this is most powerful way of training at the moment
this is most powerful way of training at the moment
 U
U FFFFFFF
FFFFFFF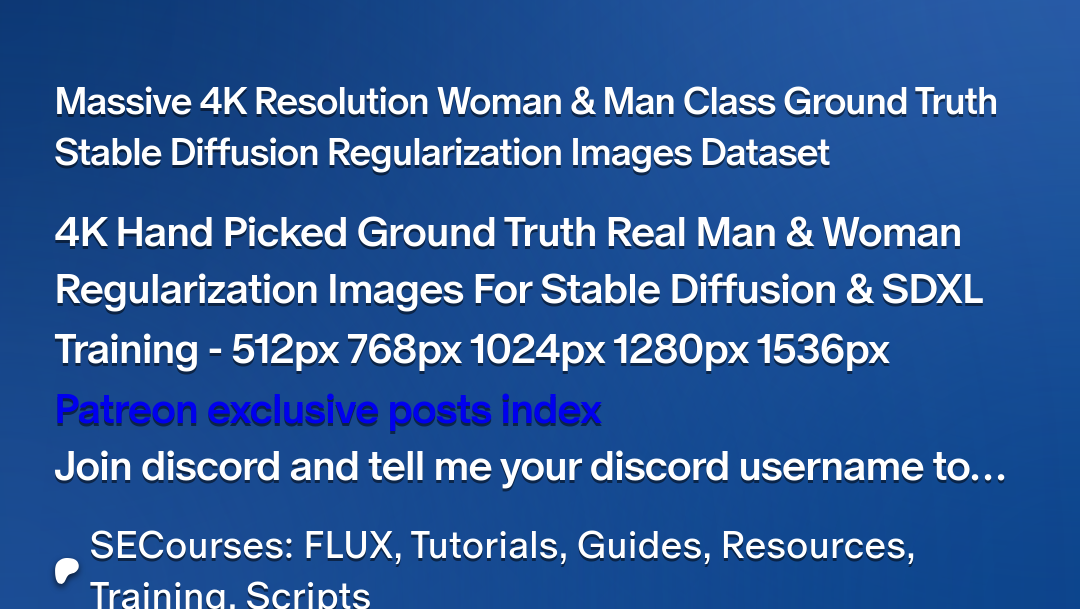 F
F F
F
 U
U MFFFMFMMF
MFFFMFMMF AFFFF
AFFFF
 EEM
EEM TTTMMFFF
TTTMMFFF FFFF
FFFF MF
MF 1176 images. I think we gonna have a better workflow than what we have with using more VRAM and more training time.
1176 images. I think we gonna have a better workflow than what we have with using more VRAM and more training time.
 R
R Diffusers: State-of-the-art diffusion models for image, video, and audio generation in PyTorch and FLAX. - huggingface/diffusers
Diffusers: State-of-the-art diffusion models for image, video, and audio generation in PyTorch and FLAX. - huggingface/diffusers
 MFF
MFF GFFF
GFFF





