Sorry, what do you mean latest version? I'm V44 files from a day ago.
Sorry, what do you mean latest version? I'm V44 files from a day ago.
 C
C FF
FF SFFFSFFSSSFFS
SFFFSFFSSSFFS RRFFRRFFFS
RRFFRRFFFS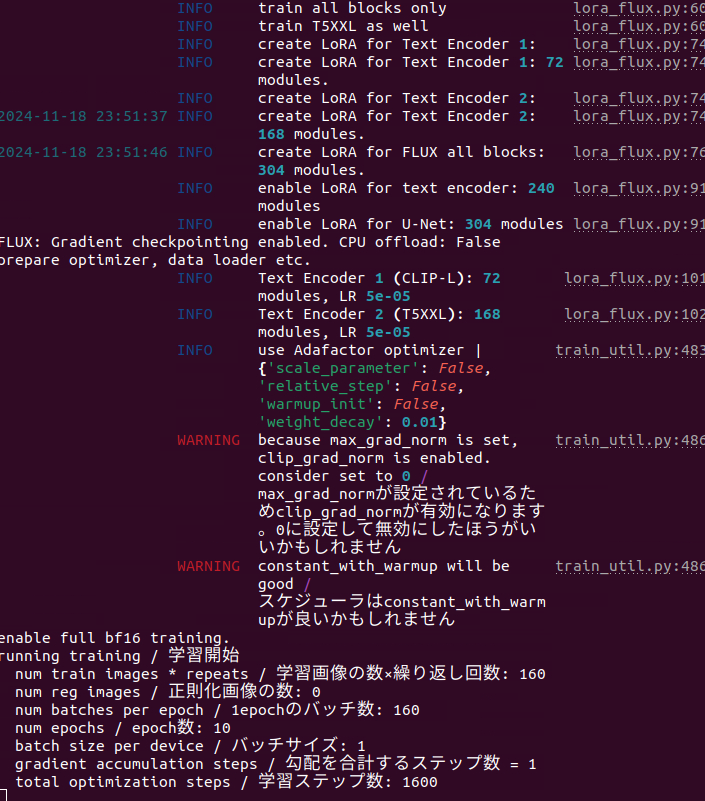 FFS
FFS . Had to override the default =0.
. Had to override the default =0. F
F
 �
� Got my answer quickly here. Thanks� Appreciate this community so much, I learn something every day!FFR
Got my answer quickly here. Thanks� Appreciate this community so much, I learn something every day!FFR WW�FF
WW�FF DFFDM
DFFDM D
D XF
XF

