder outputs
Extract arch...
Extend the max token length to 256 for T5XXL.
Refactor caching for latents.
Refactor caching for Text Encoder outputs
Extract arch...
Mbghira responded
 F
Fi think he didnt see my reply  becaue i added. but good
becaue i added. but good
becaue i added. but goodFif this get fixed nice

 D
Dah, and batch size 1!
Fkk
Fbatch size 1 is best
Fanyway for low number of images
Dwith and without
[removed]
[removed]
 C
Chilary doesn't look like hilary
 D
Dthat's the base model, I didn't train Clinton. The point is that Clinton stays as Clinton as she was
Don the left
Cshe didn't though. neither woman, in both images, look like they do on the right
Dthe trained person also looks a bit worse but that can probably be tweaked
Dyeah
Cthey don't just look worse, they look like different people
Cwhat if you try famous comic book charcters like spider man or deadpool
Dand then?
Csee how they come out with and without your anti-bleed
Dthe base model will have no problem differentiating a woman from spiderman. even woman and man is easy. on two woman or two men have this bleeding effect
Csure, and they're costumes, but the thought is - is this only affecting human faces or is it going to affect other things?
DI think you might have misunderstood the samples. Here is what you've probably meant, untrained vs. trained
 D
Dthe training of the left person obviously isn't good, but Clinton stays mostly unchanged
Dremoved above to avoid further misunderstanding
M
 D
DHe is right, it is very similar. You could have exactly the same effect by pregenerating and therefore make this possible for full finetune with no additional vram, too. You'd have to synchronize timesteps and seed(!) between the pregenerated data and the training though, which is the difference to the current "Prior Preservation" feature. I did implement this for full finetune also, but without pregeneration so it needs a lot of VRAM for two full models, the student and the trainer model. Feel free to forward my contact.
DOn the second comment though, it's not only activation. In this sample, dreambooth-training, Clinton would look like the left person without regularization.
Dthe left person in the right sample, I mean
Fmy training completed now will test
FOneTrainer strategy looks like failed for me
 F
Fi will compare quality lets see if any difference
Dnice hair though
FF D
Dtry a simple prompt first. if even "man" looks like you, something went wrong. That always worked for me.
Fok testing
Fstudio photo of a man wearing an amazing suit
Fye all man is me
Fweird
F F
Fthis change didnt make any impact
Fcode is accurately put
F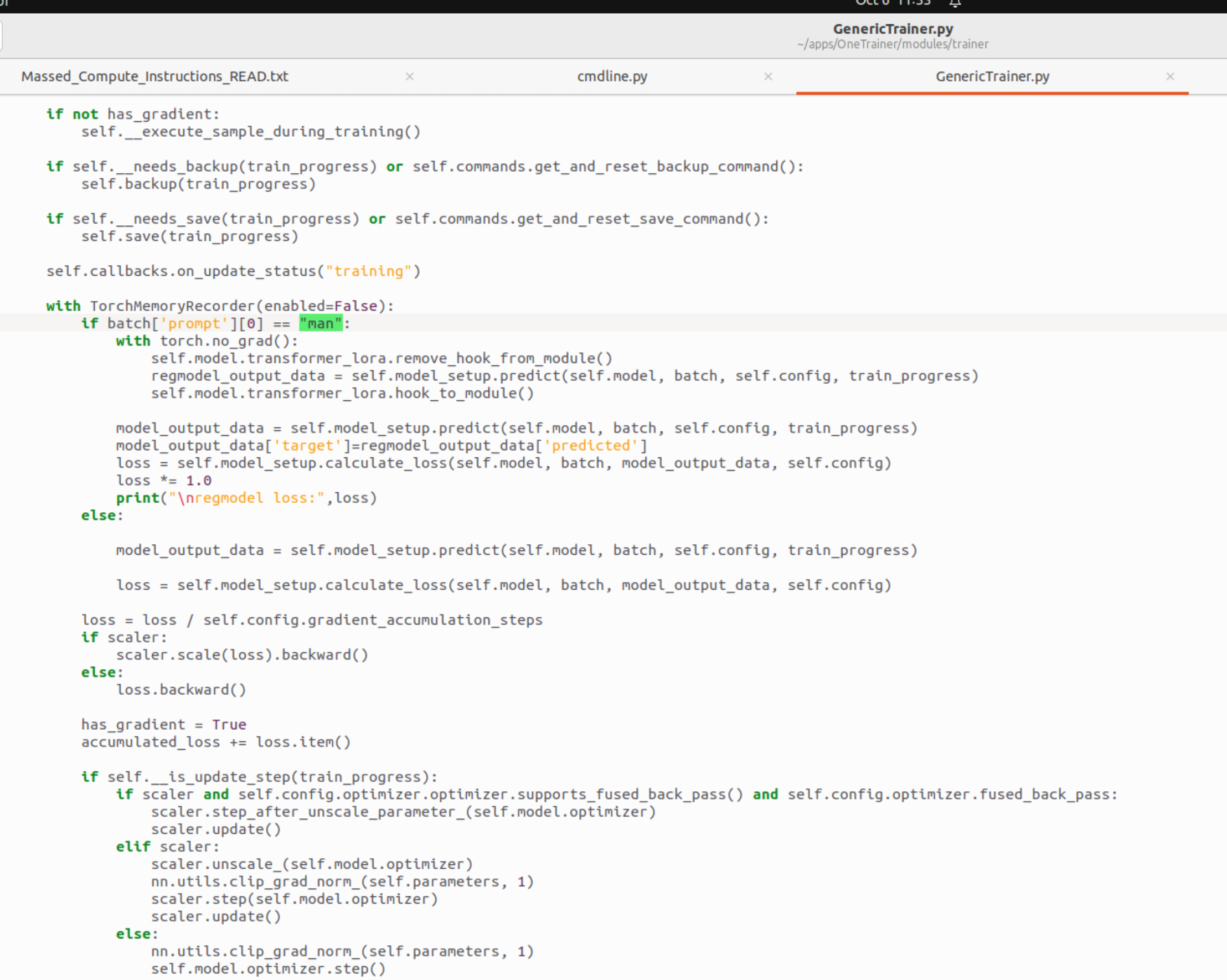 D
Dsomething went wrong. do you have the output of the training? was the debug print() there?
Fwhat debug print
Dthe print("regmodel loss...
Fi dint make such change
Fi used your file :d
Fi see that