Hello everyone. I am Dr. Furkan Gözükara. PhD Computer Engineer. SECourses is a dedicated YouTube channel for the following topics : Tech, AI, News, Science, Robotics, Singularity, ComfyUI, SwarmUI, ML, Artificial Intelligence, Humanoid Robots, Wan 2.2, FLUX, Krea, Qwen Image, VLMs, Stable Diffusion
so fastest would be batch 7 and do reduced size of epoch?
In patreon was written:
Fine Tuning / DreamBooth: 256 Training Images & Batch Size is 7 : Best Epoch is 40 = 256 x 40 / 7 = 1480 steps : Duration is 11 hours 56 minutes = around 4 USD cost
Zonos-v0.1 is a leading open-weight text-to-speech model trained on more than 200k hours of varied multilingual speech, delivering expressiveness and quality on par with—or even surpassing—top TTS ...
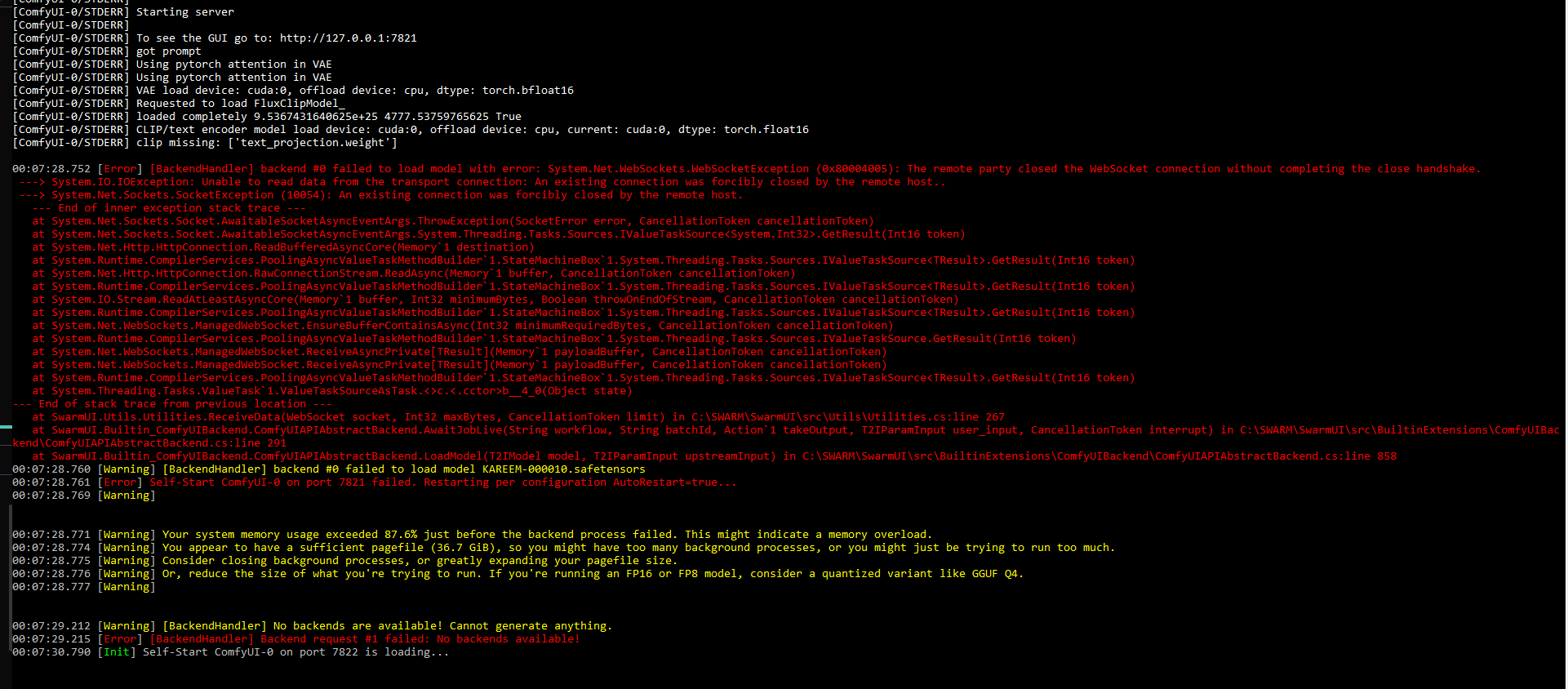
no CLIP/text encoder weights in checkpoint, the text encoder model will not be loaded. CLIP/text encoder model load device: cuda:0, offload device: cpu, current: cpu, dtype: torch.float16 clip missing: ['text_projection.weight']
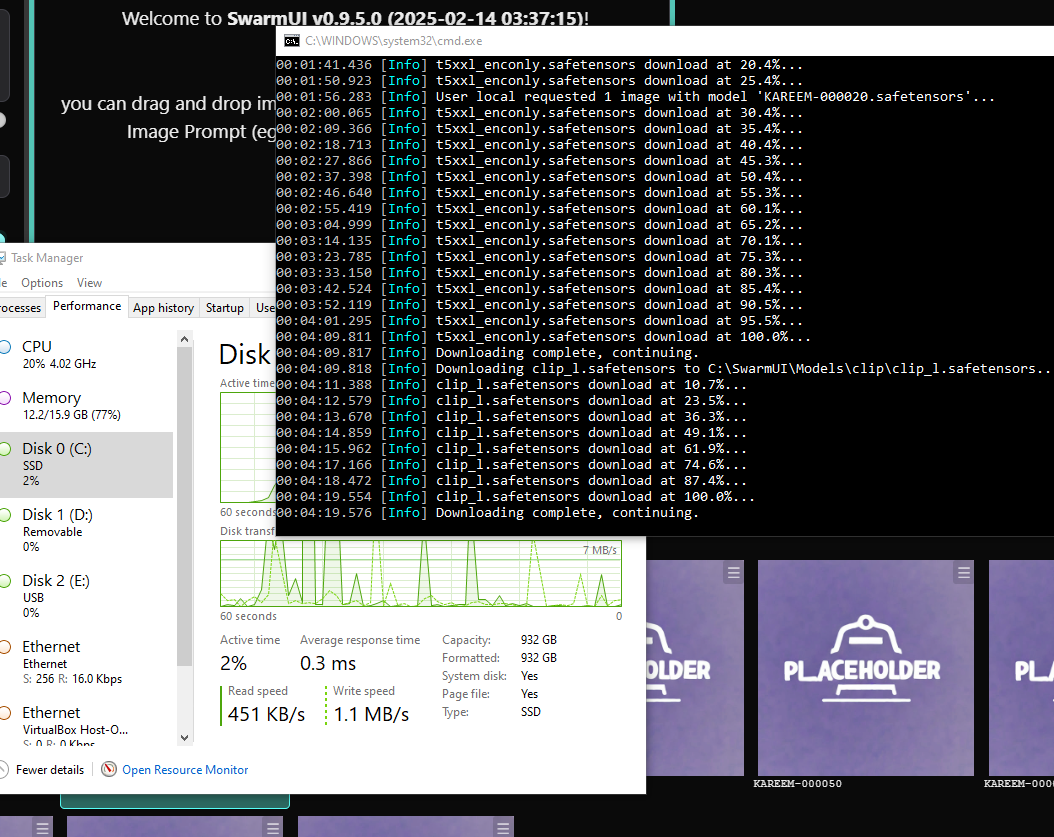
Go on the left side of swarm on the search bar "Filter parameters" and search for the keyword preview. There's a tik option on the Swarm Internal tab that reads "No previews" make sure to uncheck it
 F
F V
V



 A
A
 N
N
 J
J T
T M
M C
C T
T
 K
K K
K
 N
N











