does `--network_train_unet_only` affect to the quality of the lora?
does
--network_train_unet_only--network_train_unet_only X
X FFF
FFF ZFF
ZFF �
�
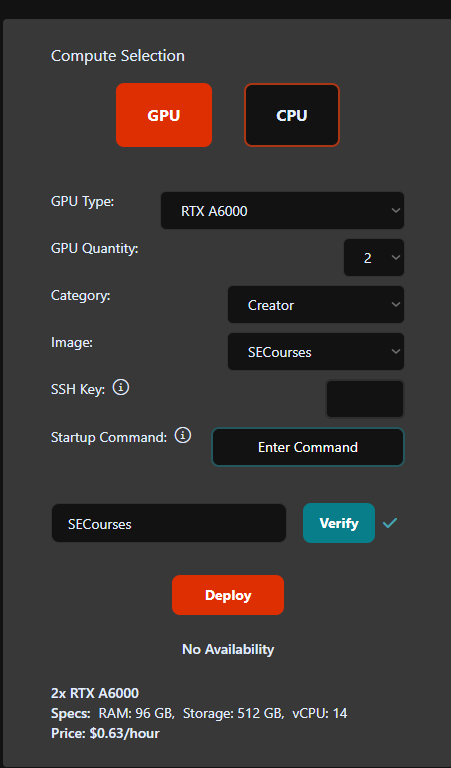
 my current solution is inpaintinf my face with segment as shown, but face does change when using the loraFZFFZFFZZZ
my current solution is inpaintinf my face with segment as shown, but face does change when using the loraFZFFZFFZZZ
 N
N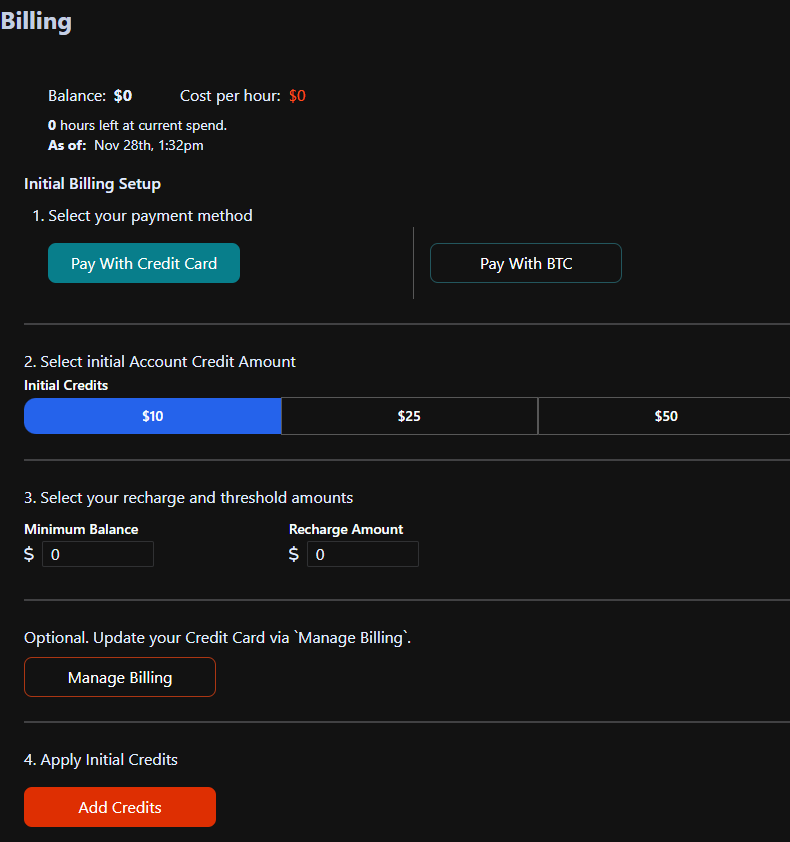
 N
N NNNNN
NNNNN K
K KFFFFFFFW
KFFFFFFFW G���
G��� ��
�� �FFFFFFKF
�FFFFFFKF




